
如何激怒一个Rust爱好者?让他用Rust实现一个双向链表即可!
总所周知,Rust中是不能同时存在两个可变引用的,所以在Rust中实现双向链表就会变得非常反人类(因为需要同时存在前后节点同时指向对方的情况);
同时,双向链表也引入了循环引用的问题,这也是导致内存难以释放的一个场景;
没想到一个简简单单的双向链表居然涉及如此之多的问题!
本文就使用Unsafe Rust实现了双向链表;
源代码:
<br/>
<!--more-->在阅读本文之前,请确保你有一定的Rust基础,至少:
对于链表的实现,在Rust中有多种方式,比如:
Box 实现(由于 Box 本身的限制,基本只能实现单向链表);Rc + RefCell 实现(由于 RefCell 的限制,迭代器无法很好的实现);Unsafe 实现;对于链表的实现,甚至专门有一本赫赫有名的书:
推荐大家先阅读并跟着这本书实现其中的几种链表实现,再来阅读本文,相信你会有更多的收获!
这里也提供我学习《Learn Rust With Entirely Too Many Linked Lists》这本书的源代码:
最后,本文内容超过 2w 字,希望你能静下心来通篇阅读,相信你一定会有所收获!
那么,废话不多说,下面来使用 Unsafe Rust 实现一个双向链表吧!
<br/>
链表的节点定义、构造函数和Into辅助函数如下:
struct Node<T> {
val: T,
next: Option<NonNull<Node<T>>>,
prev: Option<NonNull<Node<T>>>,
}
impl<T> Node<T> {
fn new(val: T) -> Node<T> {
Node {
val,
prev: None,
next: None,
}
}
fn into_val(self: Box<Self>) -> T {
self.val
}
}
我知道你有很多的疑问,让我们一步一步来看;
首先,为了链表的通用性,泛型是必不可少的,因此 Node 中实际存放的值 val 为泛型 T 类型;
<font color="#f00">**注:此处 val 为泛型 T 类型,而非 `Option<T>` 类型;**</font>
<font color="#f00">**这也说明如果存在这个 Node,则该Node中必定是有值的,保证不会出现 Node 存在而 val 为 null 的情况;**</font>
<font color="#f00">**(取而代之,如果 val 的值为空,则这个 Node 就应该为 `None`)**</font>
<br/>
接下来,来看表示前一节点和后一节点的 next 和 prev 属性;
next 和 prev 的类型为:Option<NonNull<Node<T>>>,我们一层一层的来分析:
首先:Option<T> 表示该节点为空,即不存在前置节点(整个链表为空时)、或不存在后置节点(链表的尾节点);
接下来,NonNull 为 Rust 中的一个内置类型,其是裸指针 *mut T 的一个包装,但是和 *mut T 裸指针的区别在于:
NonNull类型即使从未解引用指针,指针也必须始终为非 null;这样一来,枚举就可以将此值用作判别(Option<NonNull<T>> 与 *mut T 具有相同的大小); 但是,如果指针未解引用,它可能仍会悬垂!*mut T 不同, NonNull<T> 可以作为 T 的协变;这样就可以在构建协变类型时使用 NonNull<T>,但是如果在实际上不应该协变的类型中使用,则会带来风险;上述内容,摘自
NonNull官方文档:
上面说的云里雾里的,那到底裸指针 *mut T 和 NonNull 有什么区别呢?
<font color="#f00">**简单来说就是 `NonNull` 提供了比 `*mut T` 更多的内容:支持协变类型、空指针优化,并且可以保证指针非空;**</font>
指针非空和空指针优化很好理解,但是这里需要补充一些关于变量类型协变的内容(已经对协变比较属性的可以直接跳过);
<br/>
要讲 Rust 中的协变,首先要从面向对象说起了(很多编程语言都存在协变,如C#);
在 OOP 中,协变很好理解:
例如,如果 Cat 是 Animal 的子类型,那么Cat类型的表达式可用于任何出现Animal类型表达式的地方;
可以说:
<font color="#f00">**当我们基于 `Animal` 定义 `Cat` 的时候,`Cat` 相对于 `Animal` 的[内涵增加了,而外延收缩](https://www.zhihu.com/question/22267682/answer/28974249)了;**</font>
<font color="#f00">**并且可以认为:我们至少可以说一个猫是一个动物。所以猫是动物的子类型,记作 `Cat: Animal`;**</font>
因为猫至少是一个动物,那么对于所有需要任何动物的地方,我都可以给一只猫:
function schrödinger(sample: Animal) -> bool { ... } let cat = new Cat(); const alive = schrödinger(cat);也就是说:当
T: U的时候,任何需要形式参数a: U的函数,我们都能给一个实际参数a: T;<font color="#f00">**这是因为:子类型至少可以被当作它的超类型;**</font>
所谓的 变型(variance) 是指:如何根据组成类型之间的子类型关系,来确定更复杂的类型之间(例如 Cat 数组之于Animal数组,返回值为 Cat 的函数之于返回值为 Animal 的函数...等等)的子类型关系;
当我们用类型构造出更复杂的类型,原本类型的子类型性质可能被保持、反转、或忽略,取决于类型构造器的变型性质;
类型构造器就是一些带有泛型/模板参数的类型;当填满了参数,才会成为一个实际的类型;
比如:很简单的「笼子」就是
Cage<T>,其中T就是类型参数;还有容器类型,比如
List<T>;
现在回顾一下,我们现在知道一些类型之间的关系,也即是说我们知道 Cat 是 Animal 的子类型;那么对于任意的(一元)类型构造器 M, M<Cat> 和 M<Animal> 可能会有什么关系呢?(Wiki)
M<Cat>: M<Animal> 它们维持内部参数的关系不变;M<Animal>: M<Cat> 它们的关系被反转了;直觉上来说,只要有协变就够了:
薛定谔想要一个笼子,里面装着一种动物,他不关心是什么动物(Cage<Animal>),你给薛定谔一只装着猫的笼子(Cage<Cat>),薛定谔把这个猫当作一种动物做实验;
也就是说在需要 Cage<Animal> 的地方都可以给一个 Cage<Cat> ;
然而,这显然是不对的!
考虑这样一个情况:
let cage: Cage<Cat> = new Cage();
function capture(x: Cage<Animal>) {
x.inner = new Dog();
}
capture(cat);
因为协变规则,对 capture 来说笼子是: Cage<Animal>,往笼子里塞一个狗,完全没问题;
但是对于调用者来说,笼子的类型还是 Cage<Cat>,这就破坏了类型安全:你接下来的代码期望这是装猫的笼子,其实里面装了一个狗!
<font color="#f00">**所以:如果一个容器是只读的,才能协变,不然很容易就能把一些特殊的容器协变到更一般的容器,再往里面塞进不应该塞的类型;**</font>
再考虑 Cage<T> 对 T 逆变的情况:Cage<Animal>: Cage<Dog>;
也就是说当函数需要 Cage<Dog>的时候,总能传给函数一个 Cage<Animal>,函数当作 Cage<Dog> 来处理!
一般来说这很荒谬,Cage<Animal> 里面的动物可能是一只猫,强行当作一个狗来处理肯定会爆炸;
但是对于上面的 capture 函数是有意义的,它不关心笼子里有什么,只往里面塞一个准备好的狗,也就是说:<font color="#f00">**对于只写的类型可以用逆变;**</font>
<font color="#f00">**那么对于可读又可写的类型,当然就是不变了:我们不能做出任何假定,不然有可能爆炸;****</font>
<br/>
还有一种特殊的类型,规则有点奇异,那就是函数类型:考虑一元函数,按照函数的箭头记法,把函数类型记作 T -> U,其中 T 是逆变的而 U 是协变的;
返回值是协变的很好理解:我需要函数 F 最终返回一只动物,那么最终返回一只猫的函数是可接受的;(可以不断地扩大类型域)
当参数是逆变可能有点奇怪了:考虑需要计算猫的年龄的情况: Cat -> Age:
给一个通用的,可以计算所有动物的年龄的函数 Animal -> Age 来代替也是很好的:Animal -> Age 的定义域 Animal 中那些 Cat 以外的值被截取掉了(我们只会传 Cat),就变成很棒的 Cat -> Age;
所以任何时候,对需要一个一元函数 T: U, T -> V 的情况,它的参数 T 可以用 U 来代替,只需要简单地无视 U 类型除 T 以外的取值就行了;
下面一段话摘自维基百科,说的是同一个意思:
<font color="#f00">**某些编程语言需要指明什么时候一个函数类型是另一个函数类型的子类型,也就是说:在一个期望某个函数类型的上下文中,什么时候可以安全地使用另一个函数类型;**</font>
<font color="#f00">**我们可以说:函数f 可以安全替换函数g,如果与函数g 相比,函数f 接受更一般的参数类型,返回更特化的结果类型;**</font>
例如:
函数类型
Cat->Cat可安全用于期望Cat->Animal的地方;类似地,函数类型
Animal->Animal可用于期望Cat->Animal的地方;典型地,在
Animal a=Fn(Cat(...))这种语境下进行调用,由于 Cat 是 Animal 的子类,所以即使 Fn 接受一只 Animal 也同样是安全的!一般规则是:
S1 → S2 ≦ T1 → T2 当T1 ≦ S1且S2 ≦ T2
换句话说,类型构造符→对输入类型是逆变的而对输出类型是协变的;
这一规则首先被Luca Cardelli正式提出;
综合起来,也就是说:
<br/>
上面讲述了 OOP 中的协变,再来看 Rust 对于协变的定义;
众所周知,Rust 中是不存在类似于 OOP 中的继承的(不光Rust没有,同一时期的Go等语言都没有!),不算Trait的话,结构体或者枚举之间也都没有子类型关系;
但是Rust中有 lifetime,lifetime是和通常类型平行的另一套类型(另一个范畴),而Rust中的子类型就是对于lifetime而言的!
<br/>
子类型是一种序关系,不一定是像继承那样的超类型直接包含子类型(动物包含猫);
在 lifetime 中,外层的 lifetime 是它所包含的内层 lifetime 的子类型: 'big: 'small:
<font color="#f00">**注意:`外层的 lifetime 是它所包含的内层 lifetime 的子类型`,这里的顺序和直觉上是相反的!**</font>
如下图所示:
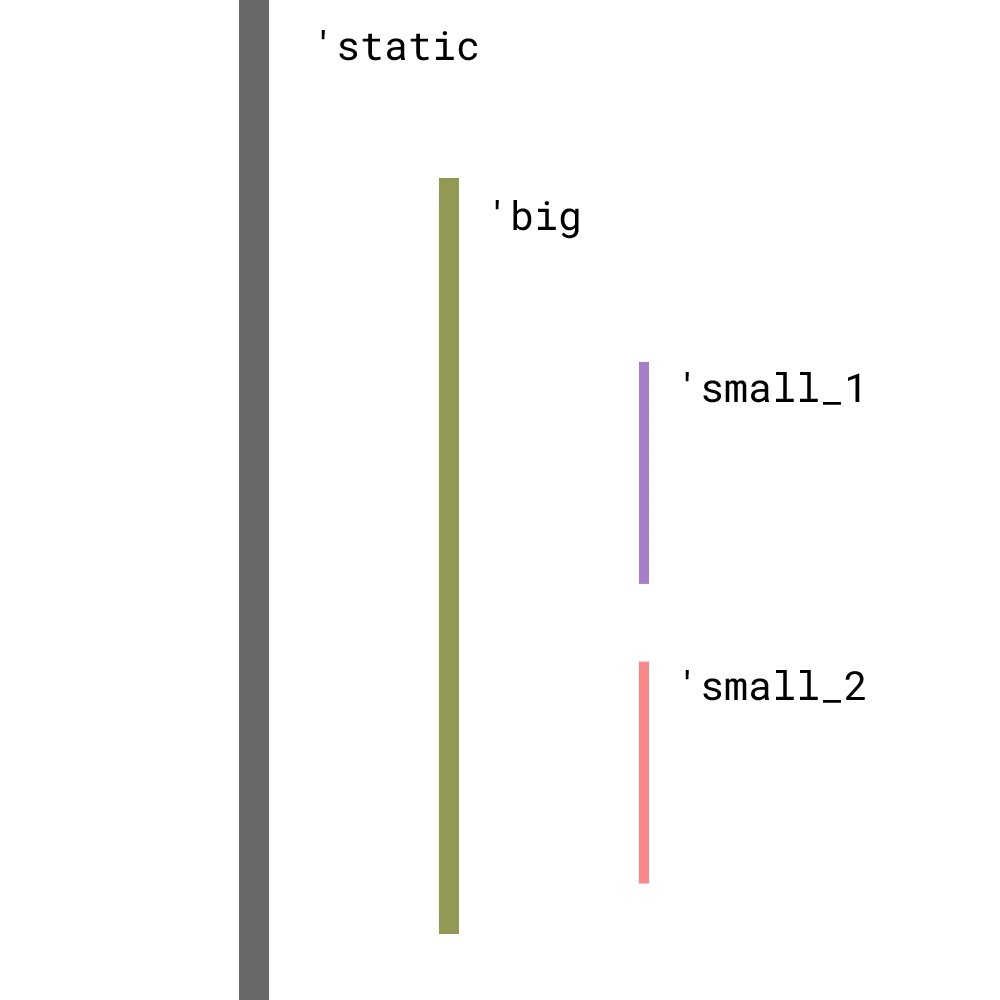
这张图中的子类型关系应当是:
'static: 'big: 'small_1;'static: 'big: 'small_2;即:'static 是所有lifetime的子类型!
lifetime 就是作用域,作用域是很标准的嵌套关系,所以Rust的规则有点反直觉;
对于集合,子集扩张到超集往往是恰当的,但一个作用域本身不应该被当作一个集合;
我们可以说:一只猫至少是一个动物;
但对于lifetime:不能说
'small_1至少是'big,而应该说'big至少是'small_1,也至少是'small_2;
<font color="#f00">**lifetime 存在的意义就是:界定资源不应该超出一个范围,也就是说:扩张 lifetime 往往是危险的,而收缩(只读引用)lifetime是安全的;**</font>
此处如果遵循直觉,按照嵌套关系排列:
也就是
'small_1: 'big: 'static,小的作用域'small_1就可以协变到全局作用域'static;那么在被读取的对象被销毁后,编译器还允许代码继续试图读取它,就会爆炸,整个lifetime系统就失效了!
可以通过下面几个方式来理解:
'small_1 的 lifetime 代表「包含 'small_1 的作用域的集合」;而 'static 就是「包含全局作用域的集合」只有一个元素;所以很显然后者是前者的子集,因为全局作用域包含了 'small_1;Cat 就是 Animal 增多内涵而来的,它的外延只有各种猫,而 Animal 的外延有各种动物;<br/>
死灵书:subtype原文详细地讲了这一块!
简而言之,在Rust中:
我们已知:
& 和 &mut 都是一个类型构造器,接受一个lifetime 'a 和另一个类型 T:
有一般规律:
<font color="#f00">**① `&'a T` 对 `'a` 和 `T` 协变,因为 `&` 是只读的,传参数的时候,试图收缩lifetime是安全的;**</font>
<font color="#f00">**② `&'a mut T` 对 `'a` 协变,对 `T` 不变:**</font>
这是因为:传参数的时候,收紧一个可变作用域的范围是安全的,调用者还维持着未收紧的作用域;
原因和上文所述一样:当传入的参数是一个函数的时候,我们可以安全地收缩这个函数的定义域,扩张这个函数的陪域,除此处外Rust中应该没有逆变;
这在别的语言中会爆炸,但是Rust对可变性的限制导致可以安全地当作协变:
当我们拿到一个容器的所有权的时候,外部别处就无法访问了,可以安全地对它协变而不用担心爆炸;
正如文中的例子一样:
fn overwrite<T: Copy>(covarianced: &mut T, short: &mut T) {
*covarianced = *short;
}
fn main() {
let mut forever: &'static str = " 我会活到世界末日 ";
'small {
let short = String::from(" 我马上死了 ");
overwrite(&mut forever, &mut &*short);
}
// 爆炸!用到了已经被释放的内存
println!("{}", forever);
}
如果在一次函数调用时:
一个 forever: &mut &'static T 能够协变到 covarianced: &mut &'small T ,我们就可以把一个 short: &'small T 存进协变后的参数 covarianced: &mut &'small T;
这对于调用者来说,引用 covarianced 的类型依然是 &mut &'static T,却存了一个更短命的引用 short;
当 short 被销毁的时候,a 还维持着引用,就…会炸;
至于这里为什么不能用逆变,原因很简单,就是 &mut T ,T 是可读可写的,如果能扩张 T 的作用域(逆变),读取出来存到别的地方还是会炸;
if variance would allow you to store a short-lived value in a longer-lived slot, then invariance must be used.
具体协变、逆变和不变相关内容可以阅读:
<br/>
NonNull和*mutNonNull的官方注释如下:
*mut T but non-zero and covariant.
This is often the correct thing to use when building data structures using raw pointers, but is ultimately more dangerous to use because of its additional properties. If you're not sure if you should use NonNull<T>, just use *mut T!
Unlike *mut T, the pointer must always be non-null, even if the pointer is never dereferenced. This is so that enums may use this forbidden value as a discriminant -- Option<NonNull<T>> has the same size as *mut T. However the pointer may still dangle if it isn't dereferenced.
Unlike *mut T, NonNull<T> was chosen to be covariant over T. This makes it possible to use NonNull<T> when building covariant types, but introduces the risk of unsoundness if used in a type that shouldn't actually be covariant. (The opposite choice was made for *mut T even though technically the unsoundness could only be caused by calling unsafe functions.)
Covariance is correct for most safe abstractions, such as Box, Rc, Arc, Vec, and LinkedList. This is the case because they provide a public API that follows the normal shared XOR mutable rules of Rust.
If your type cannot safely be covariant, you must ensure it contains some additional field to provide invariance. Often this field will be a PhantomData type like PhantomData<Cell<T>> or PhantomData<&'a mut T>.
Notice that NonNull<T> has a From instance for &T. However, this does not change the fact that mutating through a (pointer derived from a) shared reference is undefined behavior unless the mutation happens inside an UnsafeCell<T>. The same goes for creating a mutable reference from a shared reference. When using this From instance without an UnsafeCell<T>, it is your responsibility to ensure that as_mut is never called, and as_ptr is never used for mutation.
首先,NonNull就是 *mut T,但是不会等于零;
随后,NonNull是协变:【即有一个子生命周期Small和父生命周期 Longer,NonNull维持了 NonNull<Small> 也是NonNull<Longer>的生命周期的关系!】;
同时,NonNull<T> 不会拥有 T,因为其本身只是一个指针*mut T,没有拥有的语义;
因此需要借助 PhantomData 进行标注;
最后,NonNull 可以做空指针优化:
Option<Rc<T>>跟Rc<T>占用相同的内存大小,这个叫discriminant elision;空指针优化能够实现的原因在于:
<font color="#f00">**因为 enum 通常需要一个标志(discriminant)来区分究竟是哪一个variant,但是Option只有两个variant的enum,其中一个variant,有一些非法的值(叫niches),这些非法的值可以充当None一样的variant,所以就不用标志了,从而enum与variant占用一样的大小;**</font>
<br/>
最后,再来回顾 next 和 prev 的类型为:Option<NonNull<Node<T>>>;
即, next 和 prev 最终指向了另一个和自己相同的类型:Node<T>;
这是合理的,因为在整个 Node 类型中,所有的属性的大小在编译期都是可以被确定的(泛型类型T 在编译器被绑定,而 next 和 prev 为两个固定大小的裸指针)!
struct Node<T> {
val: T,
next: Option<NonNull<Node<T>>>,
prev: Option<NonNull<Node<T>>>,
}
注意:Rust的编译器要求,在编译期所有的属性的大小都是确定的!
例如,下面的代码是无法通过编译的:
struct WrongNode<T> { data: T, next: WrongNode<T>, }因为
next字段拥有的大小可能是无限的,无法计算;这也是为什么通常情况下,单向链表需要借助智能指针 Box 将结构体转化为指针:
struct WrongNode<T> { data: T, next: Box<WrongNode<T>>, }但是在双向链表中,使用 Box 是行不通的,因为会出现一个节点同时存在多个可变引用的情况,因此需要使用裸指针;
最后,一个简单的构造函数,和 into 转换函数,用于将 Box 中的 Node<T> 转为含有所有权的 T 类型,这个函数下面会用到:
impl<T> Node<T> {
fn new(val: T) -> Node<T> {
Node {
val,
prev: None,
next: None,
}
}
fn into_val(self: Box<Self>) -> T {
self.val
}
}
链表节点的具体内容大概就是这么多,接下来我们来看整个双向链表的定义;
<br/>
双向链表的定义如下:
pub struct LinkedList<T> {
length: usize,
head: Option<NonNull<Node<T>>>,
tail: Option<NonNull<Node<T>>>,
_marker: PhantomData<Box<Node<T>>>,
}
在双向链表中,定义了:
head 和 tail,类型和上面的 Node 内部的指针一样:Option<NonNull<Node<T>>>,这里不再介绍;重点来看一下:_marker;
_marker 被声明为 PhantomData<Box<Node<T>>> 类型,对于 PhantomData 的说明如下:
Zero-sized type used to mark things that "act like" they own a T.
Adding a PhantomData<T> field to your type tells the compiler that your type acts as though it stores a value of type T, even though it doesn't really. This information is used when computing certain safety properties.
即 _marker 是一个标注字段,其目的就是告诉编译器:LinkedList 拥有 Box<Node<T>>,明示编译器我们很可能在LinkedList 的 drop 函数里面也 drop 掉 Box<Node<T>>;
一个比较常见的场景如下:
由于在 LinkedList 中,
head和tail都以指针的形式存在;而在实现迭代器时,必须要求标注当前泛型
T的声明周期,此时我们就需要通过使用PhantomData对变量的所有权进行声明,并对生命周期进行标注!
以上就是我们要实现的双向链表的完整定义;
需要注意的是:
<font color="#f00">**为了体现封装性,Node 和 LinkedList 中的所有字段都是对外不可见的!**</font>
接下来我们会逐步实现双向链表的相关API,并尽量对性能做优化;
<br/>
构造函数的实现非常简单:
impl<T> LinkedList<T> {
pub fn new() -> Self {
Self {
length: 0,
head: None,
tail: None,
_marker: PhantomData,
}
}
}
impl<T> Default for LinkedList<T> {
fn default() -> Self {
Self::new()
}
}
在 new() 方法中,我们直接创建了一个 LinkedList 类型的对象(此处的Self代指的就是 LinkedList 类型)并返回;
注意到:
在给
_marker进行赋值时,我们直接使用了PhantomData;<font color="#f00">**这是因为实际上PhantomData是一个ZST(Zero-Size Type),即无内存大小类型;**</font>
从
PhantomData的定义中我们也能看出来:#[lang = "phantom_data"] #[stable(feature = "rust1", since = "1.0.0")] pub struct PhantomData<T: ?Sized>;<font color="#f00">**得益于Rust的优化,这些结构体在编译后都是不会占用内存大小的!**</font>
<font color="#f00">**因此,我们的 `_marker` 字段在编译后,甚至不会占用内存空间!**</font>
接下来,我们为 LinkedList 简单实现了 Default Trait,这使得我们可以通过两种方式创建出一个 LinkedList:
let list: LinkedList<i32> = LinkedList::default();
let list: LinkedList<i32> = LinkedList::new();
<br/>
在将一个元素压入双向链表时,需要注意:我们需要获取元素完整的所有权;
具体在链表头部压入元素的代码如下:
/// Adds the given node to the front of the list.
pub fn push_front(&mut self, val: T) {
// Use box to help generate raw ptr
let mut node = Box::new(Node::new(val));
node.next = self.head;
node.prev = None;
let node = NonNull::new(Box::into_raw(node));
match self.head {
None => self.tail = node,
Some(head) => unsafe { (*head.as_ptr()).prev = node },
}
self.head = node;
self.length += 1;
}
首先,我们使用入参中的 val 创建了一个链表节点Node,并使用 Box 包装(这么做是方便我们后面直接从 Box 获取到裸指针);
随后,对 node 进行赋值:
由于是在头部插入,因此新节点的下一个元素便是当前链表的头节点,而新节点的上一个元素是空(因为当前节点会成为新的链表的头节点);
这里得益于Rust中各种智能指针都实现了
DerefTrait,并且编译器会对具体的类型进行一系列ref/deref的类型推导(这一点和Golang极为相似);因此,尽管我们使用
Box对 Node 进行了一层包装,但 node 使用起来和未包装的体验完全一致!
接下来,使用 Box::into_raw(node),将 node 转为裸指针;
下面是 Box::into_raw 的官方文档:
Consumes the Box, returning a wrapped raw pointer.
消费Box,并返回一个裸指针。
The pointer will be properly aligned and non-null.
(函数保证)指针在内存中正确对齐并且非空。
After calling this function, the caller is responsible for the memory previously managed by the Box.
调用此函数后,调用者负责之前由 Box 管理的内存。
In particular, the caller should properly destroy T and release the memory, taking into account the memory layout used by Box. The easiest way to do this is to convert the raw pointer back into a Box with the Box::from_raw function, allowing the Box destructor to perform the cleanup.
特别是,调用者应该适当地销毁 T 并释放内存,同时考虑到 Box 使用的内存布局。最简单的方法是使用 Box::from_raw 函数将原始指针转换回 Box,从而允许 Box 析构函数执行清理。
Note: this is an associated function, which means that you have to call it as Box::into_raw(b) instead of b.into_raw(). This is so that there is no conflict with a method on the inner type.
注意:这是一个关联函数,这意味着您必须将其称为 Box::into_raw(b) 而不是 b.into_raw()。这样就不会与内部类型的方法发生冲突。
可以看到,当对某个被 Box 包装的变量调用了 Box::into_raw 后,变量将会被转化为裸指针,同时指针指向的内存的管理权会被交给我们自己;
什么意思呢?
通常情况下在Rust中,当一个变量退出了自己的作用域后,Rust便会自动调用其 drop 函数释放其占用的内存(这也是为什么尽管Rust没有GC,没有free函数,也能保证内存的安全的原因);
但是如果我们对某个被 Box 包装的变量调用了 Box::into_raw 后,之前的变量便被转为了一个裸指针!
此时我们只能通过这个裸指针去访问原来的变量;
实际上
Box::new()就是创建了一个指向具体变量值的指针;而 Box 作为智能指针,在退出作用域后,会直接释放指针的内存,以及指针指向的变量的内存(类似于C++中的 unique_prt )
Box::into_raw 所做的其实就是消费掉 Box 并返回指针,并且保证不会像 Box 退出作用域后释放指针指向的内存(否则暴露的指针指向的是野内存,之后取数据会出问题,并且释放也会出问题!);
因此,需要我们自己保存这个裸指针,并在适当时候释放这个裸指针指向的内存!
那么如何释放由 Box 转换所得的裸指针指向的内存呢?
文档写的也非常清楚:
<font color="#f00">**最简单的方法是使用 `Box::from_raw` 函数将原始指针转换回 Box,从而允许 Box 析构函数执行清理;**</font>
<font color="#f00">**所以我们只需要将裸指针再转为实际的 Box,然后通过 Box 退出作用域后直接释放内存即可;**</font>
注:上面的技巧在 Unsafe Rust 中非常常见!
在下面的代码中,我们会大量使用!
<br/>
在将 node 转为裸指针后,接下来判断当前链表的头节点是否为空:
match self.head {
None => self.tail = node,
Some(head) => unsafe { (*head.as_ptr()).prev = node },
}
如果为空,则将链表的尾节点也指向这个新节点即可;
如果头节点不为空,则需要将当前链表头节点的前一个元素赋值为新的节点;
注意,这里使用到了 unsafe,因为我们需要将链表中的头指针 head 裸指针进行解引用并修改其 prev 值;
<font color="#f00">**Rust中,只有五类可以在 Unsafe Rust 中进行而不能在 Safe Rust 中进行的操作:**</font>
- 解引用裸指针
- 调用不安全的函数或方法
- 访问或修改可变静态变量
- 实现不安全 trait
访问
union的字段同时,
unsafe并不会关闭借用检查器或禁用任何其他 Rust 安全检查:如果在不安全代码中使用引用,它仍会被检查;unsafe关键字只是提供了那五个不会被编译器检查内存安全的功能,你仍然能在不安全块中获得某种程度的安全;再者,
unsafe不意味着块中的代码就一定是危险的或者必然导致内存安全问题:其意图在于作为程序员你将会确保unsafe块中的代码以有效的方式访问内存;
在修改了当前链表头节点的 prev 后,我们将新的节点设为链表的头节点,然后将链表长度加一,便完成了:
self.head = node;
self.length += 1;
<br/>
相对应的,我们有 push_back:
pub fn push_back(&mut self, val: T) {
// Use box to help generate raw ptr
let mut node = Box::new(Node::new(val));
node.next = None;
node.prev = self.tail;
let node = NonNull::new(Box::into_raw(node));
match self.tail {
None => self.head = node,
// Not creating new mutable (unique!) references overlapping `element`.
Some(tail) => unsafe { (*tail.as_ptr()).next = node },
}
self.tail = node;
self.length += 1;
}
和上面非常类似,这里不多赘述了;
<br/>
pop() 函数会将头部或者尾部的元素弹出;
所谓弹出就是:将元素从链表中删除,并且返回具有所有权的 T(如果存在的话);
同时,为了确切的表达是否存在元素,返回值我们使用 Option<T> 类型表示;
下面来实现从头部弹出元素的方法 pop_front;
代码如下所示:
/// Removes the first element and returns it, or `None` if the list is
/// empty.
///
/// This operation should compute in *O*(1) time.
pub fn pop_front(&mut self) -> Option<T> {
self.head.map(|node| {
self.length -= 1;
unsafe {
let node = Box::from_raw(node.as_ptr());
self.head = node.next;
match self.head {
None => self.tail = None,
Some(head) => (*head.as_ptr()).prev = None,
}
node.into_val()
}
})
}
注意到上面的代码风格,只是调用了
self.head.map()即完成了所有功能;这种函数式编程的风格在Rust中非常常见;
在解释上面的代码之前,这里需要补充一些关于 Option 的知识:
在 Rust 中所有的变量一定都不为 Null,即不会发生空指针;
例如,下面的结构体:
struct Foo {
x: String,
y: String,
}
let foo = Foo {
x: "foo".to_string(),
y: "bar".to_string(),
};
如果不对 x 或 y 初始化,则将导致编译错误!
而 Null 值的语义就是通过枚举类型 Option 来显示标注的!
Option 的定义如下:
#[derive(Copy, PartialEq, PartialOrd, Eq, Ord, Debug, Hash)]
#[rustc_diagnostic_item = "Option"]
#[stable(feature = "rust1", since = "1.0.0")]
pub enum Option<T> {
/// No value.
#[lang = "None"]
#[stable(feature = "rust1", since = "1.0.0")]
None,
/// Some value of type `T`.
#[lang = "Some"]
#[stable(feature = "rust1", since = "1.0.0")]
Some(#[stable(feature = "rust1", since = "1.0.0")] T),
}
其中,None 即对应了语义上的 Null,而 Some(T) 表示存在一个值;
<font color="#f00">**注意到,在 Option 中也存在空指针优化!**</font>
<font color="#f00">**因此 `Option<T>` 占用的内存大小和 `T` 是完全相同的!**</font>
<font color="#f00">**枚举 Option 在设计上的思考:**</font>
<font color="#f00">**如果你确定某个变量一定不为空,则无需使用 Option 来包装类型,此时在使用时,完全不需要担心会产生空指针等异常;**</font>
<font color="#f00">**只有在你不确定某个变量是否一定有值时,才需要使用 Option 进行包装;**</font>
在使用 Option 时:
<font color="#f00">**由于 `Option<T>` 类型和 `T` 类型是完全不同的两个类型,Rust 会要求使用者显式的处理空指针的情况(取值为`None`的情况),因此极大的避免了空指针的行为!**</font>
见:
例如,修改上面的例子:
struct Foo {
x: Option<String>,
y: Option<String>,
}
let foo = Foo {
x: Option::from("foo".to_string()),
y: None,
};
此时就可以表示一个None值;
<br/>
简单介绍了 Option 后,下面来看一下 self.head.map();
在 Rust 中,可能会存在很多 Option,如果需要将一个 Option 进行处理后,再返回另一个 Option 通常需要三个步骤:
判断 Option A 是 Some => 解出 A => 处理A,得到结果B => 判断B是否为None => 包装并返回 Option B
整个步骤异常繁杂:
struct Foo {
x: Option<String>,
y: Option<String>,
}
let a = Foo {
x: Option::from("foo".to_string()),
y: None,
};
let mut b: String = "".to_string();
if a.x.is_some() {
b = a.x.unwrap();
}
let res = if b.ends_with("0") {
Some(b)
} else {
None
};
println!("{:?}", res); // None
考虑到这种场景非常常见,因此 Rust 在 Option 中提供了 map 方法:
pub const fn map<U, F>(self, f: F) -> Option<U>
where
F: ~const FnOnce(T) -> U,
F: ~const Drop,
{
match self {
Some(x) => Some(f(x)),
None => None,
}
}
用于将一个 Option<T> 类型转换为 Option<U> 类型;
因此,上面的例子可以直接被简化为:
let res = a.x.map(|str| {
if str.ends_with("o") {
str
} else {
None
}
});
<br/>
经过上面的补充知识可以知道,self.head.map() 会处理整个弹出逻辑,并将头节点转换为返回值弹出;
如果 head 为空,map 函数会直接返回 None;
下面具体来看 map 函数中 Lambda表达式的逻辑:
|node| {
self.length -= 1;
unsafe {
let node = Box::from_raw(node.as_ptr());
self.head = node.next;
match self.head {
None => self.tail = None,
Some(head) => (*head.as_ptr()).prev = None,
}
node.into_val()
}
}
此时,node 表示已经从 Option 中解出来的类型,即:NonNull<Node<T>>,裸指针类型;
根据我们之前说的,首先使用 Box::from_raw 将裸指针还原为 Box<Node<T>> 类型(为返回头节点数据做准备);
然后将链表的头节点指向当前节点的下一个节点;
随后,修改链表头节点的内容:
判断当前链表头节点是否为 None(弹出元素后是否变为空链表):
None;prev 置为 None(表示当前 节点已经变为链表的头节点);最后,使用前文提到的 into_val 函数,将 Box<Node<T>> 中的值取出,完成;
<br/>
同样的,尾部弹出一个元素:
/// Removes the last element from a list and returns it, or `None` if
/// it is empty.
///
/// This operation should compute in *O*(1) time.
pub fn pop_back(&mut self) -> Option<T> {
self.tail.map(|node| {
self.length -= 1;
unsafe {
let node = Box::from_raw(node.as_ptr());
self.tail = node.prev;
match self.tail {
None => self.head = None,
Some(tail) => (*tail.as_ptr()).next = None,
}
node.into_val()
}
})
}
<br/>
由于在 Rust 中是区分元素所有权,并且区分可变和不可变引用的(未标注 mut 默认为不可变引用);
因此在 Rust 中实现 peek() 和在其他编程语言中略有不同!
我们需要分别实现:
peek():返回不可变引用类型;peek_mut():返回可变引用类型;<font color="#f00">**需要注意的是:上面两个方法仅仅返回元素的引用,而元素的所有权还是在链表中;**</font>
peek_front()先来实现 peek_front(),代码如下:
pub fn peek_front(&self) -> Option<&T> {
unsafe {
self.head.as_ref().map(|node| &node.as_ref().val)
}
}
代码非常简洁,只有一行;我们一个方法一个方法的来看;
首先,和之前类似,Option 提供了 as_ref 方法,可以将 Option<T> 转为 Option<&T> 而不用频繁的拆包再包装;
之后再次调用 map 方法(注意,此时 node 的类型为 &NonNull<Node<T>>,即裸指针的引用类型),将当前 Option 中的 裸指针引用转为 Option<&T> ,即Node节点的引用;
在上面的 &node.as_ref().val 中:
首先 node.as_ref() 做的事情是:
#[stable(feature = "nonnull", since = "1.25.0")]
#[rustc_const_unstable(feature = "const_ptr_as_ref", issue = "91822")]
#[must_use]
#[inline]
pub const unsafe fn as_ref<'a>(&self) -> &'a T {
// SAFETY: the caller must guarantee that `self` meets all the
// requirements for a reference.
unsafe { &*self.as_ptr() }
}
即,as_ref 会将裸指针解引用,并将实际的Node节点元素的引用返回,即:&Node<T>;
这里直接支持这个操作的原因是因为:
<font color="#f00">**我们使用了 `NonNull` 类型,保证了指针一定不为空,即:裸指针一定不为空指针!**</font>
随后,我们取出 node.as_ref().val 即:裸指针对应Node节点的 val 字段,我们真正返回的元素!
最后 &node.as_ref().val 表示取 node 节点 val 元素的引用!
总结:
&node.as_ref().val的顺序为:&((node.as_ref()).val)上面的函数和取引用操作缺一不可!
<br/>
peek_back()对应的,peek_back(),代码如下:
pub fn peek_back(&self) -> Option<&T> {
unsafe { self.tail.as_ref().map(|node| &node.as_ref().val) }
}
这里不再赘述!
<br/>
peek_front_mut()除了返回引用类型的元素之外,我们还要能返回可变引用类型:Option<&mut T>:
使得用户能够对链表中的节点元素值进行修改,但是不真正获取元素的所有权!
实现 peek_front() 的代码同样非常简洁,代码如下:
pub fn peek_front_mut(&mut self) -> Option<&mut T> {
unsafe { self.head.as_mut().map(|node| &mut node.as_mut().val) }
}
相比于仅返回引用类型(只读)的情况,这里的修改主要是:
as_ref 改为了 as_mut;&node 改为了 &mut node;思考一下,为什么这里需要将这么多的引用改为可变引用呢?
首先,你需要明确一点:
<font color="#f00">**在 Rust 中,如果修改一个容器中的元素,首先这个容器需要是可变的!**</font>
那么,head.as_mut() 就获取了一个可变的裸指针(即,这个裸指针指向的内存是可变的,而不是这个指针可变!);
进而,此时 node 的类型为 &mut NonNull<Node<T>>;
随后,调用 node 的 as_mut 方法:
#[stable(feature = "nonnull", since = "1.25.0")]
#[rustc_const_unstable(feature = "const_ptr_as_ref", issue = "91822")]
#[must_use]
#[inline]
pub const unsafe fn as_mut<'a>(&mut self) -> &'a mut T {
// SAFETY: the caller must guarantee that `self` meets all the
// requirements for a mutable reference.
unsafe { &mut *self.as_ptr() }
}
可以看到,调用裸指针的 as_mut 方法需要一个可变指针 &mut self,这也是为什么上面使用了head.as_mut();
随后 node.as_mut 方法,返回一个裸指针解引用后的 Node 的可变引用:&mut Node<T>;
最后,&mut node.as_mut().val 生成了 &mut T,即Node节点对应的可变引用!
<br/>
peek_back_mut()对应的,peek_back_(),代码如下:
pub fn peek_back_mut(&mut self) -> Option<&mut T> {
unsafe { self.tail.as_mut().map(|node| &mut node.as_mut().val) }
}
这里不再赘述!
<br/>
get_by_idx()有了查看首尾元素,我们自然还需要根据 index 索引查看任意位置的元素;
但是这里需要明确一点:
api调用方很有可能传入了一个非法的index值,如:-1、超过链表长度的值等;
这个时候有两种处理方法:
在这里,我们选择返回错误:
因为,如果仅仅返回 None,api调用方不能确定是因为 index 传错而导致的 None,还是链表本身就是空的!
下面我们补充一些关于 Rust 中错误处理的知识(已经对这个内容很熟悉的同学可以跳过这部分)!
目前,主流的错误处理方法主要包括:
详见:
总的来说,在 Rust 中主要有两种错误处理方式(和 Golang 比较类似):
panic:主要用于测试,以及处理不可恢复的错误;(在原型开发中这很有用,比如 用来测试还没有实现的函数,不过这时使用 unimplemented 更能表达意图;)Result:当错误有可能发生,且应当由调用者处理时使用;通常情况下,我们都使用枚举 Result:
#[derive(Copy, PartialEq, PartialOrd, Eq, Ord, Debug, Hash)]
#[must_use = "this `Result` may be an `Err` variant, which should be handled"]
#[rustc_diagnostic_item = "Result"]
#[stable(feature = "rust1", since = "1.0.0")]
pub enum Result<T, E> {
/// Contains the success value
#[lang = "Ok"]
#[stable(feature = "rust1", since = "1.0.0")]
Ok(#[stable(feature = "rust1", since = "1.0.0")] T),
/// Contains the error value
#[lang = "Err"]
#[stable(feature = "rust1", since = "1.0.0")]
Err(#[stable(feature = "rust1", since = "1.0.0")] E),
}
可以说,Result 是 Option 类型的更丰富的版本,描述的是可能的错误,而不是可能的不存在;
也就是说,Result<T,E> 可以有两个结果的其中一个:
Ok<T>:找到 T 元素;Err<E>:找到 E 元素,E 即表示错误的类型;<br/>
有时候,我们可能需要自定义一些错误类型,如:index不合法;
我们可以通过为我们的类型实现 error::Error Trait:
use std::{error, fmt};
#[derive(Debug, Clone)]
pub struct IndexOutOfRangeError;
impl fmt::Display for IndexOutOfRangeError {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "index out of range")
}
}
impl error::Error for IndexOutOfRangeError {}
上面的代码定义了一个 IndexOutOfRangeError 类型,并实现了 error::Error Trait;
error::Error中有许多方法可以重写以提供更多关于错误的信息,例如:
- backtrace;
- description;
- ……
接下来,我们就可以在我们的代码中使用这个错误了,例如:
pub fn get_by_idx(&self, idx: usize) -> Result<Option<&T>, Box<dyn Error>> {
......
}
更多关于 Rust 中错误处理见:
<br/>
get_by_idx方法的代码如下:
pub fn get_by_idx(&self, idx: usize) -> Result<Option<&T>, Box<dyn Error>> {
let len = self.length;
if idx >= len {
return Err(Box::new(IndexOutOfRangeError {}));
}
// Iterate towards the node at the given index, either from the start or the end,
// depending on which would be faster.
let offset_from_end = len - idx - 1;
let mut cur;
if idx <= offset_from_end {
// Head to Tail
cur = self.head;
for _ in 0..idx {
match cur.take() {
None => {
cur = self.head;
}
Some(current) => unsafe {
cur = current.as_ref().next;
},
}
}
} else {
// Tail to Head
cur = self.tail;
for _ in 0..offset_from_end {
match cur.take() {
None => {
cur = self.tail;
}
Some(current) => unsafe {
cur = current.as_ref().prev;
},
}
}
}
unsafe { Ok(cur.as_ref().map(|node| &node.as_ref().val)) }
}
下面来看一下代码;
首先,判断用户传入的索引index是否大于了链表长度: idx >= len;
注意:这里并没有校验索引小于0,因为
idx是usize类型的,一定不会小于0了!
随后,我们计算 offset_from_end,来判断是从链表头部到 index 近,还是尾部近(充分利用我们双向链表的优势)!
如果 idx <= offset_from_end,说明从头部到 index 的距离更近:
// Head to Tail
cur = self.head;
for _ in 0..idx {
match cur.take() {
None => {
cur = self.head;
}
Some(current) => unsafe {
cur = current.as_ref().next;
},
}
}
首先,代码将链表头部 移动 给了 cur;
<br/>
看到这里,有人就会有疑问了:Rust 中的 = 是 move 语义,这样做原链表中的 head 不就变成空值了!
的确,Rust中的 = 是 move 语义,但是<font color="#f00">**在Rust中存在另两个 Trait:`Clone & Copy`:**</font>
/// A common Trait for the ability to explicitly duplicate an object.
#[stable(feature = "rust1", since = "1.0.0")]
#[lang = "clone"]
#[rustc_diagnostic_item = "Clone"]
#[rustc_trivial_field_reads]
pub trait Clone: Sized {
#[stable(feature = "rust1", since = "1.0.0")]
#[must_use = "cloning is often expensive and is not expected to have side effects"]
fn clone(&self) -> Self;
#[inline]
#[stable(feature = "rust1", since = "1.0.0")]
fn clone_from(&mut self, source: &Self) {
*self = source.clone()
}
}
/// Types whose values can be duplicated simply by copying bits.
#[stable(feature = "rust1", since = "1.0.0")]
#[lang = "copy"]
#[rustc_unsafe_specialization_marker]
#[rustc_diagnostic_item = "Copy"]
pub trait Copy: Clone {
// Empty.
}
Clone 很好理解,就是由一个类型的实例创建出另一个相同类型的实例;
而实现Copy的类型(实现Copy需要先实现Clone),可以使用简单字节copy的方式复制;
<font color="#f00">**与Clone不同,Copy方式是隐式作用于类型变量,通过赋值语句来完成;**</font>
这一点有些类似于 Java 中的基本类型(如,int、double);
<font color="#f00">**并非所有的对象都需要使用对象包装,有些时候:直接对类型进行字节copy的成本要比生成一个指向对象的引用指针还要低!**</font>
以下面的代码为例:
let mut x = Some(1);
let y = x;
let z = x.take();
println!("{:?} {:?} {:?}", x, y, z); // None Some(1) Some(1)
上面的 y = x 为 Copy 语义,因此最终、y、z 都是存在值的!
<font color="#f00">**注:在 Rust 中默认是 Move 语义,但是如果实现了 Copy Trait就会变为 Copy 语义;**</font>
<font color="#f00">**因此,明确一个变量是否实现了 Copy Trait 是非常重要的**</font>
NonNull 便实现了Clone 和 Copy Trait:
#[stable(feature = "nonnull", since = "1.25.0")]
impl<T: ?Sized> Clone for NonNull<T> {
#[inline]
fn clone(&self) -> Self {
*self
}
}
#[stable(feature = "nonnull", since = "1.25.0")]
impl<T: ?Sized> Copy for NonNull<T> {}
因此上面的 cur = self.head; 最终会将变量 cur 也赋值为指向链表头部的裸指针;
补充内容:Option 中的 take 方法:
将
Option<T>中的值T取出,如果 Option 为 None,则返回 None;
<br/>
随后,从头部开始遍历,直到第 idx 个节点:
for _ in 0..idx {
match cur.take() {
None => {
cur = self.head;
}
Some(current) => unsafe {
cur = current.as_ref().next;
},
}
}
这段代码比较简单,执行完后,cur 就指向了链表中的第 idx 个节点;
<br/>
如果 idx 节点离链表尾部比较近,则将会从尾部向前遍历;
代码如下:
else {
// Tail to Head
cur = self.tail;
for _ in 0..offset_from_end {
match cur.take() {
None => {
cur = self.tail;
}
Some(current) => unsafe {
cur = current.as_ref().prev;
},
}
}
}
这一段代码与从头开始遍历极为相似,这里不再赘述!
<br/>
经过上面的处理,最终会找到指向第 idx 个元素的裸指针:cur;
最后,我们返回这个指针指向的节点中的值即可:
unsafe { Ok(cur.as_ref().map(|node| &node.as_ref().val)) }
至此,我们的根据 index 查看元素的方法已经完成!
<br/>
有了根据 index 获取只读元素的 get_by_idx,很自然的想到还会有获取可变元素的 get_by_idx_mut;
与 get_by_idx 不同,get_by_idx_mut 的使用场景在内部实现中也会被大量用到,例如:
因此,我们可以实现一个内部方法:返回指向 index 对应节点的可变裸指针来达到代码复用的效果:
fn _get_by_idx_mut(&self, idx: usize) -> Result<Option<NonNull<Node<T>>>, Box<dyn Error>> {
let len = self.length;
if idx >= len {
return Err(Box::new(IndexOutOfRangeError {}));
}
// Iterate towards the node at the given index, either from the start or the end,
// depending on which would be faster.
let offset_from_end = len - idx - 1;
let mut cur;
if idx <= offset_from_end {
// Head to Tail
cur = self.head;
for _ in 0..idx {
match cur.take() {
None => {
cur = self.head;
}
Some(current) => unsafe {
cur = current.as_ref().next;
},
}
}
} else {
// Tail to Head
cur = self.tail;
for _ in 0..offset_from_end {
match cur.take() {
None => {
cur = self.tail;
}
Some(current) => unsafe {
cur = current.as_ref().prev;
},
}
}
}
Ok(cur)
}
代码与 get_by_idx 方法即为相似,只是把 cur 声明为了 mut,并且直接返回 Ok(cur)!
随后,直接使用这个内部方法实现我们的 get_by_idx_mut 方法:
pub fn get_by_idx_mut(&self, idx: usize) -> Result<Option<&mut T>, Box<dyn Error>> {
let mut cur = self._get_by_idx_mut(idx)?;
unsafe { Ok(cur.as_mut().map(|node| &mut node.as_mut().val)) }
}
<br/>
经过前面的一些铺垫,这里实现的方法就显得比较常规了!
具体代码如下:
pub fn insert_by_idx(&mut self, idx: usize, data: T) -> Result<(), Box<dyn Error>> {
let len = self.length;
if idx > len {
return Err(Box::new(IndexOutOfRangeError {}));
}
if idx == 0 {
return Ok(self.push_front(data));
} else if idx == len {
return Ok(self.push_back(data));
}
unsafe {
// Create Node
let mut spliced_node = Box::new(Node::new(data));
let before_node = self._get_by_idx_mut(idx - 1)?;
let after_node = before_node.unwrap().as_mut().next;
spliced_node.prev = before_node;
spliced_node.next = after_node;
let spliced_node = NonNull::new(Box::into_raw(spliced_node));
// Insert Node
before_node.unwrap().as_mut().next = spliced_node;
after_node.unwrap().as_mut().prev = spliced_node;
}
self.length += 1;
Ok(())
}
首先,如果 idx 大于 len,则返回错误(这里可以相等,这相当于在链表尾部插入一个元素);
随后,为了避免一些样板代码:
idx==0可以被简化为:push_front;idx == len可以被简化为:push_back;如果是在链表的中间节点插入元素,则:
// Create Node
let mut spliced_node = Box::new(Node::new(data));
let before_node = self._get_by_idx_mut(idx - 1)?;
let after_node = before_node.unwrap().as_mut().next;
spliced_node.prev = before_node;
spliced_node.next = after_node;
let spliced_node = NonNull::new(Box::into_raw(spliced_node));
// Insert Node
before_node.unwrap().as_mut().next = spliced_node;
after_node.unwrap().as_mut().prev = spliced_node;
首先,创建一个新的元素:Box::new(Node::new(data));
随后使用我们之前写过的方法:self._get_by_idx_mut(idx - 1)?,取出将要插入的 index 的前一个元素:before_node;
补充知识:
?操作符如果你使用过 Kotlin 你就会对这个操作符很熟悉:
?操作符放在一个返回 Result 类型的函数后:
- 如果函数返回 Error,则该函数会直接 return Error;
否则,函数调用成功,返回函数的返回值;
?操作符经常用在如果调用函数发生错误,直接返回错误的场景,用于简化代码;
然后,通过 let after_node = before_node.unwrap().as_mut().next; 获取当前 index 处的节点(因为插入新节点只需要修改这两个节点即可!);
最后,修改待插入的节点的 prev 和 next,然后将节点插入:
spliced_node.prev = before_node;
spliced_node.next = after_node;
let spliced_node = NonNull::new(Box::into_raw(spliced_node));
// Insert Node
before_node.unwrap().as_mut().next = spliced_node;
after_node.unwrap().as_mut().prev = spliced_node;
注:这里使用
unwrap()直接获取节点的值是因为,我们能够保证这些节点一定不为 None!否则会产生 panic 错误!
<br/>
有了在 index 前插入元素,下面我们继续实现删除 index 处元素的逻辑;
和在 index 处插入元素类似:
index >= len,则报错(此时 index 没有元素,我们也不能移除元素);idx == 0,调用 pop_front;idx == len -1,调用 pop_back;否则,进入移除在链表内部节点的逻辑;
代码如下:
/// Removes the element at the given index and returns it.
///
/// This operation should compute in *O*(*n*) time.
pub fn remove_by_idx(&mut self, idx: usize) -> Result<T, Box<dyn Error>> {
let len = self.length;
if idx >= len {
return Err(Box::new(IndexOutOfRangeError {}));
}
if idx == 0 {
return Ok(self.pop_front().unwrap());
} else if idx == len - 1 {
return Ok(self.pop_back().unwrap());
};
let cur = self._get_by_idx_mut(idx)?.unwrap();
self.unlink_node(cur);
unsafe {
let unlinked_node = Box::from_raw(cur.as_ptr());
Ok(unlinked_node.val)
}
}
如果 index 为链表内部节点,则在移除时:
首先,通过 self._get_by_idx_mut(idx)?.unwrap(); 获取在 index 处的裸指针(待移除节点对应指针);
随后,调用 unlink_node 方法将该节点从链表中移除:
/// Unlinks the specified node from the current list.
///
/// Warning: this will not check that the provided node belongs to the current list.
///
/// This method takes care not to create mutable references to `element`,
/// to maintain validity of aliasing pointers.
#[inline]
fn unlink_node(&mut self, mut node: NonNull<Node<T>>) {
let node = unsafe { node.as_mut() }; // this one is ours now, we can create an &mut.
// Not creating new mutable (unique!) references overlapping `element`.
match node.prev {
Some(prev) => unsafe { (*prev.as_ptr()).next = node.next },
// this node is the head node
None => self.head = node.next,
};
match node.next {
Some(next) => unsafe { (*next.as_ptr()).prev = node.prev },
// this node is the tail node
None => self.tail = node.prev,
};
self.length -= 1;
}
unlink_node 的逻辑非常简单,就是:
修改待移除节点的前一个节点和后一个节点的指针,使得自身节点被移出原链表!
最后,代码通过:Box::from_raw 将裸指针还原为实际的 Box<Node<T>> 类型,并将节点中的元素值返回!
unsafe {
let unlinked_node = Box::from_raw(cur.as_ptr());
Ok(unlinked_node.val)
}
注:remove_by_idx 方法签名为:
remove_by_idx(&mut self, idx: usize) -> Result<T, Box<dyn Error>><font color="#f00">**即,remove_by_idx 方法会直接将节点移除,并将在节点存放元素的所有权返回给方法调用者!**</font>
<br/>
对应于 Rust 变量存在的三种形式(&self、&mut self、self),迭代器也被分为了三种:
首先我们为链表定义这三种迭代器类型:
pub struct IntoIter<T> {
list: LinkedList<T>,
}
pub struct Iter<'a, T: 'a> {
head: Option<NonNull<Node<T>>>,
tail: Option<NonNull<Node<T>>>,
len: usize,
_marker: PhantomData<&'a Node<T>>,
}
pub struct IterMut<'a, T: 'a> {
head: Option<NonNull<Node<T>>>,
tail: Option<NonNull<Node<T>>>,
len: usize,
_marker: PhantomData<&'a mut Node<T>>,
}
对于 IntoIter 的结构声明是明确的,因为 IntoIter 会获取整个链表所有节点的所有权,因此直接将链表的所有权转移至 IntoIter 中即可;
但是对于 Iter 和 IterMut 而言,我们需要 Copy 当前链表的头节点和尾节点,而非获取链表的所有权;
同时,对于 Iterator 的 Item 如果是引用类型,则需要指定对应元素的生命周期;
但是由于 head 和 tail 中存放的是裸指针(即表示,其内存分配是由我们来管理的!),因此此时再次需要使用 PhantomData 来避免编译器对于生命周期的检查问题;
相对应的,下面是在双向链表中实现的各个类型的迭代器的构造方法:
pub fn into_iter(self) -> IntoIter<T> {
IntoIter { list: self }
}
pub fn iter(&self) -> Iter<'_, T> {
Iter {
head: self.head,
tail: self.tail,
len: self.length,
_marker: PhantomData,
}
}
pub fn iter_mut(&mut self) -> IterMut<'_, T> {
IterMut {
head: self.head,
tail: self.tail,
len: self.length,
_marker: PhantomData,
}
}
除了 IntoIter 直接获取的链表的所有权,Iter 和 IterMut 都是仅仅 Copy 裸指针;
至此,我们对三种迭代器的定义完成,下面来具体实现每一种迭代器;
<br/>
IntoIter的实现非常简单,因为我们已经完全将链表的所有权交给了 IntoIter;
因此,如果需要正向遍历,我们直接调用 pop_front 即可;而如果需要反向遍历,我们只需要调用 pop_back;
代码如下:
impl<T> Iterator for IntoIter<T> {
type Item = T;
#[inline]
fn next(&mut self) -> Option<Self::Item> {
self.list.pop_front()
}
#[inline]
fn size_hint(&self) -> (usize, Option<usize>) {
(self.list.length, Some(self.list.length))
}
}
impl<T> DoubleEndedIterator for IntoIter<T> {
#[inline]
fn next_back(&mut self) -> Option<Self::Item> {
self.list.pop_back()
}
}
由于双向链表可以从两个方向迭代,因此我们为 IntoIter 同时实现了两个 Trait:
在实现 Iterator 时:
首先,type Item = T; 声明了迭代器返回值类型为 T;
而 next 就是用 pop_front 方法实现;
同理,DoubleEndedIterator 使用 pop_back 方法实现;
<font color="#f00">**需要注意的是:**</font>
<font color="#f00">**由于 IntoIter 获取了整个链表的所有权,而我们是通过裸指针实现的链表,即我们需要手动管理这部分内存;**</font>
<font color="#f00">**因此,我们需要手动为 IntoIter 实现 Drop Trait,以确保在 IntoIter 退出作用域后,能够准备的释放掉那些还没有被 move 出去的元素!**</font>
具体实现代码如下:
impl<T> Drop for IntoIter<T> {
fn drop(&mut self) {
// only need to ensure all our elements are read;
// buffer will clean itself up afterwards.
for _ in &mut *self {}
println!("IntoIter has been dropped!")
}
}
代码非常简单,我们直接通过 for 循环将 IntoIter 中还未被消费的元素直接取出来,然后忽略掉即可!
注1:
<font color="#f00">**这里的 `for _ in &mut *self {}` 实际上就是调用的迭代器本身的 `next` 方法去取元素;**</font>
<font color="#f00">**而 `next` 是调用的链表的 pop_front 方法,该方法最终会调用 `Box::from_raw` 将裸指针转为具体的元素返回,因此实现了内存释放;**</font>
注2:
<font color="#f00">**这里所做的也仅仅是将元素取出,并忽略(退出作用域);**</font>
<font color="#f00">**具体的内存释放还要依赖于具体的范型类型 `T` 本身!**</font>
<br/>
相比于 IntoIter,在实现 Iter 时,我们需要自己手动维护 head 和 tail 裸指针;
具体代码如下:
impl<'a, T> Iterator for Iter<'a, T> {
type Item = &'a T;
#[inline]
fn next(&mut self) -> Option<Self::Item> {
if self.len == 0 {
None
} else {
self.head.map(|node| {
self.len -= 1;
unsafe {
let node = &*node.as_ptr();
self.head = node.next;
&node.val
}
})
}
}
#[inline]
fn size_hint(&self) -> (usize, Option<usize>) {
(self.len, Some(self.len))
}
#[inline]
fn last(mut self) -> Option<&'a T> {
self.next_back()
}
}
impl<'a, T> DoubleEndedIterator for Iter<'a, T> {
fn next_back(&mut self) -> Option<Self::Item> {
if self.len == 0 {
None
} else {
self.tail.map(|node| {
self.len -= 1;
unsafe {
// Need an unbound lifetime to get 'a
let node = &*node.as_ptr();
self.tail = node.prev;
&node.val
}
})
}
}
}
正向和反向遍历实现起来也比较简单,具体的实现逻辑这里就不再赘述了;
<font color="#f00">**需要注意的是:**</font>
<font color="#f00">**因为 Iter 本质上只是对我们的链表中的 head、tail 以及 length 等属性进行了 Copy,而各个元素的所有权依然在链表中;**</font>
<font color="#f00">**并且, head、tail 以及 length 实际上都是一个整型数字;**</font>
<font color="#f00">**因此我们不需要为特别为 Iter 实现 Drop 方法,因为 Iter 中的所有类型均已经由 Rust 标准库实现了 Drop!**</font>
<br/>
IterMut 的实现和 Iter 的实现几乎完全一致,只是将类型换为了:type Item = &'a mut T;
具体实现的代码如下:
impl<'a, T> Iterator for IterMut<'a, T> {
type Item = &'a mut T;
#[inline]
fn next(&mut self) -> Option<Self::Item> {
if self.len == 0 {
None
} else {
self.head.map(|node| {
self.len -= 1;
unsafe {
let node = &mut *node.as_ptr();
self.head = node.next;
&mut node.val
}
})
}
}
#[inline]
fn size_hint(&self) -> (usize, Option<usize>) {
(self.len, Some(self.len))
}
#[inline]
fn last(mut self) -> Option<&'a mut T> {
self.next_back()
}
}
impl<'a, T> DoubleEndedIterator for IterMut<'a, T> {
#[inline]
fn next_back(&mut self) -> Option<Self::Item> {
if self.len == 0 {
None
} else {
self.tail.map(|node| {
self.len -= 1;
unsafe {
// Need an unbound lifetime to get 'a
let node = &mut *node.as_ptr();
self.tail = node.prev;
&mut node.val
}
})
}
}
}
这里不再赘述!
<br/>
实现了迭代器之后,我们便很容易通过迭代器来遍历判断链表中是否包含某个元素;
这里我们只需要只读权限即可,因此使用 iter 获取不可变引用的迭代器即可,代码如下:
/// Returns `true` if the `LinkedList` contains an element equal to the given value.
///
/// This operation should compute in *O*(*n*) time.
///
/// # Examples
///
///
/// use collection::list::linked_list::LinkedList; /// /// let mut list = LinkedList::new(); /// /// list.push_back(0); /// list.push_back(1); /// list.push_back(2); /// /// assert_eq!(list.contains(&0), true); /// assert_eq!(list.contains(&10), false); /// ``` pub fn contains(&self, elem: &T) -> bool where T: PartialEq<T>, { self.iter().any(|x| x == elem) }
代码非常简单,调用不可变引用迭代器 iter 的 any 方法,判断是否存在和 elem 相等的元素;
代码虽然很简单,这里还是有两个可以补充的内容:
- Rust 中和比较相关的 Trait:Eq、PartialOrd、Ord等;
- 声明范型约束;
下面分别来看;
#### **Rust 中和比较相关的 Trait**
在 `core::cmp.rs` 模块里定义了用于两值之间比较的几个 Trait,分别是:
- **PartialEq**
- **Eq**
- **PartialOrd**
- **Ord**
这四个 Trait 之间有这样一个关系:
- Eq 基于 PartialEq,即: `pub trait Eq: PartialEq`;
- PartialOrd 基于 PartialEq,即 `pub trait PartialOrd: PartialEq`;
- Ord 基于 Eq 和 PartialOrd, `pub trait PartialOrd: Eq + PartialOrd<Self>`;
同时还定义了比较结果 `Ordering` 这样一个枚举类型:
```rust
pub enum Ordering {
Less = -1,
Equal = 0,
Greater = 1,
}
下面具体来看每一种 Trait 分别表示什么;
先说最基础的 PartialEq, 这个 trait 定义了两个方法:
true, 需要使用者自行定义该方法;true;PartialEq trait 实现了部分等价关系 Partial_equivalence_relation,这种数值关系有以下特性:
a == b, 那么 b == a;a == b 且 b == c, 那么 a == c;所有的基本数据类型都实现了 PartialEq trait,它们都定义在 cmp.rs 源代码文件里;
并且,平时使用时只需要用 #[derive] 的方法实现即可,就像这样:
#[derive(PartialEq)]
pub struct Person {
pub id: u32,
pub name: String,
pub height: f64,
}
编译器会默认实现类似下面的代码:
impl PartialEq for Person {
fn eq(&self, other: &Self) -> bool {
self.id == other.id &&
self.name == other.name &&
self.height == other.height
}
}
但如果我们在比较两个 Person 时,只想通过 id 属性来确定是不是同一个人,则可以手动定义 PartialEq Trait 的实现:
impl PartialEq for Person {
fn eq(&self, other: &Self) -> bool {
self.id == other.id
}
}
<br/>
Eq Trait 实现了 等价关系 Equivalence_relation,该数值关系具有以下特性:
a == b, 那么 b == aa == b 且 b == c, 那么 a == ca == a<font color="#f00">**`Eq Trait` 基于 `PartialEq Trait`,但在此之上并没有添加新的方法定义;**</font>
<font color="#f00">**这个 Trait 只是用于给编译器提示:这是个 `等份关系` 而不是个 `部分等价关系`; 因为编译器并不能检测 `自反性 (reflexive)`!**</font>
例如,在标准库中, 只有 f32 和 f64 没有实现 Eq Trait, 因为浮点值有两个特殊的值:
它们本身是不可比较的,即: NAN != NAN;
我们可以来测试一下:
println!("NAN == NAN ? {}", std::f64::NAN == std::f64::NAN);
打印的结果是:
NAN == NAN ? false
所以,上面的示例中定义的 struct Person 是无法用 #[derive(Eq)] 的方法定义的:
#[derive(Eq)]
struct Person {
pub id: u32,
pub name: String,
pub height: f64,
}
编译器会报出以下错误:
188 | height: f64,
| ^^^^^^^^^^^ the trait `std::cmp::Eq` is not implemented for `f64`
|
= note: required by `std::cmp::AssertParamIsEq`
但我们可以手动实现该 Trait:
struct Person {
pub id: u32,
pub name: String,
pub height: f64,
}
impl Eq for Person {}
<br/>
PartialOrd Trait 基于 PartialEq Trait 实现,它新定义了几个方法:
偏序关系有以下特性:
a < b 那么 !(a > b);a < b 且 b < c 那么 a < c;标准库里的所有基本类型都已实现该 Trait;
自定义类型可以直接使用 #[derive] 的方式由编译器实现该 Trait;
或者也可像下面这样手动实现(这里是以身高来排序的):
impl PartialOrd for Person {
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
self.height.partial_cmp(&other.height)
}
}
<br/>
Ord Trait 基于 PartialOrd Trait 和 Eq Trait 实现,它新定义了几个方法:
全序关系有以下特性:
在标准库中,f32 和 f64 没有实现 Ord Trait!
同样是因为: NAN 和 INFINITY 的 不确定性, NAN 和 INFINITY 无法跟其它浮点值比较大小;
更详细关于 Rust 中的比较可见:
<br/>
有些时候,我们需要限定范型的具体类型实现了一些 Trait 之后才能绑定另一些方法(最经典的:我们需要约束一个范型可比较才能为其实现排序);
此时我们就需要在说实现的方法中声明范型约束;
Rust 中实现范型约束的方式有两种:
impl <A: TraitB + TraitC, D: TraitE + TraitF> MyTrait<A, D> for YourType {}
// 当分别指定泛型的类型和约束时,使用 where 会更清晰
impl <A, D> MyTrait<A, D> for YourType where
A: TraitB + TraitC,
D: TraitE + TraitF {}
其实目前 Golang 中的范型也是采用了这种方式来对类型做限制;
但是 Golang 中的范型和 Rust 中还是非常不一样的!
<font color="#f00">**Rust 中的范型和 C++ 的实现方式非常类似,即:**</font>
<font color="#f00">**对每一种具体类型生成其对应的代码,而非类似于 Java 中的类型擦除后进行类型转换,从而实现了:`零成本抽象`;**</font>
<font color="#f00">**同时,Rust 在编译时会分析究竟有哪些类型满足了范型约束,而只为那些满足了约束的具体类型实现方法!**</font>
<br/>
经过上面对范型约束的讲解,我们可以为实现了 Debug Trait 的、类型为范型 <T> 元素实现遍历打印的方法:
impl<T: Debug> LinkedList<T> {
pub fn traverse(&self) {
print!("{{ ");
for (idx, x) in self.iter().enumerate() {
print!(" [{}: {:?}] ", idx, *x)
}
println!(" }}");
}
}
此时:
如果具体的类型 T 实现了 Debug Trait,则 Rust 编译器会自动的为装有该类型的链表生成上面的方法;
而如果类型 T 并未实现 Debug Trait,此时 Rust 编译器不会为其对应的链表类型生成上面的方,此时如果在此链表上调用了 traverse 方法,编译器会报错,从而保证了正确的类型约束!
在这里,可能有些同学会有一些疑问:为什么不直接使用 #[derive] 让编译器自动帮我们生成打印链表的方法?
例如:
#[derive(Debug)]
impl<T> LinkedList<T> {
......
}
然而,这是不可能的!
因为在我们的双向链表中:相邻的两个节点均为循环引用!
即:节点A ↔ 节点B
因此如果使用编译器为我们生成的代码,我们将会陷入死循环,永远也无法退出输出循环!
关于引用循环,见:
<br/>
回顾之前,我们为 IntoIter 实现了 Drop Trait;
这是因为: IntoIter 获取了链表的完整所有权,因此需要代替链表管理其内部元素的内存(或者说是生命周期);
现在,我们还需要为链表本身实现 Drop Trait:
<font color="#f00">**以确保在链表退出其作用域后(此后再也无法访问此链表),内部元素的内存能够正常的被释放;**</font>
这里在实现时,参考了 Rust 源码中 LinkedList 中 Drop Trait的实现:
impl<T> Drop for LinkedList<T> {
fn drop(&mut self) {
struct DropGuard<'a, T>(&'a mut LinkedList<T>);
impl<'a, T> Drop for DropGuard<'a, T> {
fn drop(&mut self) {
// Continue the same loop we do below. This only runs when a destructor has
// panicked. If another one panics this will abort.
while self.0.pop_front().is_some() {}
}
}
while let Some(node) = self.pop_front() {
let guard = DropGuard(self);
drop(node);
mem::forget(guard);
}
println!("LinkedList dropped!")
}
}
在这里,我们定义了一个 DropGuard,其内部只有 LinkedList 类型的属性,并再次为其也实现了 Drop Trait:
impl<'a, T> Drop for DropGuard<'a, T> {
fn drop(&mut self) {
// Continue the same loop we do below. This only runs when a destructor has
// panicked. If another one panics this will abort.
while self.0.pop_front().is_some() {}
}
}
此处如此设计的原因是:
确保在执行下面这段释放链表元素占用内存的代码时:
while let Some(node) = self.pop_front() {
let guard = DropGuard(self);
drop(node);
mem::forget(guard);
}
println!("LinkedList dropped!")
如果出现了 panic,则此时 DropGuard 可以再次尝试释放内存;
而释放链表元素本身的代码非常简单,这里不再赘述;
为链表实现了 Drop Trait 之后,我们可以很简单的为其实现 clear 方法,而无需担心内存泄露,下面我们来实现 clear 方法;
<br/>
clear 方法非常简单:
pub fn clear(&mut self) {
*self = Self::new();
}
这是得益于我们为双向链表实现了 Drop Trait;
因此,我们可以直接创建一个新的空双向链表来直接覆盖原链表,来实现 clear() 方法;
而原链表在退出作用域之后会自动调用其 drop 方法,清空内部的节点以及对应元素,释放内存!
<br/>
在 Rust 中,我们可以很方便的添加测试用例(甚至是在同一个文件中);
下面是为链表添加的一些测试用例:
#[cfg(test)]
mod test {
use crate::list::linked_list::LinkedList;
#[test]
fn test_compiling() {}
#[test]
fn test_push_and_pop() {
let mut list = _new_list_i32();
assert_eq!(list.length, 5);
list.traverse();
assert_eq!(list.pop_front(), Some(-1));
assert_eq!(list.pop_back(), Some(i32::MAX));
assert_eq!(list.length, 3);
list.traverse();
}
#[test]
fn test_peak() {
let mut list = _new_list_string();
assert_eq!(list.peek_front(), Some(&String::from("abc")));
assert_eq!(list.peek_back(), Some(&String::from("hij")));
let cur = list.peek_front_mut();
assert_eq!(cur, Some(&mut String::from("abc")));
cur.map(|x| x.push(' '));
let cur = list.peek_back_mut();
assert_eq!(cur, Some(&mut String::from("hij")));
cur.map(|x| x.push(' '));
assert_eq!(list.peek_front(), Some(&String::from("abc ")));
assert_eq!(list.peek_back(), Some(&String::from("hij ")));
assert_eq!(list.length, 3);
list.traverse();
}
#[test]
fn test_get_idx() {
let list = _new_list_i32();
assert_eq!(list.get_by_idx(2).unwrap(), Some(&456));
assert_eq!(list.get_by_idx(3).unwrap(), Some(&789));
print!("before change: ");
list.traverse();
let cur = list.get_by_idx_mut(2).unwrap().unwrap();
assert_eq!(cur, &mut 456);
*cur <<= 1;
print!("after change: ");
list.traverse();
assert_eq!(list.get_by_idx(2).unwrap(), Some(&(456 << 1)));
}
#[test]
fn test_get_idx_err() {
let list = _new_list_i32();
assert!(list.get_by_idx(99).is_err());
assert!(list.get_by_idx_mut(99).is_err());
}
#[test]
fn test_insert_idx() {
let mut list = LinkedList::new();
list.push_back(String::from("1"));
list.push_back(String::from("2"));
list.push_back(String::from("3"));
list.insert_by_idx(1, String::from("99")).unwrap();
list.traverse();
assert_eq!(list.get_by_idx(0).unwrap(), Some(&String::from("1")));
assert_eq!(list.get_by_idx(1).unwrap(), Some(&String::from("99")));
}
#[test]
fn test_insert_idx_err() {
let mut list = LinkedList::new();
assert!(list.insert_by_idx(99, String::from("99")).is_err());
}
#[test]
fn test_remove_idx() {
let mut list = LinkedList::new();
list.push_back(String::from("1"));
list.push_back(String::from("2"));
list.push_back(String::from("3"));
let removed = list.remove_by_idx(1).unwrap();
list.traverse();
assert_eq!(removed, String::from("2"));
assert_eq!(list.get_by_idx(0).unwrap(), Some(&String::from("1")));
assert_eq!(list.get_by_idx(1).unwrap(), Some(&String::from("3")));
}
#[test]
fn test_remove_idx_err() {
let mut list: LinkedList<i32> = LinkedList::new();
assert!(list.remove_by_idx(99).is_err());
}
#[test]
fn test_contains() {
let list = _new_list_i32();
assert!(list.contains(&-1));
assert!(!list.contains(&-2));
}
#[test]
fn test_clear() {
let mut list = _new_list_zst();
assert_eq!(list.length(), 3);
list.clear();
assert_eq!(list.length(), 0);
}
#[test]
fn test_iterator() {
let mut list1 = _new_list_i32();
print!("before change: ");
list1.traverse();
list1.iter_mut().for_each(|x| *x = *x - 1);
print!("after change: ");
list1.traverse();
let list2 = _new_list_string();
let list2_to_len = list2.into_iter().map(|x| x.len()).collect::<Vec<usize>>();
println!(
"transform list2 into len vec, list2_to_len: {:?}",
list2_to_len
);
// Compiling err:
// list2.traverse()
}
struct ZeroSizeType {}
fn _new_list_i32() -> LinkedList<i32> {
let mut list = LinkedList::new();
list.push_front(456);
list.push_front(123);
list.push_back(789);
list.push_front(-1);
list.push_back(i32::MAX);
list
}
fn _new_list_string() -> LinkedList<String> {
let mut list = LinkedList::new();
list.push_front(String::from("def"));
list.push_front(String::from("abc"));
list.push_back(String::from("hij"));
list
}
fn _new_list_zst() -> LinkedList<ZeroSizeType> {
let mut list = LinkedList::new();
list.push_front(ZeroSizeType {});
list.push_front(ZeroSizeType {});
list.push_back(ZeroSizeType {});
list
}
}
执行下面的命令即可进行测试:
$ cargo test
Compiling collection v0.1.0 (/Users/kylinkzhang/self-workspace/rust-learn/collection)
Finished test [unoptimized + debuginfo] target(s) in 1.18s
Running unittests (target/debug/deps/collection-617cd44adb150cd7)
running 12 tests
test list::linked_list::test::test_contains ... ok
test list::linked_list::test::test_clear ... ok
test list::linked_list::test::test_compiling ... ok
test list::linked_list::test::test_insert_idx_err ... ok
test list::linked_list::test::test_get_idx ... ok
test list::linked_list::test::test_get_idx_err ... ok
test list::linked_list::test::test_insert_idx ... ok
test list::linked_list::test::test_peak ... ok
test list::linked_list::test::test_remove_idx ... ok
test list::linked_list::test::test_remove_idx_err ... ok
test list::linked_list::test::test_iterator ... ok
test list::linked_list::test::test_push_and_pop ... ok
test result: ok. 12 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests collection
running 2 tests
test src/list/linked_list.rs - list::linked_list::LinkedList<T>::contains (line 289) ... ok
test src/list/linked_list.rs - list::linked_list::LinkedList<T>::peek_front (line 141) ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 1.39s
除了会执行由 mod test 声明的测试用例之外,cargo test 还会测试代码注释中的测试用例;
例如:
/// Returns `true` if the `LinkedList` contains an element equal to the given value.
///
/// This operation should compute in *O*(*n*) time.
///
/// # Examples
///
///
/// use collection::list::linked_list::LinkedList; /// /// let mut list = LinkedList::new(); /// /// list.push_back(0); /// list.push_back(1); /// list.push_back(2); /// /// assert_eq!(list.contains(&0), true); /// assert_eq!(list.contains(&10), false); /// ``` pub fn contains(&self, elem: &T) -> bool where T: PartialEq<T>, { self.iter().any(|x| x == elem) }
另外,非常值得注意的是,我在测试用例中**特别加入了对 ZST(Zero-Size Type) 的测试;**
这个测试是非常重要的,因为在 Rust 中充斥着大量[零大小类型 (ZSTs)](https://nomicon.purewhite.io/exotic-sizes.html#零大小类型-zsts)!
例如:
```rust
struct Nothing; // 无字段意味着没有大小
// 所有字段都无大小意味着整个结构体无大小!
struct LotsOfNothing {
foo: Nothing,
qux: (), // 空元组无大小
baz: [u8; 0], // 空数组无大小
}
就其本身而言,零尺寸类型(ZSTs)由于显而易见的原因是相当无用的;然而,就像 Rust 中许多奇怪的布局选择一样,它们的潜力在通用语境中得以实现:
<font color="#f00">**在 Rust 中,任何产生或存储 ZST 的操作都可以被简化为无操作(no-op)!**</font>
首先,存储它甚至没有意义——它不占用任何空间;另外,这种类型的值只有一个,所以任何加载它的操作都可以直接凭空产生它——这也是一个无操作(no-op),因为它不占用任何空间;
这方面最极端的例子之一是 Set 和 Map:
给定一个Map<Key, Value>,通常可以实现一个Set<Key>,作为Map<Key, UselessJunk>的一个薄封装;
在许多语言中,这仍然需要为无用的封装分配空间,并进行存储和加载无用封装的工作,然后将其丢弃;因为,通常情况下对于编译器来说,分析这些类型是否是有用的,是非常困难的!
然而在 Rust 中,我们可以直接说Set<Key> = Map<Key, ()>!
<font color="#f00">**而 Rust 可以静态地知道每个加载和存储都是无用的,而且没有分配有任何大小;其结果是,单例化的代码基本上是 HashSet 的自定义实现,而没有任何 HashMap 要支持值所带来的开销!**</font>
<font color="#f00">**安全的代码不需要担心 ZST,但是 Unsafe Rust 必须小心没有大小的类型的后果!特别是,指针偏移是无操作的,而分配器通常[需要一个非零的大小](https://doc.rust-lang.org/std/alloc/trait.GlobalAlloc.html#tymethod.alloc);**</font>
<font color="#f00">**因此在设计时需要特别注意:对 ZST 的引用(包括空片),就像所有其他的引用一样,必须是非空的,并且适当地对齐!**</font>
<font color="#f00">**解引用 ZST 的空指针或未对齐指针是[未定义的行为](https://nomicon.purewhite.io/what-unsafe-does.html),就像其他类型的引用一样;**</font>
更多关于 ZST 见:
<br/>
呼呼~!你终于在 Rust 中实现了一个令人满意的双向链表,并加入了大量的测试用例来保证其逻辑的正确性!
经过了实现这个双向链表,我想你应该能学到下面这么多内容:
<br/>
源代码:
相关书籍推荐:
<br/>