在任意一门编程语言中,函数调用基本上都是非常常见的操作;
我们都知道,函数是由调用栈实现的,不同的函数调用会切换上下文;
但是,你是否好奇,对于一个函数调用而言,其底层到底是如何实现的呢?
本文讲解了函数调用的底层逻辑实现;
相关文章:
<br/>
<!--more-->既然要讲解函数调用的底层逻辑实现,那么汇编语言我们是绕不过的;
因此,首先来复习一下汇编相关的知识;
我们都知道,计算机只能读懂二进制指令,而汇编就是一组特定的字符,汇编的每一条语句都直接对应 CPU 的二进制指令,比如:mov rax, rdx 就是我们常见的汇编指令;
汇编语言就是通过一条条的 助记符 + 操作数 实现的,并且汇编指令经过汇编器(assemble,例如 Linux 下的 as)转变为实际的 CPU 二进制指令;
<br/>
上面讲的有些空洞,来看一个实际的例子:
; 将寄存器rsp的值存储到寄存器rbp中
mov rbp, rsp
; 将四个字节的4存储到地址为rbp-4的栈上
mov DWORD PTR [rbp-4], 4
; 将rsp的值减去16
sub rsp, 16
<font color="#f00">**需要注意的是:汇编语言是和实际底层的 CPU 息息相关的;上面的汇编格式使用的便是 Intel 的语法格式;**</font>
常见的汇编语言有两种截然不同的语法:
<font color="#f00">**Intel 的格式是:`optcode destination, source`,类似于语法 int i = 4;**</font>
<font color="#f00">**而 AT&T 的格式是:`optcode source, destination`,直观理解为 move from source to destination;**</font>
若将上面的 Intel 汇编改写为 AT&T 汇编,则为:
movq %rsp, %rbp
movl $4, -4(%rbp)
subq $16, %rsp
可以看到,AT&T 汇编的另外一个特点是:有前缀和后缀;
比如:前缀%,$;后缀 q,l等等;
这些前缀后缀有特殊的意思,后文会讲解,不同的格式侧重点不太一样;
<br/>
下面是一些非常常用的汇编指令,在后文中都会用到:
| 指令 | 简单解释 |
|---|---|
| mov obj source | 把 source 赋值给 obj |
| call | 调用子程序 |
| ret | 子程序以 ret 结尾 |
| jmp | 无条件跳 |
| int | 中断指令 |
| add | 加法,a=a+b |
| or | 或运算 |
| xor | 异或运算 |
| shl | 逻辑左移 |
| ahr | 逻辑右移 |
| push xxx | 压xxx入栈 |
| pop xxx | xxx出栈 |
| inc | 加一 |
| dec | 减一 |
| sub a b | a=a-b |
| cmp ax,bx | 减法比较,修改标志位 |
<br/>
对于汇编语言,仅仅了解其语法内容是远远不够的!
由于汇编语言和 CPU 是息息相关的,因此在硬件层面我们还需要关注 CPU 的通用寄存器;
<font color="#f00">**在所有 CPU 体系架构中,每个寄存器通常都是有建议的使用方法的,而编译器也通常依照 CPU 架构的建议来使用这些寄存器,因而我们可以认为这些建议是强制性的;**</font>
<br/>
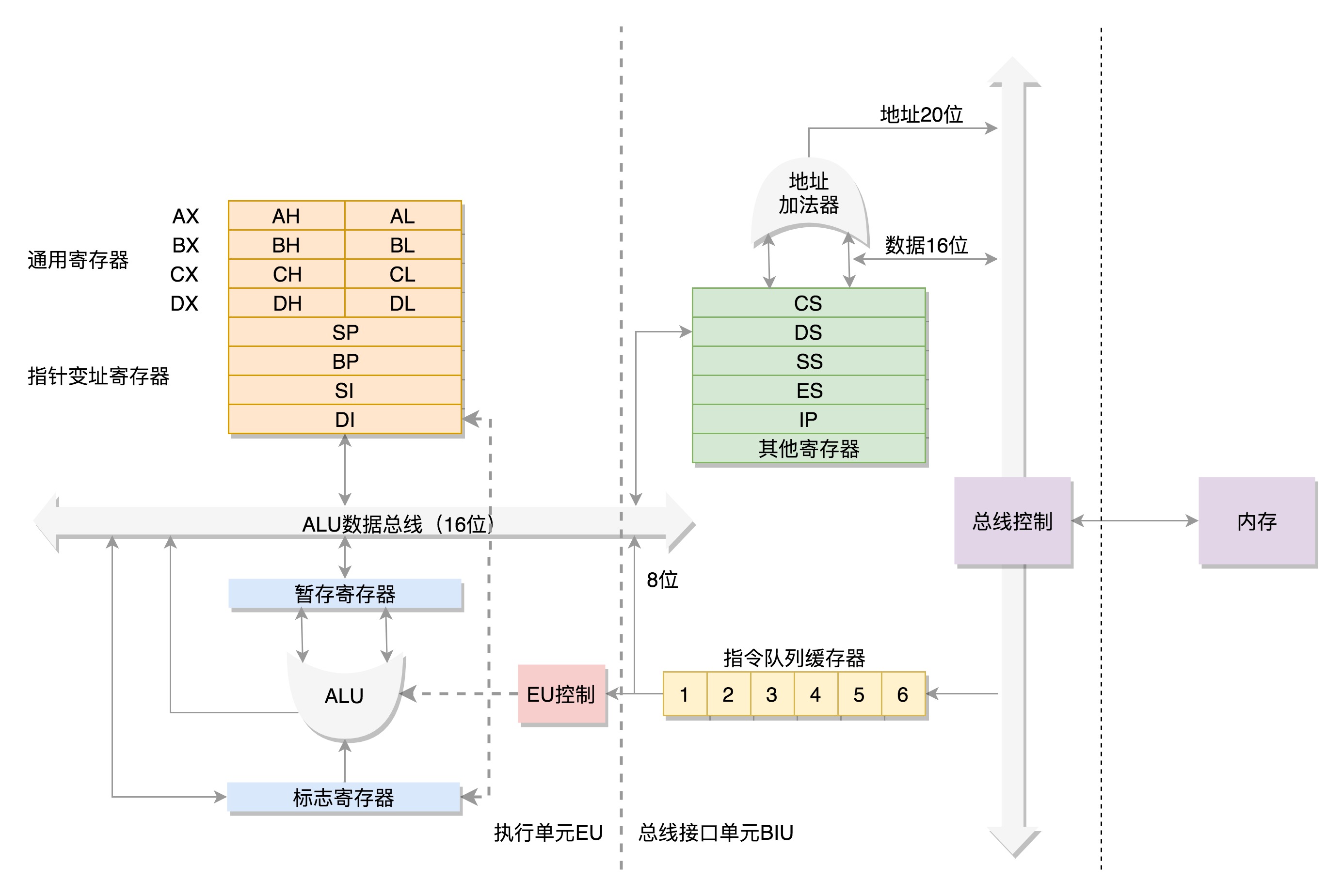
让我们把视线首先转移到 8086;
下图展示了在 8086 CPU 中的各个寄存器:
主要包括下面几类寄存器:
8086 处理器内部有 8 个 16 位的通用寄存器,也就是 CPU 内部的数据单元,分别是:AX、BX、CX、DX、SP、BP、SI、DI;
这些寄存器的作用主要是:暂存计算机过程中的数据;
另外,AX、BX、CX、DX 这四个寄存器又可以分为两个 8 位的寄存器来使用,分别是 AH、AL、BH、BL、CH、CL、DH、DL;
其中 H 表示高位(high),L 表示低位(low)的意思;
下面来看下控制单元:
<font color="#f00">**IP 寄存器就是指令指针寄存器(Instruction Pointer Register),指向代码段中下一条指令的位置;CPU 会根据它不断地从内存的代码段中取出指令并加载到 CPU 的指令队列中,然后交给运算单元去执行;**</font>
<font color="#f00">**CS、DS、SS、ES 这四个寄存器都是 16 位寄存器,用来存储进程的地址空间信息;**</font>
比如:
如何根据上述段寄存器找到所需的地址呢?
CS 和 DS 中都存放着一个段的起始地址,代码段的偏移值存放在 IP 寄存器中,而数据段的偏移值放在通用寄存器中;由于 8086 架构中总线地址是 20 位的,而段寄存器和 IP 寄存器以及通用寄存器都是 16 位的,所以为了得到 20 位的地址,先将段寄存器中起始地址左移 4 位,然后再加上偏移量,就得到了 20 位的地址;也正是由于偏移量是 16 位的,所以每个段最大的大小是 64 K 的;
另外,对于 20 位的地址总线来说,能访问到的内存大小最多也就只有 2^20 = 1 MB;
如果计算得到某个要访问的地址是 1MB+X,那么最后访问的是地址 X,因为地址线只能发送低 20 位的;
<br/>
8086CPU设置了一个:16位标志寄存器PSW(也叫FR),其中规定了 9 个标志位,用来存放运算结果特征和控制 CPU 操作;

9个标志位可以分为两类大类:
其中条件码包括:
控制标志位包括:
<br/>
接着,让我们步入32位机时代,来看看 x86 体系下的 CPU 寄存器:
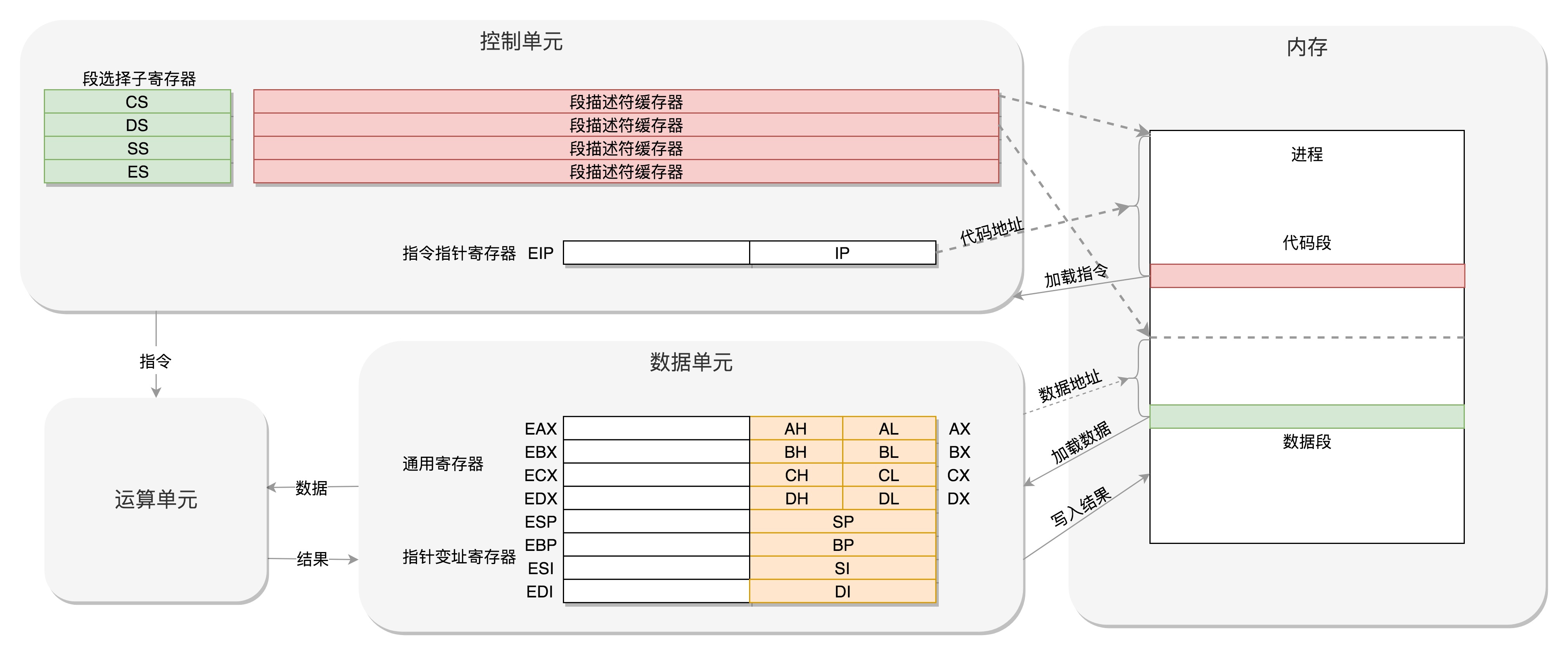
可以看到,为了使得运行在 8086 架构上的程序在移到 32 位架构之后也能执行,32 位架构对 8086 架构进行了兼容:
关于选择子:
先根据段寄存器拿到段的起始地址,再根据段寄存器中保存的选择子,找到对应的段描述符,然后从这个段描述符中取出这个段的起始地址;就相当于由之前的直接找到段起始地址变成了间接找到段起始地址;这样改变之后,段起始地址会变得很灵活;
但是这样就跟原来的 8086 架构不兼容了,因此为了兼容 8086 架构,32 位架构中引入了实模式和保存模式:8086 架构中的方式就称为实模式,32 位这种模式就被称为保护模式;
当系统刚刚启动的时候,CPU 是处于实模式的,这个时候和 8086 模式是兼容的;当需要更多内存时,进行一系列的操作,将其切换到保护模式,这样就能使用 32 位了;
模式可以理解为:CPU 和操作系统的一起干活的模式:
- <font color="#f00">**在实模式下,两者约定好了这些寄存器是干这个的,总线是这样的,内存访问是这样的;**</font>
<font color="#f00">**在保护模式下,两者约定好了这些寄存器是干那个的,总线是那样的,内存访问是那样的;**</font>
这样操作系统给CPU下命令,CPU按照约定好的,就能得到操作系统预料的结果,操作系统也按照约定好的,将一些数据结构,例如段描述符表放在一个约定好的地方,这样CPU就能找到。两者就可以配合工作了;
下面是 x86 平台下一些寄存器的调用特殊约定:
| 寄存器 | 说明 |
|---|---|
| EAX | 一般用作累加器(Adder),函数调用的返回值一般也放在这里 |
| EBX | 一般用作基址寄存器(Base) |
| ECX | 一般用作计数器(Count),比如for循环 |
| EDX | 一般用来存放数据(Data),读写I/O端口时,EDX 用来存放端口号 |
| ESP | 一般用作栈指针(Stack Pointer),栈顶指针,指向栈的顶部 |
| EBP | 一般用作基址指针(Base Pointer),栈底指针,指向栈的底部,通常用ebp+偏移量的形式来定位函数存放在栈中的局部变量 |
| ESI | 一般用作源变址(Source Index),字符串操作时,用于存放数据源的地址 |
| EDI | 一般用作目标变址(Destinatin Index),字符串操作时,用于存放目的地址的,和esi两个经常搭配一起使用,执行字符串的复制等操作 |
作为通用寄存器,过程调用中,调用者栈帧需要寄存器暂存数据,被调用者栈帧也需要寄存器暂存数据;
为防止调用过程中数据不会被破坏丢失,C/C++编译器遵守如下约定的规则:
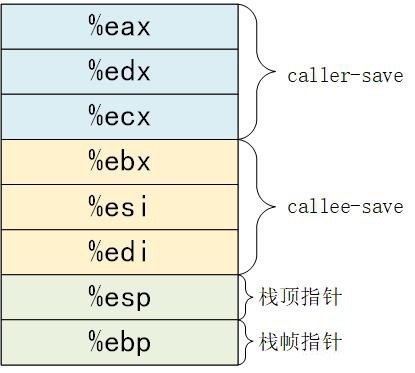
<font color="#f00">**当产生函数调用时,子函数内通常也会使用到通用寄存器,那么这些寄存器中之前保存的调用者(父函数)的值就会被覆盖!为了避免数据覆盖而导致从子函数返回时寄存器中的数据不可恢复,CPU 体系结构中就规定了通用寄存器的保存方式;**</font>
<font color="#f00">**如果一个寄存器被标识为`Caller Save`, 那么在进行子函数调用前,就需要由调用者提前保存好这些寄存器的值,保存方法通常是把寄存器的值压入堆栈中,调用者保存完成后,在被调用者(子函数)中就可以随意覆盖这些寄存器的值了;**</font>
<font color="#f00">**如果一个寄存被标识为`Callee Save`,那么在函数调用时,调用者就不必保存这些寄存器的值而直接进行子函数调用,进入子函数后,子函数在覆盖这些寄存器之前,需要先保存这些寄存器的值,即这些寄存器的值是由被调用者来保存和恢复的;**</font>
具体来讲:
<font color="#f00">**当该函数是处于调用者角色时,如果该函数执行过程中产生的临时数据会已存储在`%eax,%edx,%ecx`这些寄存器中,那么在其执行 call 指令之前会将这些寄存器的数据写入其栈帧内指定的内存区域,这个过程叫做调用者保存约定(Caller Save);**</font>
<font color="#f00">**当该函数是处于被调用者角色时,那么在其使用这些寄存器`%ebx,%esp,%edi`之前,那么该函数会保存这些寄存器中的信息到其栈帧指定的内存区域,这个过程叫被调用者保存约定;**</font>
<font color="#f00">**`%eax`总会被用作返回整数值;**</font>
<font color="#f00">**`%esp,%ebp`总被分别用着指向当前栈帧的顶部和底部,主要用于在当前函数推出时,将他们还原为原始值;往往会在栈帧开始处保存上一个栈帧的ebp,而esp是全栈的栈顶指针,一直指向栈的顶部;**</font>
<font color="#f00">**注:在 x86-64 架构下也是类似的约定!**</font>
<br/>
最后就是我们目前主流的 x86-64 架构了;
对于 x86-64 架构,最常用的有 16 个64位通用寄存器,各寄存器及用途如下所示:
| 寄存器 | 被调用者保存(Caller Save) | 简述 |
|---|---|---|
| %rax | 累加寄存器,通常用来执行加法(加法器,如 idiv 指令或 imul 指令等);<br />同时,函数调用的返回值也放在这里; |
|
| %rbx | YES | 通用数据存储(Miscellaneous) |
| %rcx | 计数寄存器(Count),比如for循环 | |
| %rdx | 存放数据(Data),读写I/O端口时,edx用来存放端口号 | |
| %rsp | 一般用作栈指针(Stack Pointer),栈顶指针,指向栈的顶部 | |
| %rbp | YES | 基址指针(Base Pointer),栈底指针,指向栈的底部,通常用ebp+偏移量的形式来定位函数存放在栈中的局部变量 |
| %rsi | 源变址(Source Index),字符串操作时,用于存放数据源的地址 | |
| %rdi | 目标变址(Destinatin Index),用于存放目的地址的,和esi两个经常搭配一起使用,执行字符串的复制等操作 | |
| %r8 | ||
| %r9 | ||
| %r10 | ||
| %r11 | ||
| %r12~r15 | YES | |
| %st0~st7 | 浮点寄存器组 | |
| XMM0~XMM15 | XMM寄存器组 |
从上面的表可以看到,除了扩展原来存在的通用寄存器,x64架构还引入了8个新的通用寄存器:r8-r15;
这些寄存器虽然都可以用,但是还是做了一些规定,如下:
同时,和上面 x32 架构类似这里也要区分 Caller Save 和 Callee Save 寄存器,即寄存器的值是由 调用者保存 还是由 被调用者保存;
<br/>
在 x32 的时代,通用寄存器少,参数传递都是通过入栈(汇编指令push)实现的(当然也有使用寄存器传递的,比如著名的C++ this指针使用ecx寄存器传递,不过能用的寄存器毕竟不多),相对 CPU 寄存器来说,访问太慢,函数调用的效率就不高;
而在 x86-64 时代,寄存器数量多了,CPU就可以利用额外的寄存器rdi、rsi、rdx、rcx、r8、r9来存储参数!
寄存器传参的好处是速度快,减少了对内存的读写次数。
<font color="#f00">**注:多于6个的参数,依然还是通过入栈实现传递;**</font>
因此在x86_64位机器上编程时,需要注意:
具体使用栈还是用寄存器传参数,这个不是编程语言决定的,而是编译器在编译生成CPU指令时决定的;
如果编译器非要在x64架构CPU上使用线程栈来传参那也不是不行,这个对高级语言是无感知的;
<br/>
上述的寄存器名字都是 64 位的名字,对于每个寄存器,我们还可以只使用它的一部分,并使用另一个新的名字:
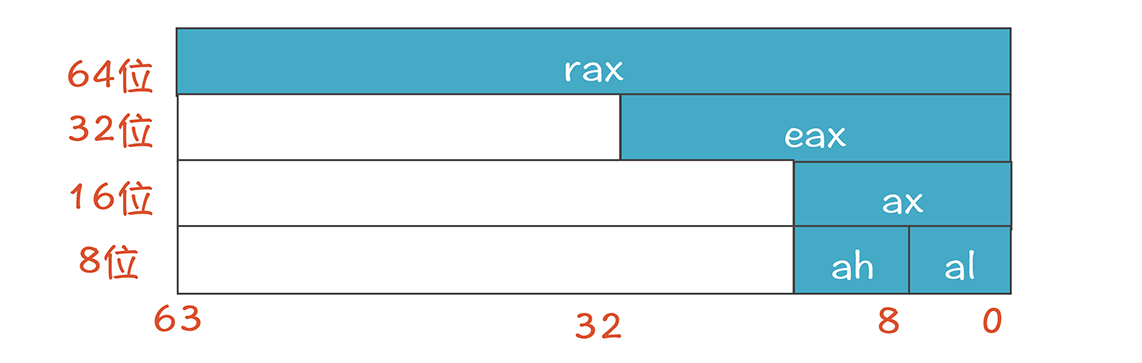
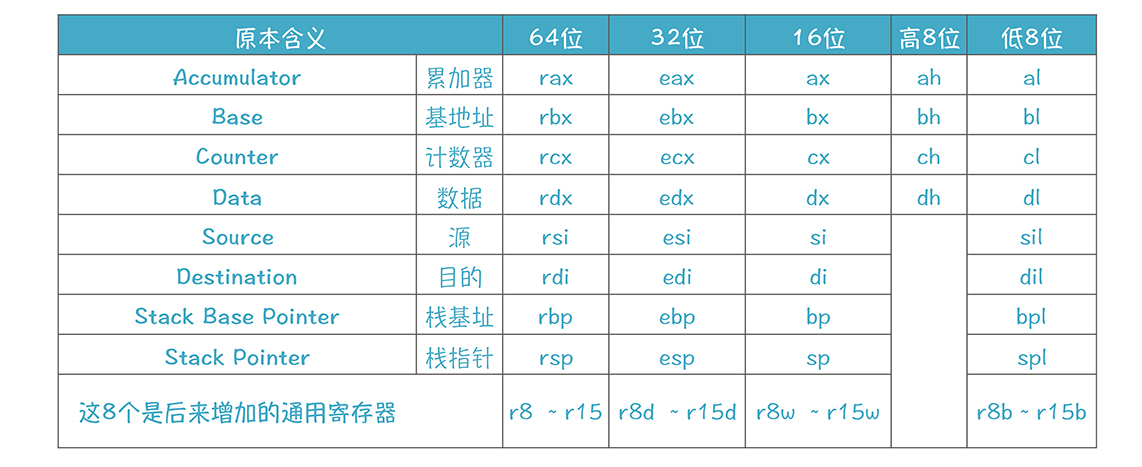
下面这些寄存器可能也会需要用到其他寄存器:
和上面所述的 x86 架构类似,在 x86-64 架构下也存在实模式;
更多关于 x86-64 处理器架构:
<br/>
上文简单复习了一下汇编和寄存器相关的内容;
下面来正式来看看函数调用的底层是如何实现的!
注:这里的说明采用的是:
-O0;intel 架构;子函数调用时,调用者与被调用者的栈帧结构如下图所示:
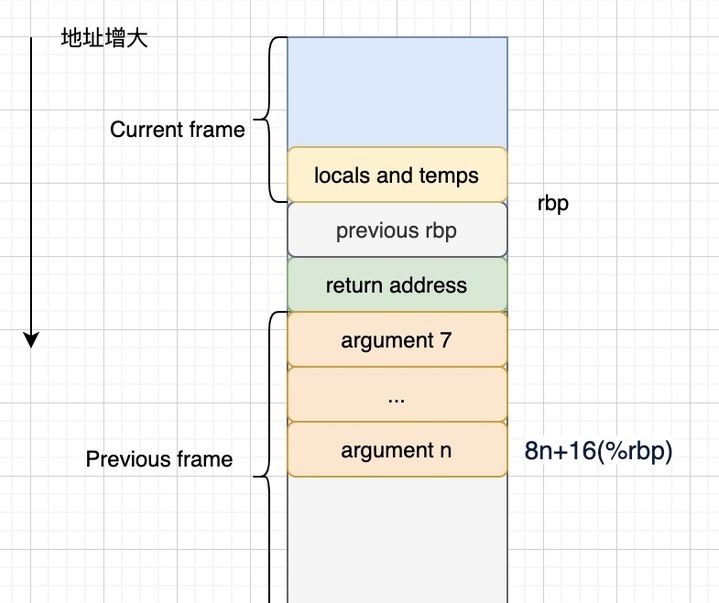
在子函数调用时,需要切换上下文使得当前调用栈进入到一个新的执行中:
保存返回地址和保存上一栈帧的 %rbp 都是为了函数返回时,恢复父函数的栈帧结构(保存函数调用上下文);
在使用高级语言进行函数调用时,由编译器自动完成上述整个流程;甚至对于”Caller Save” 和 “Callee Save” 寄存器的保存和恢复,也都是由编译器自动完成的;
<font color="#f00">**需要注意的是:父函数中进行参数压栈时,顺序是从后向前进行的(调用栈空间都是从大地址向小地址延伸,这一点刚好和堆空间相反);**</font>
这一行为并不是固定的,是依赖于编译器的具体实现的;
至少在 GCC 中,使用的是从后向前的压栈方式,这种方式便于支持类似于
printf(“%d, %d”, i, j)这样的使用变长参数的函数调用;
以下面的函数为例:
void func() {}
void my_func() {
func();
}
对应的汇编为:
func():
push rbp
mov rbp, rsp
nop
pop rbp
ret
my_func():
push rbp
mov rbp, rsp
call func()
nop
pop rbp
ret
在函数 my_func 和 func 中:开始的两句就是由编译器默认生成的切换上下文语句(函数 my_func 中也存在这个语句是因为它最终也会被其他函数s调用);
当 my-func 函数调用 func 函数时:
call 指令,保存返回地址,并跳转至 func 函数起始地址(这里没有压栈调用参数是因为 func 入参为空);push rbp 和 mov rbp, rsp 保存上下文,随后开始执行 func 函数中的逻辑;nop 指令;函数开头的
push rbp和mov rbp, rsp又叫做函数的序言(prologue),几乎每个函数一开始都会该指令;它和函数最后的
pop rbp和ret(epilogue)起到维护函数的调用栈的作用;
接下来,顺理成章的我们来看一下函数的返回过程;
<br/>
函数返回时,我们只需要得到函数的返回值(保存在 %rax 中),之后就需要将栈的结构恢复到函数调用之差的状态,并跳转到父函数的返回地址处继续执行即可;
由于函数调用时已经保存了返回地址和父函数栈帧的起始地址,要恢复到子函数调用之前的父栈帧,我们只需要执行以下两条指令:
pop rbp
ret
首先执行 pop rbp 指令,直接将调用栈地址恢复至调用函数之前的状态;
随后通过 ret 指令跳转至返回地址处并执行;
<br/>
在函数调用中,另一个需要关注的便是函数参数的传递:入参传递以及返回值传递;
函数在计算的时候,存储数据的地方总共有三个:
int i = 4,这个4存储于程序本身,在汇编里面又叫立即数(immediate number);知道了数据的存储地方,那么数据的传递就分为以下四个方面:
注意:数据不能从内存直接传递到内存,如果需要从内存传递到内存,要以寄存器为中介!
同时需要注意的是:数据是有大小的!
比如:一个word是两个字节(16bit),double words是四个字节(32bit),quadruple words是八个字节(64bit);
所以传递数据的时候,要知道传递的数据大小:
<font color="#f00">**Intel 格式的汇编会在数据前面说明数据大小:比如 `mov DWORD PTR [rbp-4], 4`,意思是将一个4字节的 4 存储到栈上(地址为rbp-4);**</font>
<font color="#f00">**而AT&T 格式是通过指令的后缀来说明,同样的指令为`movl $4, -4(%rbp)`;并且存储的地方,AT&T汇编是通过前缀来区别,比如%q前缀表示寄存器,`$` 表示立即数,`()`表示内存;**</font>
学习了数据的传递方式之后,让我们看看函数的调用习惯;
<br/>
之前我们简单学习了一下 Caller 和 Callee 的区别,在这里我们会深入的学习;
首先,什么是函数调用约定?
在Caller调用Callee时,要将参数(arguements)传递给Callee,一个函数可以接收多个参数,而Caller与Callee之间约定的每个参数的应该怎么传递就是调用习惯;这样,Callee 才能到指定的位置获取到相应的参数;
比如下面的代码:
int square(int num) {
return num * num;
}
int main() {
int i = 4;
int j = square(i);
}
在main函数中调用square,参数i是如何传递到square中的?
上面的代码对应的汇编如下:
square(int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], edi
mov eax, DWORD PTR [rbp-4]
imul eax, eax
pop rbp
ret
main:
push rbp
mov rbp, rsp
sub rsp, 16
mov DWORD PTR [rbp-4], 4
mov eax, DWORD PTR [rbp-4]
mov edi, eax
call square(int)
mov DWORD PTR [rbp-8], eax
mov eax, 0
leave
ret
通过上面的汇编,我们可以知道:
在main里面,4先存到栈上(mov DWORD PTR [rbp-4], 4),然后存在edi里面(mov eax, DWORD PTR [rbp-4]、mov edi, eax),而sqaure函数直接就从edi里面读取4的值了!
这就说明:参数 4 是通过寄存器 edi 传给了callee (sqaure) ;
可能有同学会以为,从代码看,参数不是直接就传给了sqaure吗?
<font color="#f00">**实际上,在汇编中,这个变量 i 是不存在的,只有寄存器和内存,因此我们需要约定好入参 i 的值存在哪里;**</font>
下面让我们来详细看看这些约定、常见寄存器负责传递的参数以及一些作用(前文简要介绍了一些):
| 寄存器 | 作用 |
|---|---|
| <font color="#00f">**%rax**</font> | <font color="#00f">传递返回值</font> |
| <font color="#00f">**%rdi**</font> | <font color="#00f">传递第一个参数</font> |
| <font color="#00f">**%rsi**</font> | <font color="#00f">传递第二个参数</font> |
| <font color="#00f">**%rdx**</font> | <font color="#00f">传递第三个参数</font> |
| <font color="#00f">**%rcx**</font> | <font color="#00f">传递第四个参数</font> |
| <font color="#00f">**%r8**</font> | <font color="#00f">传递第五个参数</font> |
| <font color="#00f">**%r9**</font> | <font color="#00f">传递第六个参数</font> |
| <font color="#0f0">**%rsp**</font> | <font color="#0f0">栈顶指针</font> |
| <font color="#0f0">**%rbx**</font> | <font color="#0f0">临时变量</font> |
| <font color="#0f0">**%rbp**</font> | <font color="#0f0">栈基址</font> |
| <font color="#0f0">**%r12~r15**</font> | <font color="#0f0">临时变量</font> |
| %rip | 存储下一条要执行的指令 |
| %eflags | flags 和 条件判断的结果标志位 |
| XMM0 | 用来传递第一个double参数 |
| XMM1 | 用来传递第二个double参数 |
在上面的列表中:
同时,如果函数返回比较大的对象,那么第一个参数rdi会用来传递存储这个对象的地址(这个地址是由caller分配的);
有了这些基础,我们就更容易理解C++中的copy elision了;
相关阅读:
<br/>
在知道了函数参数是如何传递的之后,我们来更升一级;
下面根据具体代码来看一看我们经常使用的 if、for、while 等控制结构在底层是如何实现的;
if, while循环等控制结构,在汇编里面,都是基于判定语句,跳转语句实现的:
做一个计算,检查相应的flag,然后根据flag的值确定要跳转到哪里;
比如下面的 if 语句:
int multiply(int j) {
if (j > 6) {
return j*2;
} else {
return j*3;
}
}
对应的汇编语句如下:
multiply(int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], edi
cmp DWORD PTR [rbp-4], 6
jle .L2
mov eax, DWORD PTR [rbp-4]
add eax, eax
jmp .L3
.L2:
mov edx, DWORD PTR [rbp-4]
mov eax, edx
add eax, eax
add eax, edx
.L3:
pop rbp
ret
最前面和最后两条命令就是函数调用中的上下文切换,这个在前文中已经详细说明了;
函数的逻辑从第三条语句真正开始:
mov DWORD PTR [rbp-4], edi 表示将寄存器 edi 中的4个字节的值(DWORD PTR)移至 [rbp-4] 对应内存地址中;
这里和上面所讲述的参数传递的约定是保持一致的,因为我们的入参
j是int类型,只有32位,因此使用的是edi寄存器来传递的参数;
随后,使用 cmp 指令将内存中的数和立即数 6 进行比较(即,j>6),此指令会改变标志寄存器 %eflags 的状态;
然后 jle 会利用标志寄存器 %eflags 中的状态进行跳转:
j<=6,跳转至 .L2;j>6的场景);无论是向下执行还是跳转至 .L2 执行,最终两者都会执行至 .L3 并返回;
<br/>
下面再来看一个 for 循环的例子:
int add(int j) {
int ret = 0;
for (int i = 0; i < j; ++i) {
ret+= i;
}
return ret;
}
对应的汇编如下:
add(int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-20], edi
mov DWORD PTR [rbp-4], 0
mov DWORD PTR [rbp-8], 0
jmp .L2
.L3:
mov eax, DWORD PTR [rbp-8]
add DWORD PTR [rbp-4], eax
add DWORD PTR [rbp-8], 1
.L2:
mov eax, DWORD PTR [rbp-8]
cmp eax, DWORD PTR [rbp-20]
jl .L3
mov eax, DWORD PTR [rbp-4]
pop rbp
ret
从上面的汇编我们可以看到,入参 j 依旧是由寄存器 edi传递,并存储在了内存 [rbp-20] 中;
随后两行分别初始化了参数 ret:[rbp-4]、i:[rbp-8];
紧接着,指令直接跳转至 .L2 处,首先比较了 [rbp-8] 和 [rbp-20] 中的值(即比较 i 和 j):如果 i<j 则跳转至 .L3 处执行;
这里的判断是符合 for 循环的逻辑的:在进入 for 循环之前首先会判断一次条件;
.L3 代码块是 for 循环的真正逻辑:
; ret += i;
mov eax, DWORD PTR [rbp-8]
add DWORD PTR [rbp-4], eax
; ++i
add DWORD PTR [rbp-8], 1
其他控制结构的逻辑也是类似的,这里不再赘述了!
<br/>
本文首先简要复习了汇编以及通用寄存器相关的内容,随后进入到文章主题:函数调用;
在函数调用中讲述了函数调用中的调用和返回细节、上下文切换保护、函数传递等内容;
最后略微引申了函数中常见控制结构的底层实现;
<br/>
相关文章:
文章参考:
<br/>