一个蚂蚁金服-内推的面试题[本内容来自于互联网]
<br/>
<!--more-->张凯, EE –> CS, 本科:
<br/>
① 序列化和反序列化
Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程;
序列化:对象序列化的最主要的用处就是在传递和保存对象的时候,保证对象的完整性和可传递性。序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中。序列化后的字节流保存了Java对象的状态以及相关的描述信息。序列化机制的核心作用就是对象状态的保存与重建
反序列化:客户端从文件中或网络上获得序列化后的对象字节流后,根据字节流中所保存的对象状态及描述信息,通过反序列化重建对象
本质上讲,序列化就是把实体对象状态按照一定的格式写入到有序字节流,反序列化就是从有序字节流重建对象,恢复对象状态
② 为什么需要序列化与反序列化
当两个Java进程进行通信时,实现进程间对象传送就需要Java序列化与反序列化
换句话说,一方面,发送方需要把这个Java对象转换为字节序列,然后在网络上传送;另一方面,接收方需要从字节序列中恢复出Java对象
③ Java序列化的好处
④ 序列化算法
⑤ Java实现序列化和反序列化
前提: 只有实现了Serializable或Externalizable接口(继承自Serializable)的类的对象才能被序列化,否则抛出异常
通过ObjectOutputStream和ObjectInputStream进行IO操作;
java.io.ObjectOutputStream:表示对象输出流;
它的writeObject(Object obj)方法可以对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中;
java.io.ObjectInputStream:表示对象输入流;
它的readObject()方法源输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回;
⑥ JDK类库中序列化的步骤
步骤一: 创建一个对象输出流,它可以包装一个其它类型的目标输出流,如文件输出流:
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("D:\\object.out"));
步骤二: 通过对象输出流的writeObject()方法写对象:
oos.writeObject(new User("Jasonkay", "123456", "male"));
⑦JDK类库中反序列化的步骤
步骤一: 创建一个对象输入流,它可以包装一个其它类型输入流,如文件输入流:
ObjectInputStream ois= new ObjectInputStream(new FileInputStream("object.out"));
步骤二: 通过对象输出流的readObject()方法读取对象:
User user = (User) ois.readObject();
<br/>
说明:为了正确读取数据,完成反序列化,必须保证向对象输出流写对象的顺序与从对象输入流中读对象的顺序一致
<br/>
<br/>
注意事项:
① 序列化时,只对对象的状态进行保存,而不管对象的方法;
② 当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口;
③ 当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化;
④ 并非所有的对象都可以序列化,至于为什么不可以,有很多原因了,比如:
- 安全方面,比如一个对象拥有private,public等field,对于一个要传输的对象,比如写到文件,或者进行RMI传输等等,在序列化进行传输的过程中,这个对象的private等域是不受保护的;
- 资源分配方面的原因,比如socket,thread类,如果可以序列化,进行传输或者保存,也无法对他们进行重新的资源分配,而且,也是没有必要这样实现;
⑤ 声明为static和transient类型的成员数据不能被序列化, 因为static代表类的状态,transient代表对象的临时数据
⑥ 序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。为它赋予明确的值。显式地定义serialVersionUID有两种用途:
- 在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的serialVersionUID;
- 在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
<font color="#f00">**⑦ 如果一个对象的成员变量是一个对象,那么这个对象的数据成员也会被保存!这是能用序列化解决深拷贝的重要原因;**</font>
<br/>
后记: 可扩展到Redis持久化序列化等(使用RedisTemplate)
<br/>
① synchronized作用
② synchronized的使用
③ 实现原理
<font color="#f00">**synchronized是基于JVM实现的, jvm基于进入和退出Monitor对象来实现方法同步和代码块同步**</font>
方法级的同步:
方法级的同步是隐式,即无需通过字节码指令来控制的,它的实现在方法调用和返回操作之中。JVM可以从方法常量池中的方法表结构(method_info Structure) 中的 ACC_SYNCHRONIZED 访问标志区分一个方法是否同步方法
当方法调用时,调用指令将会 检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先持有monitor(虚拟机规范中用的是管程一词), 然后再执行方法,最后在方法完成(无论是正常完成还是非正常完成)时释放monitor
代码块的同步:
代码块的同步是利用monitorenter和monitorexit这两个字节码指令, 它们分别位于同步代码块的开始和结束位置。当jvm执行到monitorenter指令时,当前线程试图获取monitor对象的所有权,如果未加锁或者已经被当前线程所持有,就把锁的计数器+1;当执行monitorexit指令时,锁计数器-1;当锁计数器为0时,该锁就被释放了。如果获取monitor对象失败,该线程则会进入阻塞状态,直到其他线程释放锁
<br>
这里要注意:
- synchronized是可重入的,所以不会自己把自己锁死
- synchronized锁一旦被一个线程持有,其他试图获取该锁的线程将被阻塞
<br/>
关于ACC_SYNCHRONIZED 、monitorenter、monitorexit指令,可以看一下下面的反编译代码:
public class SynchronizedDemo {
public synchronized void f(){ //这个是同步方法
System.out.println("Hello world");
}
public void g(){
synchronized (this){ //这个是同步代码块
System.out.println("Hello world");
}
}
public static void main(String[] args) {
}
}
使用javap -verbose SynchronizedDemo反编译class文件后得到:
Last modified 2020年2月5日; size 668 bytes
MD5 checksum fd97571040c8c4c02281674bc370cfce
Compiled from "SynchronizedDemo.java"
......
Constant pool:
#1 = Methodref #6.#19 // java/lang/Object."<init>":()V
#2 = Fieldref #20.#21 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #22 // Hello world
......
{
public top.jasonkayzk.mybatisplus.SynchronizedDemo();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 6: 0
public synchronized void f();
descriptor: ()V
flags: (0x0021) ACC_PUBLIC, ACC_SYNCHRONIZED /* 同步方法标志! */
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String Hello world
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 9: 0
line 10: 8
public void g();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter /* 同步块进入指令 */
4: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
7: ldc #3 // String Hello world
9: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
12: aload_1
13: monitorexit /* 同步块退出指令 */
14: goto 22
17: astore_2
18: aload_1
19: monitorexit /* 同步块退出指令 */
20: aload_2
21: athrow
22: return
Exception table:
from to target type
4 14 17 any
17 20 17 any
LineNumberTable:
line 13: 0
line 14: 4
line 15: 12
line 16: 22
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 17
locals = [ class top/jasonkayzk/mybatisplus/SynchronizedDemo, class java/lang/Object ]
stack = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 4
......
SourceFile: "SynchronizedDemo.java"
可以看到对于同步方法,反编译后得到ACC_SYNCHRONIZED 标志,对于同步代码块反编译后得到monitorenter和monitorexit指令
<br/>
④ JVM对synchronized的锁优化
Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本质又是依赖于底层的操作系统的Mutex Lock(互斥锁)来实现的
而操作系统实现线程之间的切换需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么Synchronized效率低的原因。因此,这种依赖于操作系统Mutex Lock所实现的锁我们称之为“重量级锁”
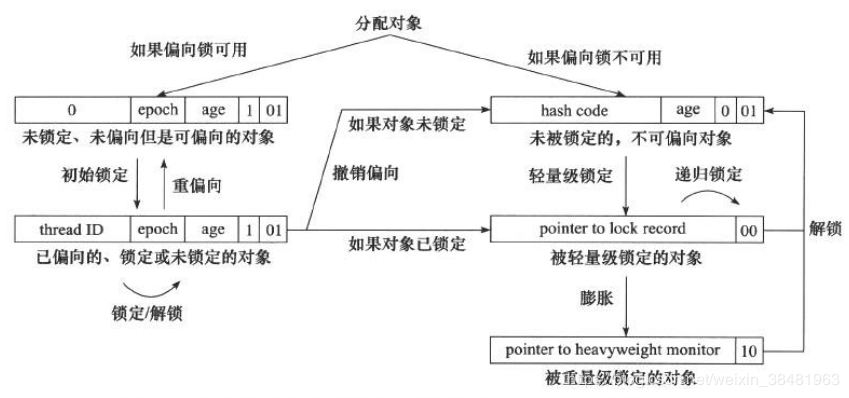
Java SE 1.6为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”, 锁一共有4种状态,级别从低到高依次是:
<font color="#f00">**锁可以升级但不能降级**</font>
<br/>
1.偏向锁
偏向锁是JDK1.6中引用的优化,它的目的是消除数据在无竞争情况下的同步原语,进一步提高程序的性能
偏向锁的获取:
当锁对象第一次被线程获取的时候,虚拟机会把对象头中的标志位设置为“01”,即偏向模式。同时使用CAS操作把获取到这个锁的线程ID记录在对象的Mark Word中,如果CAS操作成功, 持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作
偏向锁的释放:
偏向锁使用了遇到竞争才释放锁的机制。偏向锁的撤销需要等待全局安全点,然后它会首先暂停拥有偏向锁的线程,然后判断线程是否还活着,如果线程还活着,则升级为轻量级锁,否则,将锁设置为无锁状态
<br/>
2.轻量级锁
轻量级锁也是在JDK1.6中引入的新型锁机制, 它不是用来替换重量级锁的,它的本意是在没有多线程竞争的情况下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗
加锁过程:
解锁过程:
如果对象的Mark Word仍然指向线程的锁记录,那就用CAS操作将对象当前的Mark Word与线程栈帧中的Displaced Mark Word交换回来,如果替换成功,整个同步过程就完成了。如果替换失败,说明有其他线程尝试过获取该锁,那就要在释放锁的同时,唤醒被挂起的线程
如果没有竞争,轻量级锁使用CAS操作避免了使用互斥量的开销,但如果存在竞争,除了互斥量的开销外,还额外发生了CAS操作,因此在有竞争的情况下,轻量级锁比传统重量级锁开销更大
3.重量级锁
Synchronized的重量级锁是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本质又是依赖于底层的操作系统的Mutex Lock(互斥锁)来实现的。而操作系统实现线程之间的切换需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么Synchronized效率低的原因
4.自旋锁
互斥同步对性能影响最大的是阻塞的实现,挂起线程和恢复线程的操作都需要转入到内核态中完成,这些操作给系统的并发性能带来很大的压力
于是在阻塞之前,我们让线程执行一个忙循环(自旋),看看持有锁的线程是否释放锁,如果很快释放锁,则没有必要进行阻塞
5.锁消除
锁消除是指虚拟机即时编译器(JIT)在运行时,对一些代码上要求同步,但是检测到不可能发生数据竞争的锁进行消除
6.锁粗化
如果虚拟机检测到有这样一串零碎的操作都对同一个对象加锁,将会把加锁同步的范围扩展(粗化)到整个操作序列的外部
<br/>
<br/>
这个还真不熟悉, 做过的主要是Nginx和多个Tomcat的部署, 没有深究Tomcat集群同步问题
<br/>
转自: tomcat 集群怎么保证同步
集群的具体同步机制,tomcat共提供了两种:
① 集群增量会话管理器
这是一种全节点复制模式,全节点复制指的是集群中一个节点发生改变后会同步到其余全部节点。那么非全节点复制,顾名思义,指的是集群中一个节点发生改变后,只同步到其余一个或部分节点
除了这一特点,集群增量会话管理器还具有只同步会话增量的特点,增量是以一个完整请求为周期,也就是说会在一个请求被响应之前同步到其余节点上
② 集群备份会话管理器
全节点复制模式存在的一个很大的问题就是用于备份的网络流量会随着节点数的增加而急速增加,这也就是无法构建较大规模集群的原因
为了解决这个问题,tomcat提出了集群备份会话管理器。每个会话只有一个备份, 这样就可构建大规模的集群
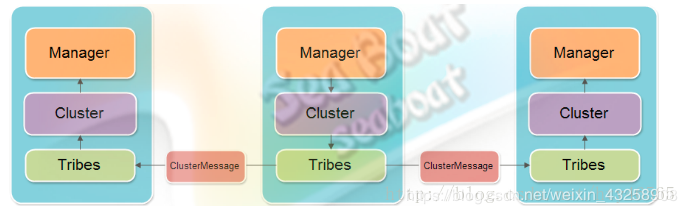
在上述无论是发送还是接收信息的过程中,使用到的组件主要有三个:
其余节点收到信息后,按照相反的流程一步步传到Manager,经过反序列化之后使该节点同步传递过来的操作信息。如图,假设我们访问的是中间的节点,该节点将信息同步出去。信息是以Cluster Message对象发送的
<br/>
Redis可以说的就太多了…, 我觉得比较重要的主要有:
答案见: Redis面试相关问题
<br/>
① update的时候加一个限制条件,count > 1
将要完成交易时, 由于事务的原子性, 如果某个客户update时为0, 则事务回滚, 操作无法完成;
<br/>
② 数据库加显式锁[低效率]
对读操作加上显式锁, 即在select ...语句最后加上for update
这样一来用户1在进行读操作时用户2就需要排队等待了, 但如果该商品很热门并发量很高那么效率就会大大的下降,怎么解决?
可以有条件有选择的在读操作上加锁,比如: 可以对库存做一个判断,当库存小于一个量时开始加锁,让购买者排队,这样一来就解决了超卖现象
<br/>
③ 加乐观锁
更新库存时,必须更新versionId字段,若两个用户同时使得versionId = 3,并提交,那么有一个用户一定被回滚
<br/>
乐观锁实现
使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式, 即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的
version字段来实现
- 当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一
- 当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据
例如:
数据库表task设计: 有三个字段,分别是id, value, version
先读task表的数据(实际上这个表只有一条记录),得到version的值为versionValue
每次更新task表中的value字段时,为了防止发生冲突,需要这样操作
update task set value = newValue, version = versionValue + 1 where version = versionValue;<font color="#f00">**只有这条语句执行了,才表明本次更新value字段的值成功**</font>
假设有两个节点A和B都要更新task表中的value字段值:
差不多在同一时刻,A节点和B节点从task表中读到的version值为2,那么A节点和B节点在更新value字段值的时候,都操作 update task set value = newValue,version = 3 where version = 2;
而实际上只有1个节点执行该SQL语句成功,假设A节点执行成功,那么此时task表的version字段的值是3,B节点再操作update task set value = newValue,version = 3 where version = 2;这条SQL语句是不执行的,这样就保证了更新task表时不发生冲突
<br/>
Java中int为32位: -2^31^ - 2^31-1^,即-2147483648 - 2147483647
可以用Integer.MIN_VALUE和Integer.MAX_VALUE表示;
<br/>
可见github: https://github.com/yifeikong/reverse-interview-zh
<br/>
见上
<br/>
<br/>
基本上是:
- 《算法(第四版)》
- java.util.*源码
- java.util.concurrent.*源码
慕课网-玩转数据结构
完全够用
<br/>
手写快排代码:
import java.util.Arrays;
public class Answer {
public static void main(String[] args) {
int[] a1 = {1, 6, 8, 7, 3, 5, 16, 4, 8, 36, 13, 44};
quickSort(a1, 0, a1.length - 1);
System.out.println(Arrays.toString(a1));
}
private static void quickSort(int[] arr, int start, int end) {
if (arr.length <= 1 || start >= end) return;
int left = start, right = end, pivot = arr[left];
while (left < right) {
while (left < right && arr[right] >= pivot) right--;
arr[left] = arr[right];
while (left < right && arr[left] <= pivot) left++;
arr[right] = arr[left];
}
arr[left] = pivot;
quickSort(arr, start, left - 1);
quickSort(arr, left + 1, end);
}
}
泛型版:
import java.util.Arrays;
import java.util.Comparator;
public class Answer {
public static void main(String[] args) {
Integer[] a1 = {1, 6, 8, 7, 3, 5, 16, 4, 8, 36, 13, 44};
// 从大到小
quickSort(a1, 0, a1.length - 1, Comparator.reverseOrder());
System.out.println(Arrays.toString(a1));
}
private static <T> void quickSort(T[] arr, int start, int end, Comparator<? super T> comparator) {
if (arr.length <= 1 || start >= end) return;
int left = start, right = end;
var pivot = arr[left];
while (left < right) {
while (left < right && comparator.compare(arr[right], pivot) >= 0) right--;
arr[left] = arr[right];
while (left < right && comparator.compare(arr[left], pivot) <= 0) left++;
arr[right] = arr[left];
}
arr[left] = pivot;
quickSort(arr, start, left - 1, comparator);
quickSort(arr, left + 1, end , comparator);
}
}
复杂度分析:
时间复杂度:
空间复杂度(递归造成的栈空间使用):
<br/>
更多与快排相关见: QuickSort总结
<br/>
略
<br/>
悲观锁:
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁
乐观锁:
每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制. 乐观锁适用于多读的应用类型,这样可以提高吞吐量
<br/>
垃圾回收有太多可以说的了, 总结一下, 大概有以下内容:
Java内存模型(方法区, 虚拟机栈, 本地方法栈, 堆, 程序计数器, 常量池, 直接内存…)
对象可达性分析(引用计数算法[循环引用问题], GC Root, 引用类型[Strong, Soft, Weak, Phantom])
对象生命周期(finilize()方法, 逃逸分析……)
垃圾收集算法
垃圾收集器
Serial: JDK1.3, 单线程, 新生代, Copying算法, Stop The World问题
Serial-Old: JDK1.3, 单线程, 老年代, Mark-Compact算法, Stop The World问题
ParNew: Serial的多线程版本, 新生代, Copying算法, Stop The World问题
Parallel Scavenge: 新生代, Copying算法, 目标达到一个可控制的吞吐量(throughput), 自适应调节策略;
Parallel Old: Parallel Scavenge的老年代版本, Mark-Compact算法, 解决新生代选择Parallel Scavenge老年代必须选择Serial Old(无法选择CMS)的尴尬处境, 和Parallel Scavenge配合解决注重吞吐量和CPU资源敏感的场景
CMS(Concurrent Mark Sweep): 获取最短回收停顿时间和响应速度, 解决Stop The World问题
G1: 解决CMS中Concurrent Mode Failed问题,尽量缩短处理超大堆的停顿,
ZGC: 目标伟大:
内存分配与回收策略
JVM调优:
<br/>
说明: 由于这块内容很多, 建议直接看《深入理解Java虚拟机》
<br/>
分段锁其实是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作
ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即: 内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock(Segment继承了ReentrantLock)
<font color="#f00">**当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在那一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入**</font>
但是,在统计size的时候,就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作
<br/>
后期会进行ConcurrentHashMap的源码解读
<br/>
一、创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式
二、结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式
三、行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式
共23种
<br/>
zk@zk:~/Downloads/src/java.base/java/util/concurrent$ tree
.
├── AbstractExecutorService.java
├── ArrayBlockingQueue.java
├── atomic
│ ├── AtomicBoolean.java
│ ├── AtomicIntegerArray.java
│ ├── AtomicIntegerFieldUpdater.java
│ ├── AtomicInteger.java
│ ├── AtomicLongArray.java
│ ├── AtomicLongFieldUpdater.java
│ ├── AtomicLong.java
│ ├── AtomicMarkableReference.java
│ ├── AtomicReferenceArray.java
│ ├── AtomicReferenceFieldUpdater.java
│ ├── AtomicReference.java
│ ├── AtomicStampedReference.java
│ ├── DoubleAccumulator.java
│ ├── DoubleAdder.java
│ ├── LongAccumulator.java
│ ├── LongAdder.java
│ ├── package-info.java
│ └── Striped64.java
├── BlockingDeque.java
├── BlockingQueue.java
├── BrokenBarrierException.java
├── Callable.java
├── CancellationException.java
├── CompletableFuture.java
├── CompletionException.java
├── CompletionService.java
├── CompletionStage.java
├── ConcurrentHashMap.java
├── ConcurrentLinkedDeque.java
├── ConcurrentLinkedQueue.java
├── ConcurrentMap.java
├── ConcurrentNavigableMap.java
├── ConcurrentSkipListMap.java
├── ConcurrentSkipListSet.java
├── CopyOnWriteArrayList.java
├── CopyOnWriteArraySet.java
├── CountDownLatch.java
├── CountedCompleter.java
├── CyclicBarrier.java
├── Delayed.java
├── DelayQueue.java
├── Exchanger.java
├── ExecutionException.java
├── ExecutorCompletionService.java
├── Executor.java
├── ExecutorService.java
├── Executors.java
├── Flow.java
├── ForkJoinPool.java
├── ForkJoinTask.java
├── ForkJoinWorkerThread.java
├── Future.java
├── FutureTask.java
├── Helpers.java
├── LinkedBlockingDeque.java
├── LinkedBlockingQueue.java
├── LinkedTransferQueue.java
├── locks
│ ├── AbstractOwnableSynchronizer.java
│ ├── AbstractQueuedLongSynchronizer.java
│ ├── AbstractQueuedSynchronizer.java
│ ├── Condition.java
│ ├── Lock.java
│ ├── LockSupport.java
│ ├── package-info.java
│ ├── ReadWriteLock.java
│ ├── ReentrantLock.java
│ ├── ReentrantReadWriteLock.java
│ └── StampedLock.java
├── package-info.java
├── Phaser.java
├── PriorityBlockingQueue.java
├── RecursiveAction.java
├── RecursiveTask.java
├── RejectedExecutionException.java
├── RejectedExecutionHandler.java
├── RunnableFuture.java
├── RunnableScheduledFuture.java
├── ScheduledExecutorService.java
├── ScheduledFuture.java
├── ScheduledThreadPoolExecutor.java
├── Semaphore.java
├── SubmissionPublisher.java
├── SynchronousQueue.java
├── ThreadFactory.java
├── ThreadLocalRandom.java
├── ThreadPoolExecutor.java
├── TimeoutException.java
├── TimeUnit.java
└── TransferQueue.java
常使用的有:
<br/>
说明: 只有多用, 多看源码, 无他
<br/>
可看: 从B树、B+树、B*树谈到R 树
马上也会总结到~
<br/>
① 字节
字节,就是byte,二进制数据
通常在读取图片、声音、可执行文件需要用字节数组来保存文件,在下载文件也是用byte数组来做临时的缓冲器接收文件内容
② 字符
机器只认识字节,而字符却是语义上的单位,它是有编码的,一个字符可能编码成1个2个甚至3个4个字节, 这跟字符集编码有关系,英文字母和数字是单字节,但汉字这些自然语言中的字符是多字节的
一个字节只能表示255个字符,不可能用于全球那么多种自然语言的处理,因此肯定需要多字节的存储方式
那么在文件的输入输出中,InputStream、OutputStream它们是处理字节流的,就是说假设所有东西都是二进制的字节;而 Reader, Writer 则是字符流,它涉及到字符集的问题;
按照ANSI编码标准,标点符号、数字、大小写字母都占一个字节,汉字占2个字节;
按照UNICODE标准所有字符都占2个字节;
<br/>
说明: 问题实际要问的是字节流和字符流的关系
更多关于IO流的内容见: Java中的IO流
<br/>
略
<br/>
https://jasonkayzk.github.io/project/
<br/>
<br/>
这个内容太宽泛了, 我大概总结了一下:
<br/>
IoC: Inversion of Control控制反转, 也叫(Dependency Injection)依赖注入. IoC 不是一种技术,只是一种思想, 它能指导我们如何设计出松耦合、更优良的程序
比如在程序中,依赖注入就是利用某种工具,将依赖注入到需要的位置; 依赖注入还有另一层意思:就是依赖第三方工具完成注入的操作。依赖注入的核心原理是注解和反射
优点是:
内存控制:统一管理对象,避免对象乱创建导致额外的内存开销, 便于内存的优化
降低耦合度:便于项目的扩展、易于维护
在IoC+接口情况下,删除任意实现类都不会导致程序编译出错。虽然运行到特定得代码会报错,但是其他代码在使用时不会有问题-----从侧面也反应出是松耦合
<br/>
补充: AOP(Aspect-Oriented Programming): 面向切面编程
AOP的主要原理:动态代理
代理模式:静态代理和动态代理(JDK动态代理、CGLib动态代理)
静态代理:针对每个具体类分别编写代理类;针对一个接口编写一个代理类; 动态代理的原理:反射
AOP优点是:
- AOP实现日志管理:方法的开始记录入参,方法结束需要记录返回值和运行时间
- AOP比IoC更简单,直白点说就是实现调用某个方法之前或/和之后,自动执行一系列自定义的语句
Spring 的AOP和IoC都是为了解决系统代码耦合度过高的问题, 使代码重用度高、易于维护
<font color="#f00">**本质上是尽量使用注入+JavaBean+注解这种轻量级低耦合组合的方式来取代继承这种重量级高耦合**</font>
<br/>
<br/>
<br/>
在使用Map对象的时候, 由于HashMap和TreeMap分别采用的是hash表和红黑树实现, 而并没有实现同步, 所以不适用于在多线程中使用;
所以解决方案主要有:
下面分别说明:
① 使用HashTable
Hashtable和HashMap都实现了Map接口,但是Hashtable的实现是基于Dictionary抽象类
这两个类最大的不同在于Hashtable是线程安全的,它的方法是同步了的(类似于List中的Vector),可以直接用在多线程环境中;
而HashMap则不是线程安全的。在多线程环境中,需要手动实现同步机制
<br/>
② 使用synchronizedMap
在Collections类中提供了一个方法返回一个同步版本的HashMap用于多线程的环境:
Map<String, Integer> map = Collections.synchronizedMap(new HashMap<>());
<br/>
说明:该方法返回的是一个SynchronizedMap 的实例
<font color="#f00">**SynchronizedMap类是定义在Collections中的一个静态内部类, 它实现了Map接口,并对其中的每一个方法实现,通过synchronized 关键字进行了同步控制**</font>
Collections为HashMap提供了一个并发版本SynchronizedMap, 这个版本中的方法都进行了同步,但是这并不等于这个类就一定是线程安全的, 在某些时候会出现一些意想不到的结果
如下面这段代码:
// shm是SynchronizedMap的一个实例
if (shm.containsKey('key')){
shm.remove(key);
}
这段代码用于从map中删除一个元素之前判断是否存在这个元素, 这里的containsKey和reomve方法都是同步的,但是整段代码却不是
考虑这么一个使用场景:
线程A执行了containsKey方法返回true,准备执行remove操作;这时另一个线程B开始执行,同样执行了containsKey方法返回true,并接着执行了remove操作;然后线程A接着执行remove操作时发现此时已经没有这个元素了
要保证这段代码按我们的意愿工作,一个办法就是对这段代码再进行同步控制,但是这么做付出的代价太大
在进行迭代时这个问题更加明显!
<br/>
HTTPS其实是由两部分组成:HTTP + SSL/TLS(Transport Layer Security,传输层安全协议), 也就是在http上又加了一层处理加密信息的模块,服务端和客户端的信息传输都会通过tls加密,传输的数据都是加密后的数据
<br/>
补充: SSL和TLS
SSL(Secure Socket Layer 安全套接层): TCP/IP协议中基于HTTP之下TCP之上的一个可选协议层;
TLS(Transport Layer Security 安全传输层协议): 在SSL更新到3.0时, 互联网工程任务组(IETF)对SSL3.0进行了标准化,并添加了少数机制(但是几乎和SSL3.0无差异),并将其更名为TLS1.0(Transport Layer Security 安全传输层协议),可以说TLS就是SSL的新版本3.1
两者相同点
TLS与SSL连接过程无任何差异
TLS与SSL的两个协议(记录协议和握手协议)协作工作方式是一样的
两者不同点
- SSL与TLS两者所使用的算法是不同的
- TLS增加了许多新的报警代码,比如解密失败(decryption_failed)、记录溢出(record_overflow)、未知CA(unknown_ca)、拒绝访问(access_denied)等,同时也支持SSL协议上所有的报警代码
<font color="#f00">**由于这些区别的存在,我们可认为TLS是SSL的不兼容增强版, 即TLS和SSL不能共用: 在证证书时TLS指定必须与TLS之间交换证书, SSL必须与SSL之间交换证书**</font>
<br/>
HTTPS过程:
1)客户端发起HTTPS请求(就是用户在浏览器里输入一个https网址,然后连接到server的443接口)
2)服务端的配置(采用https协议的服务器必须要有一个数字证书,可以自己制作,也可以向组织申请,这套证书就是一对公钥和私钥)
3)传输证书(这个证书包括公钥,同时包含了很多信息: 如支持的加密算法等)
4)客户端解析证书(由客户端TLS完成,首先验证公钥是否有效,若发现异常,则弹出一个警示框,提示证书存在问题,若无问题,则生成一个随机值,然后用证书对随机值进行加密)
5)传输加密信息(这里传输的是加密后的随机值,目的是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密了)
6)服务端解密信息(服务端用私钥解密后得到了客户端传来的随机值,然后选定一种对称加密算法把内容通过该值进行对称加密)
7)传输加密的信息
8)客户端解密信息,用随机数来解
具体过程如下图:

<br/>
注: 在客户端抓包抓到的是没有加密的
<br/>
公钥能用公钥解密吗?
<font color="#f00">**不能证书给客户端的仅仅是公钥, 客户端通过公钥加密随机数, 传递到服务器通过服务器的私钥解密随机数, 并通过客户端传入的随机数构造对称加密算法,对返回结果内容进行加密后传输;**</font>
这个问题显然问的是计算机网络安全的内容, 首先要明确的是:
<font color="#f00">**在HTTPS进行数据传输时使用的是对称加密, 非对称加密只作用在证书验证阶段**</font>
<br/>
HTTPS进行数据传输时使用对称加密的原因:
非对称加密的加解密效率是非常低的,而HTTP的应用场景中通常端与端之间存在大量的交互,非对称加密的效率是无法接受的
此外, 在 HTTPS 的场景中只有服务端保存了私钥,一对公私钥只能实现单向的加解密,所以 HTTPS 中内容传输加密采取的是对称加密,而不是非对称加密
<br/>
补充:
HTTPS更详细的内容: 你知道,HTTPS用的是对称加密还是非对称加密?
加密算法内容: SSH HTTPS 公钥、秘钥、对称加密、非对称加密、 总结理解
<br/>
详见: Java线程池ThreadPoolExecutor分析与实战
<br/>
补充: 阿里巴巴禁止使用线程池而推荐手动创建Thread的原因:
<font color="#f00">**线程池中线程不可控, 可能会继续占用资源, 最终拖垮服务器;**</font>
具体见: Java基础总结之五- 第二点提出的例子
<br/>
线程池知识推荐:
- B站视频: Java并发之线程池
<br/>
<br/>
主要涉及的是Java的双亲委派模型等: Java基础总结之七 - 第一题
<br/>
张凯, EE –> CS, 本科:
自律性较强, 认真, 细心, 抗打击能力强~;
脾气不太好, 口軽い〜
项目其实有很多: https://jasonkayzk.github.io/project/
用的是JDK 11, 各种坑, 网上找资料吧……
杭 > 广 > 深 > 上 > 北
<br/>