共识算法的概述;
视频:
<br/>
<!--more-->
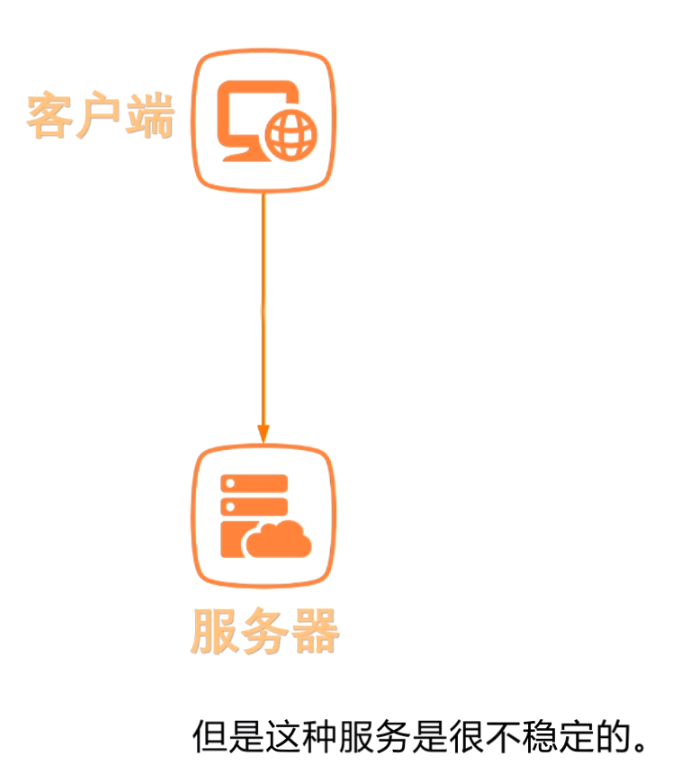
如上图所示,一台服务器给客户端提供服务,但是这种服务是很不稳定的;
因为如果这台服务器挂掉了,服务马上就不再可用!
因此,通常情况下会使用增加服务器副本的方式来保证系统的高可用;
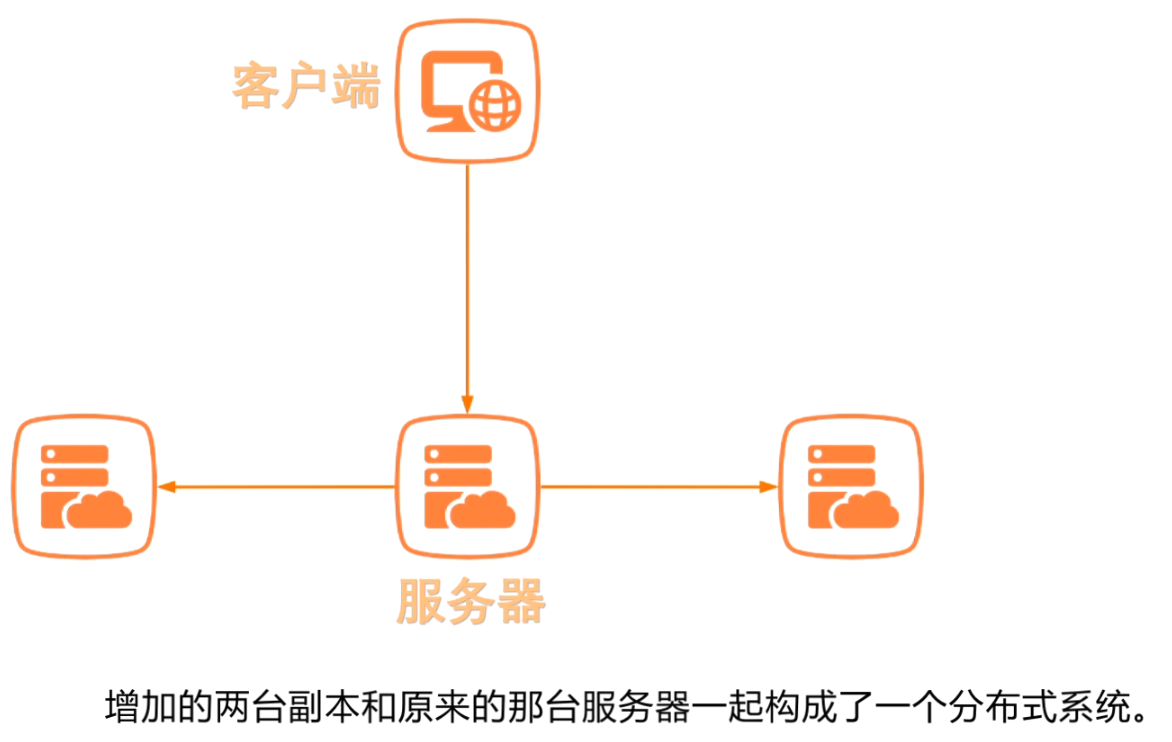
上面增加的两个副本和原来的服务器一起构成了一个分布式系统;
此时存在下面的一系列问题:
一个解决思路是:
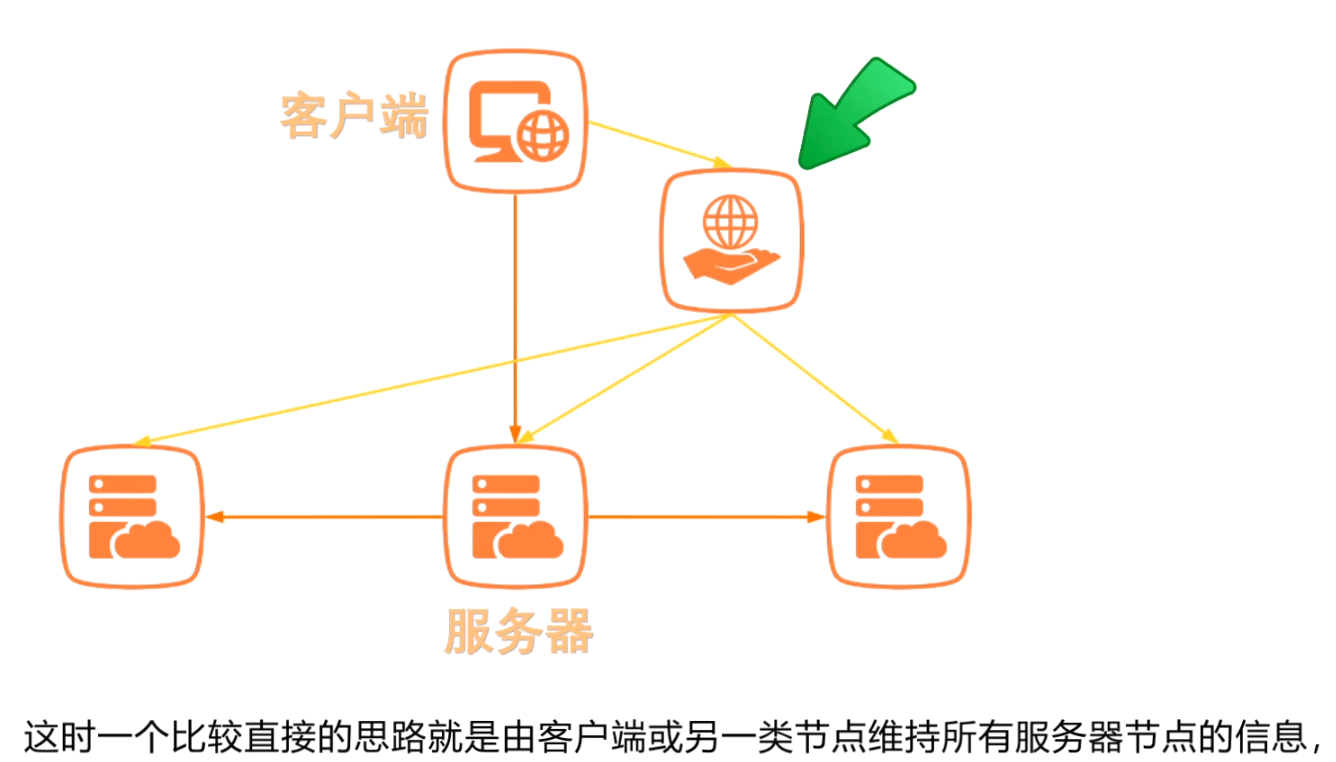
由客户端或者另一类节点维持所有服务器节点的信息,当发现主节点不可用时,他们就选择另一台服务器作为主(例如,Redis 中的 sentinel);
这类节点也被称为“管理节点”;
但是此方法存在另一个问题:如何保证管理节点的高可用性?
由于管理高可用节点的管理节点本身也存在高可用的问题,因此此方法存在无限循环的问题;
一个解决方法是引入外界因素,例如管理节点如果宕机,则人为介入为维护等:
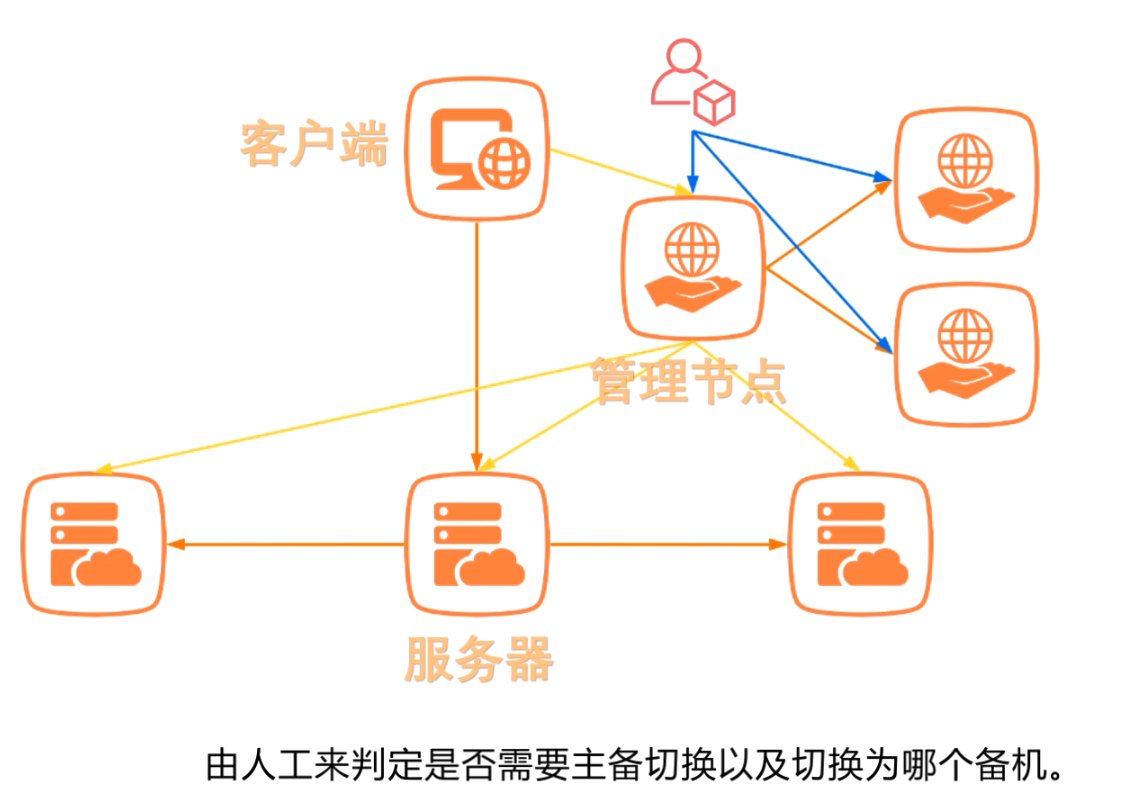
但是这种方法需要人工介入!
有没有一个不依赖外界因素来自动完成主节点选举,错误切换的方法呢?
答案就是:共识算法!
<br/>
共识算法中一个最重要的思路就是投票选举;
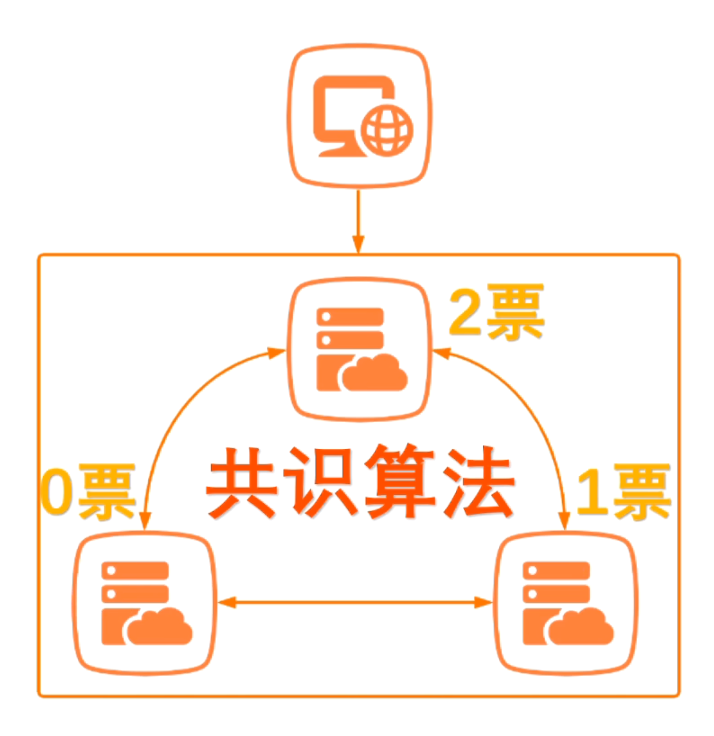
简单来讲就是:
负责处理客户端请求的主服务器,由集群中所有其他服务器投票选举出来;
只有得票超过半数的服务器才能够成为主服务器,从而负责处理客户端请求;
因此,只要集群中存在超过半数的服务器没有宕机,整个集群就能正常对外提供服务!
<br/>
Lamport 投稿 Paxos 被拒的故事…
论文 1990 年提交给了TOCS,直到 1996 年 由图灵奖获得者 Butler Lampson 发现,并在:
《How to build a Highly Available System Using Consensus》对算法进行了描述;
才让 Paxos 获得了广泛关注;
1998 年,TOCS 发表了:
《The part time parliament》
<br/>
由于 Paxos 算法难以理解并且难以落地,因此学术界和工业界在此基础之上进行了很多探索;
最重要的是 Google 的两篇 2006 年的论文:
Chubby:
Indeed, all working protocols for asynchronous consensus we have so far encountered have Paxos at their core.
目前为止所有异步共识算法的核心都是 Paxos;
chubby 发表后,在开源社区推出了与之对应的 ZooKeeper(其 ZAB 共识算法是 Paxos 的一个变种);
而 2014 年发表的 Raft 共识算法也是 Paxos 的一个更易理解的变种;
下面是一些演变:
其中,他们一个一致的改造点是:设计了一个有较长生命周期的 Leader!
对于 Basic Paxos 而言,每次决议一个新的问题,都要投票选举出一个对此问题的负责人,由此负责人处理此问题,因此每次出现新问题都要重新进行一次投票选举;
而有长生命周期的 Leader 的方案是由集群选出一个 Leader,此 Leader 在他的任期内直接负责处理所有问题,只有 Leader 宕机或任期结束,才会重新进行一次投票选举;
显然,长生命周期的 Leader 的方案选举次数更少,也就是用于维持共识算法的代价更小,因此更适用于工业生产;
<br/>
共识算法的概述;
视频:
<br/>