本文讲述了如何使用Docker快速部署单节点Hadoop,Hadoop版本为2.7;
源代码:
<br/>
<!--more-->直接在Shell执行:
docker run -dit \
--name hadoop \
--privileged=true \
-p 50070:50070 \
-p 8088:8088 \
sequenceiq/hadoop-docker:2.7.0 /etc/bootstrap.sh -bash
<font color="#f00">**注1:如果不添加`-dit ... -bash`,则容器会在启动结束后直接退出!**</font>
<font color="#f00">**注2:仅仅暴露了50070和8088两个Web界面端口,其他端口可根据需求暴露:**</font>
bash-4.1# netstat -tunlp Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 138/java tcp 0 0 0.0.0.0:45399 0.0.0.0:* LISTEN 737/java tcp 0 0 0.0.0.0:8088 0.0.0.0:* LISTEN 606/java tcp 0 0 0.0.0.0:13562 0.0.0.0:* LISTEN 737/java tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 264/java tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 264/java tcp 0 0 0.0.0.0:8030 0.0.0.0:* LISTEN 606/java tcp 0 0 0.0.0.0:8031 0.0.0.0:* LISTEN 606/java tcp 0 0 0.0.0.0:8032 0.0.0.0:* LISTEN 606/java tcp 0 0 0.0.0.0:8033 0.0.0.0:* LISTEN 606/java tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 264/java tcp 0 0 127.0.0.1:36772 0.0.0.0:* LISTEN 264/java tcp 0 0 0.0.0.0:8040 0.0.0.0:* LISTEN 737/java tcp 0 0 172.17.0.3:9000 0.0.0.0:* LISTEN 138/java tcp 0 0 0.0.0.0:8042 0.0.0.0:* LISTEN 737/java tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 436/java tcp 0 0 0.0.0.0:2122 0.0.0.0:* LISTEN 28/sshd tcp 0 0 :::2122 :::* LISTEN 28/sshd
<br/>
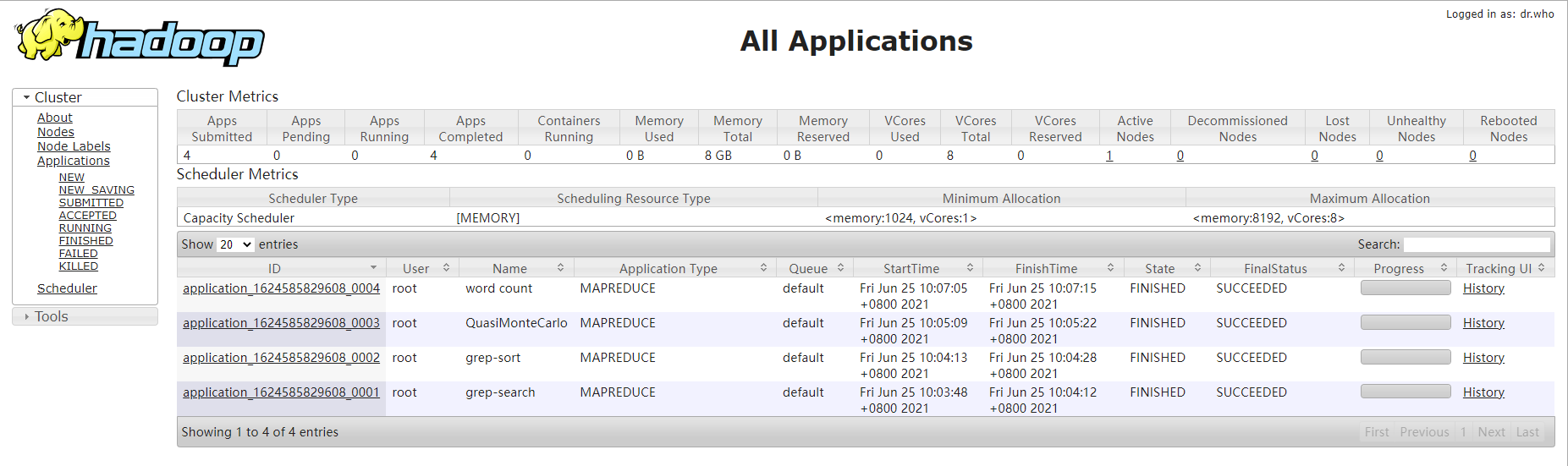
查看集群状态:http://server:8088/cluster
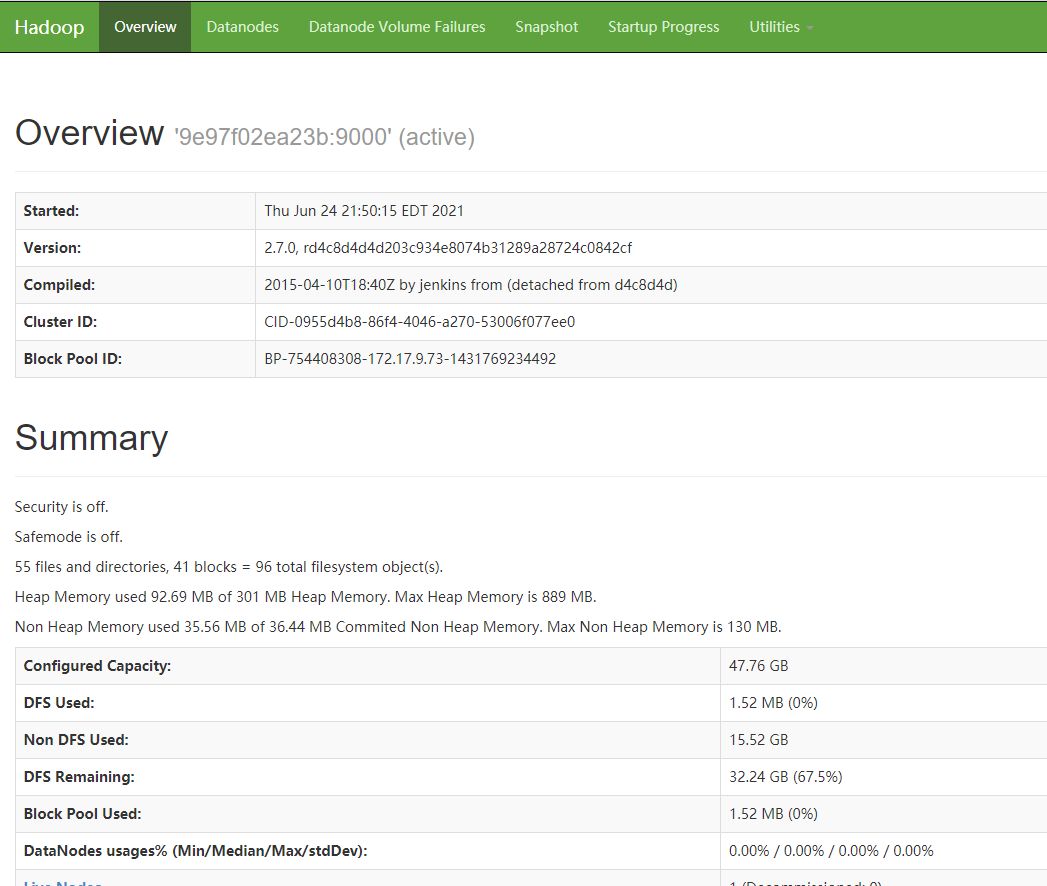
浏览HDFS文件:http://server:50070/explorer.html
<br/>
进入容器:
$ docker exec -it hadoop /bin/bash
bash-4.1# cd $HADOOP_PREFIX
bash-4.1# pwd
/usr/local/hadoop
提交作业:
bash-4.1# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
21/06/24 22:03:46 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
21/06/24 22:03:47 INFO input.FileInputFormat: Total input paths to process : 31
21/06/24 22:03:47 INFO mapreduce.JobSubmitter: number of splits:31
21/06/24 22:03:48 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1624585829608_0001
21/06/24 22:03:48 INFO impl.YarnClientImpl: Submitted application application_1624585829608_0001
21/06/24 22:03:48 INFO mapreduce.Job: The url to track the job: http://9e97f02ea23b:8088/proxy/application_1624585829608_0001/
21/06/24 22:03:48 INFO mapreduce.Job: Running job: job_1624585829608_0001
21/06/24 22:03:53 INFO mapreduce.Job: Job job_1624585829608_0001 running in uber mode : false
21/06/24 22:03:53 INFO mapreduce.Job: map 0% reduce 0%
21/06/24 22:03:57 INFO mapreduce.Job: map 16% reduce 0%
21/06/24 22:03:58 INFO mapreduce.Job: map 19% reduce 0%
21/06/24 22:04:00 INFO mapreduce.Job: map 35% reduce 0%
21/06/24 22:04:01 INFO mapreduce.Job: map 39% reduce 0%
21/06/24 22:04:03 INFO mapreduce.Job: map 48% reduce 0%
21/06/24 22:04:04 INFO mapreduce.Job: map 55% reduce 0%
21/06/24 22:04:06 INFO mapreduce.Job: map 65% reduce 0%
……
检查MR输出:
bash-4.1# bin/hdfs dfs -cat output/*
6 dfs.audit.logger
4 dfs.class
3 dfs.server.namenode.
2 dfs.period
2 dfs.audit.log.maxfilesize
2 dfs.audit.log.maxbackupindex
1 dfsmetrics.log
1 dfsadmin
1 dfs.servers
1 dfs.replication
1 dfs.file
<br/>
bash-4.1# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar pi 11 24
Number of Maps = 11
Samples per Map = 24
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Wrote input for Map #10
Starting Job
21/06/24 22:05:09 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
21/06/24 22:05:09 INFO input.FileInputFormat: Total input paths to process : 11
……
Job Finished in 14.773 seconds
Estimated value of Pi is 3.1363636363636363636
<br/>
数据准备:
bash-4.1# cat > word.txt <<EOF
> hadoop java fink
> mysql hadoop hive
> spark hive hadoop
> flink hadoop
> EOF
bash-4.1# cat word.txt
hadoop java fink
mysql hadoop hive
spark hive hadoop
flink hadoop
创建HDFS输入目录:
bin/hadoop fs -mkdir -p /wordcount/input
上传数据:
bash-4.1# bin/hadoop fs -put word.txt /wordcount/input
bash-4.1# bin/hadoop fs -cat /wordcount/input/word.txt
hadoop java fink
mysql hadoop hive
spark hive hadoop
flink hadoop
启动作业:
bash-4.1# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar wordcount /wordcount/input /wordcount/output
21/06/24 22:07:04 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
21/06/24 22:07:05 INFO input.FileInputFormat: Total input paths to process : 1
21/06/24 22:07:05 INFO mapreduce.JobSubmitter: number of splits:1
21/06/24 22:07:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1624585829608_0004
21/06/24 22:07:05 INFO impl.YarnClientImpl: Submitted application application_1624585829608_0004
21/06/24 22:07:05 INFO mapreduce.Job: The url to track the job: http://9e97f02ea23b:8088/proxy/application_1624585829608_0004/
……
查看输出内容:
bash-4.1# bin/hadoop fs -cat /wordcount/output/part-r-00000
fink 1
flink 1
hadoop 4
hive 2
java 1
mysql 1
spark 1
<br/>
源代码:
<br/>