
Q-learning is expensive because it takes many experienced tuples to converge. Creating experienced tuples means taking a real step to execute a trade, in order to gather information.
To address this problem, Rich Sutton invented Dyna.
Time: 00:00:37

Q learning is model-free meaning that it does not rely on T or R.
Dyna-Q is an algorithm developed by Rich Sutton intended to speed up learning or model convergence for Q learning.
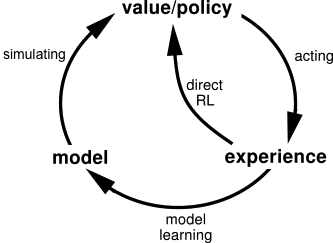
Dyna is a blend of model-free and model-based methods.
s, take action a, and then observe our new state s' and rewardr`, and then update Q table with this experience tubal and repeat.When updating our model we want to do is find new values for T and R.
The point where we update our model includes T, our reward function R.
s, a, so our state and action are chosen totally at random.s' by looking at T.r by looking at big R or R table.Now we have a complete experience tuple to update our Q table using that.
So, the Q table update is our final step and this is really all there is to die in a queue.
Time: 00:04:14

Note the methods are Balch version, might not be Rich Sutton version.
Learning T.
T[s,a,s'] represents the probability that if we are in the state s, take action a we will end up in state s'.
To learn a model of T: just observe how these transitions occur.
Time: 00:01:34
$T[s,a,s'] = \frac{Tc[s,a,s']}{\sum\limits{i}T_c[s,a,i]} $
Time: 00:01:03

The last step here is how do we learn a model for R?
When we execute an action a in state s, we get an immediate reward, r.
R[s, a] are expected reward if we're in state s and we execute action a.
r is what we get in an experience tuple.r is the new estimate.
That's a simple way to build a model of R from observations of interactions with the real world.Time: 00:01:39
how Dyna-Q works.

Dyna-Q adds three new components based on regular Q-Learning
We can repeat 2-3 many times. ~100 or 200 here, then return back up to the top and continue our interaction with the real world.
The reason Dyna-Q is useful: use cheap hallucinations to replace real-world interaction (which is expensive)
And when we iterate doing many of them, we update our Q table much more quickly.
Time: 00:00:57
Total Time: 00:10:41
The Dyna architecture consists of a combination of:
Sutton and Barto. Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 1998. [web]
Richard S. Sutton. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In Proceedings of the Seventh International Conference on Machine Learning, Austin, TX, 1990. [pdf]
Sutton and Barto. Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 1998. [web]
RL course by David Silver (videos, slides)
2019-03-31 初稿