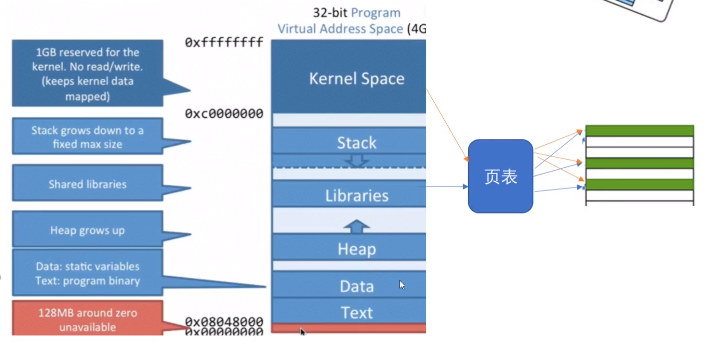
上一篇操作系统内存管理简述的文章中讲解了操作系统的内存管理,这篇让我们从上到下看内存;
视频参考:
源代码:
系列文章:
<br/>
<!--more-->内存与CPU之间是通过总线进行交互的;
而为了提高CPU的效率,在主板的南桥芯片上嵌入了DMA控制器(Direct Memory Access);
南桥芯片上主要接入一些如:USB、硬盘、网卡、声卡等低速的外接设备;
我们先考虑这么一个情况:
当我们使用Node.js读取一个文件时,尽管文件没有读取完,Node却可以继续执行其他的操作,当文件读取完成后,会执行相应的回调;
但是Node是一个单线程的,如果CPU在读取文件期间都在等待内存读取,那么其他程序是不能被执行的,所以这里就使用到了DMA控制器(DMA Controller);
CPU使用DMAC进行读取的图如下:
首先,CPU向DMAC发出信号,要求读取,随后CPU就执行其他指令;
随后,DMA使用CPU让出的数据总线将磁盘中的数据读入内存;
文件读入完毕后,DMAC通过系统中断通知CPU,进行回调处理;
<font color="#f00">**注:在实现DMA传输时,是由[DMA控制器](https://baike.baidu.com/item/DMA控制器/921346)直接掌管总线,因此,存在着一个总线控制权转移问题。即DMA传输前,CPU要把总线控制权交给DMA控制器,而在结束DMA传输后,DMA控制器应立即把总线控制权再交回给CPU;**</font>
一个完整的DMA传输过程必须经过DMA请求、DMA响应、DMA传输、DMA结束4个步骤;
<br/>
关于操作系统中的内存管理,可以先看一下这篇文章:
接下来来看内存的分类;
在Linux中通过free命令查看:
$ free -h
total used free shared buff/cache available
Mem: 15Gi 665Mi 14Gi 7.0Mi 898Mi 14Gi
Swap: 2.0Gi 0B 2.0Gi
其中Mem代表内存,Swap代表交换分区(即Page Table映射到的磁盘分区);
其余:
total = used(含shared) + free + buff/cache
在一般情况下,used是包含shared的大小的;
free就是真正的空闲内存,即:根本没有被申请过的空间;
available就是实际内存真正剩余的空间;
buff/cache就是读过的文件被缓存在内存中的大小,这部分空间可以根据需要而被释放(如,其他程序需要开辟大量空间时);
buff和cache:
在较早的内核中,buff和cache是分开的两个区域:buffer cache和page cache,都是对磁盘的缓存;
其中:
- buffer cache是硬件层面,对磁盘块中的数据进行缓存,缓存的单位当然也是块;
而page cache是文件系统层面,对文件进行缓存,缓存单位就是页;
buffer cache的提出非常的早,两者并存时会遇到重复缓存了相同的内容的情况;
较新的内核已经将两者合并,或者说将buffer cache合到了page cache,虽然也还是能缓存磁盘块,但是存储单位也是页了,并且buffer使用前会先检查page cahce是否已经缓存了对应内容,如果是则直接指过去;
详细见:
<br/>
windows的内存分类如下图所示:
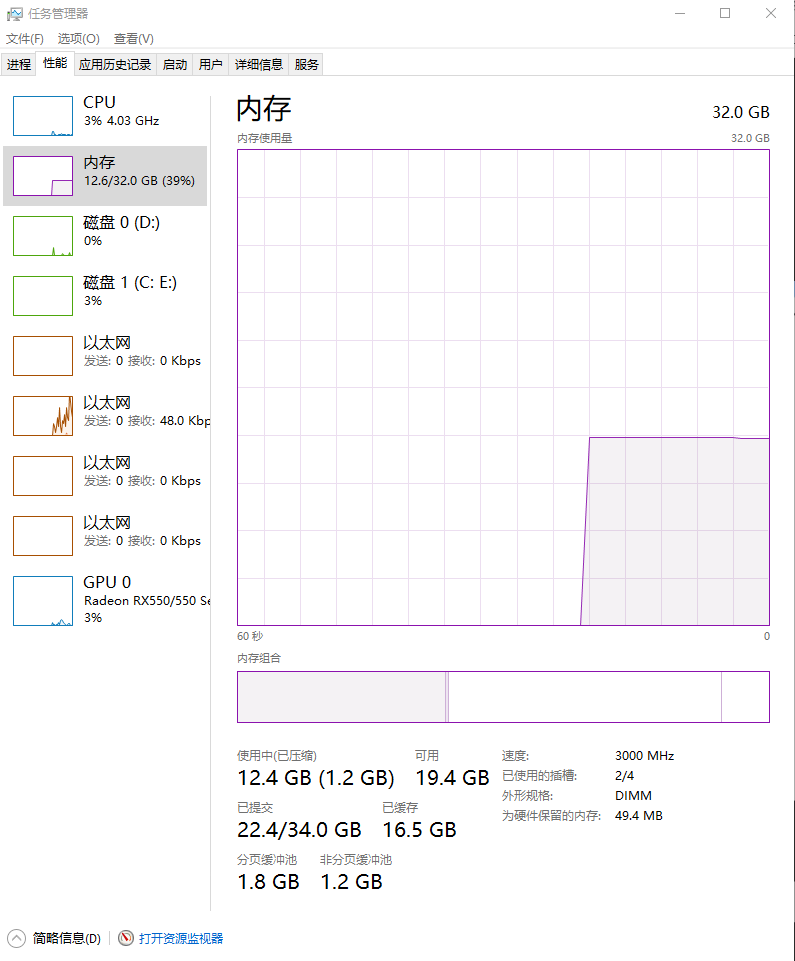
从上面可以看到内存的总大小为32GB,目前已经使用了12.4GB,可用就是19.4GB;
已提交的意思是:程序已经向操作系统申请了这么多的内存,操作系统可能已经给了这么多内存了,但是也可能没有给那么多(映射到了磁盘);
即已提交中的34GB相当于Linux中的Swap + Mem,但是在Windows中,Swap对应了C盘下的pagefile.sys文件(通常不可见!);
已提交中的22.4GB代表程序已经向操作系统申请了22.4GB的内存,但是操作系统并不会直接给程序开辟申请的空间;
<font color="#f00">**如:在C语言中使用malloc开辟了1024MB的空间,但是只使用了1MB的空间;则此时已提交为1GB,但是实际上程序只使用了1MB空间,剩余的1023MB空间,操作系统不会分配;**</font>
已缓冲:对应于Linux中的buffer cache,即对文件的缓冲;
分页缓冲池/非分页缓冲池:
对应于内核以及驱动设备的资源;
详见:
<br/>
接下来讲解内存相关的系统调用;
系统调用即:用户态切换至内核态的方式之一(另外两种是中断和异常),而在申请内存时就需要使用系统调用;
为了安全起见,用户是无法直接操纵硬件的,所以需要通过系统调用使用内核操作;
本节以malloc为例,进行讲解;
malloc在C语言中用于申请内存空间;
<font color="#f00">**malloc本身不是系统调用,但是malloc是brk和mmap系统调用的封装;**</font>
- <font color="#f00">**在128KB以内,默认使用的是brk系统调用,进行内存申请;**</font>
- <font color="#f00">**在128KB以上,使用mmap进行内存申请;**</font>
malloc小于128K(阈值可修改)的内存时,用的是brk;
在C语言的unistd.h头文件中有一个sbrk的库函数,是对brk的封装;
brk_demo.c
#include <stdio.h>
#include <unistd.h>
int main() {
void *first = sbrk(0);
void *second = sbrk(1);
void *third = sbrk(0);
printf("%p\n", first);
printf("%p\n", second);
printf("%p\n", third);
}
代码解释:
首先,申请0个字节空间给first,再申请一个字节给second,最后申请0个字节给third;
程序输出如下:
0x800040000
0x800040000
0x800040001
由于second申请的一个字节返回的是空间的头,所以和first地址相同;
而third在申请时,由于已经被second占用,所以输出为后一个内存区域;
<font color="#f00">从上面的代码可以看出,brk在申请内存时,是连续申请的,所以虚拟地址是连续分配的,
brk其实就是向上扩展heap的上界;<font>
修改程序,仅申请一个字节,并把指针强转为int类型:
brk_demo2.c
#include <stdio.h>
#include <unistd.h>
int main() {
int *first = (int *)sbrk(1);
*(first + 1) = 123;
printf("%d\n", *(first + 1));
}
此时,first+1实际上是位于第五个字节(int本身是四个字节!);
所以*(first + 1) = 123实际上是对5~8字节赋值为123;
<font color="#f00">**注意:我们申请的是第0个字节的区域,但是却给5~8字节进行赋值了!**</font>
执行程序,输出结果如下:
123
执行没有报错的原因在于:<font color="#f00">**在进行brk时,申请的内存最小空间是一页,即4KB;所以,brk看似是申请了一个字节,实际上是申请了4KB的大小吗,即4096Byte!所以在赋值时,还是在当页进行赋值的,所以不会报错!**</font>
再次修改代码,使用4K区域之后的内存空间:
brk_demo3.c
#include <stdio.h>
#include <unistd.h>
int main() {
int *first = (int *)sbrk(1);
*first = 1;
*(first + 1024) = 123;
printf("%d\n", *(first + 1024));
}
编译并执行:
jasonkay@jasonkayPC:~/workspace$ gcc test.c -o test.out
jasonkay@jasonkayPC:~/workspace$ ./test.out
Segmentation fault (core dumped)
可以发现,由于在新的一页进行分配,直接报了Segment Fault错误;
这是由于没有申请新的一页,却直接用了!
<font color="#f00">**注:上述的实验是在Linux环境下进行了,在Windows下并未复现Segment Fault!**</font>
<br/>
当malloc申请大于128K的内存时,用的是mmap;
在C语言中对应的申请和释放函数如下所示:
#include<sys/mman.h>
// addr传NULL则不关心起始地址
// 关心地址的话应传个4k的倍数,不然也会归到4k倍数的起始地址;
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
//释放内存munmap
int munmap(void *addr, size_t length);
其中:
函数返回值:调用成功返回映射区的首地址,调用失败返回MAP_FAILED宏(实际上是(void*)-1);
munmap函数:
函数作用:释放内存映射区;
函数原型及参数:
int munmap(void *addr, size_t length);
- addr:mmap函数的返回值;
length:mmap的第二个参数,映射区的长度 ;
函数返回值:成功时,munmap()返回0;失败时返回-1(and errno is set (probably to EINVAL));
mmap申请内存的代码如下:
mmap_demo.c
#include <stdio.h>
#include <unistd.h>
#include <sys/mman.h>
int main() {
// 使用mmap申请100页(100 * 4KB)
int *a = (int *) mmap(NULL, 100 * 4096,
PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS,
-1, 0);
int *b = a;
// 100页中的每一页都进行赋值(否则,如果申请的没有被使用,操作系统不会分配)
for (int i = 0; i < 100; ++i) {
b = (void *) a + (i * 4096);
// 每一页第一个地址赋值为1
*b = 1;
}
while (1) {
sleep(1);
}
}
在代码中,我们申请了100页的内存,并且对每一页进行赋值;
并使用pidstat对进程进行监控;
pidstat可以通过
sudo apt install sysstat安装;
使用pidstat对进程监控,并编译和执行上述程序:
pidstat -r 1 300
编译执行:
gcc test.c -o a.out
./a.out
结果如下:
08时51分00秒 UID PID minflt/s majflt/s VSZ RSS %MEM Command
08时51分01秒 1000 7497 100.00 0.00 2756 1236 0.01 test.out
可以看出,监控中出现了100次的min fault,代表了内存的小错误:
因为在赋值时,每一页并没有分配空间,所以需要缺页错误;
缺页不是严重的错误,因为这个缺页对应的不是磁盘内容;
<br/>
下面使用mmap将一个文件映射至内存;
mmap_demo2.c
#include <sys/types.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/mman.h>
int main() {
sleep(4);
// 打开文件,获取文件描述符
int fd = open(".\\1.txt", O_RDONLY, S_IRUSR|S_IWUSR);
struct stat sb;
if (fstat(fd, &sb) == -1) {
perror("cannot get file size\n");
}
printf("file size is %ld\n", sb.st_size);
// 映射文件到内存中
char *file_in_memory = mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
// 打印文件
for (int i = 0; i < sb.st_size; ++i) {
printf("%c", file_in_memory[i]);
}
// 关闭
munmap(file_in_memory, sb.st_size);
close(fd);
}
再次通过pidstat监控,结果如下:
09时14分03秒 UID PID minflt/s majflt/s VSZ RSS %MEM Command
09时14分04秒 1000 7625 64.00 1.00 2356 516 0.00 a.out
09时14分04秒 1000 7625 24.00 0.00 2356 516 0.00 a.out
09时14分04秒 1000 7625 14.00 0.00 2356 516 0.00 a.out
09时14分04秒 1000 7625 34.00 0.00 2356 516 0.00 a.out
可以看到,首先会触发一次major fault,将文件读入内存;
如果mmap是映射的磁盘文件,也会惰性加载,在初次加载或者页被逐出后再加载的时候,也会缺页,此时为major fault;
使用read也可以读取文件:
<font color="#f00">**但是使用read系统调用进行文件读取时,会从用户态进入内核态,随后由内核将文件读入内核空间,再由内核空间复制到用户的内存空间;之后再从内核态切换为用户态,继续执行用户程序;**</font>
<font color="#f00">**而mmap是空间的直接映射:首先将Page Table中的空间映射至磁盘(惰性加载),而在第一次读文件时,发现映射是磁盘空间,进而引起major fault缺页中断,将文件直接读入内存空间,并产生内核空间和用户空间的直接映射;**</font>
流程图如下:
所以mmap省去了内核空间→用户空间的拷贝的过程;
虽然mmap实现了零拷贝,但是mmap无法利用buffer/cache内存区域,并且mmap引发的缺页异常和read函数的耗时并无绝对的性能优势,所以read函数和mmap都有各自的应用场景;
<br/>
mmap、sendfile和splice是常见的零拷贝的系统调用;
说到零拷贝,就要提一下用户态和内核态、用户空间和内核空间;
内核空间就是位于内存高位的kernel的那部分内存,其他部分是用户空间;而内核态指的是一种状态,就是把cpu掌控权交给内核;
为什么要有内核态呢?因为所有的设备都不允许用户直接控制,包括内存条、硬盘、甚至是屏幕、usb外设,都是需要内核统一控制,如果用户程序想用这些设备必须进入内核态;
有三种方式进入内核态:中断、异常和系统调用;
中断和异常界限不是特别明显,上文多次提到缺页异常(有时候也叫缺页中断)就是用户态进入内核态的一种;系统调用上面也提到过了,mmap、brk这些都是系统调用,比较熟悉的比如read/write/select/poll/epoll也是系统调用;
mmap的作用第一个是将文件映射到内存中,映射的区域是堆和栈之间的lib区,是用户空间的一部分内存;
这时候我们其实通过系统调用将硬盘的内容直接放到了用户空间中,当然了在初次访问或者被逐出后的初次访问时,仍旧会触发缺页,导致读取很慢,但是在页填充好之后的读取是很快的;
但是前面说过只有内核有资格直接和文件交互,所以其实这里映射到用户空间的这部分物理内存,在内核中同时也做了映射,即用户和内核共享了这部分物理内存(注意不是虚拟内存);
<br/>
通过read这个系统调用读文件(fread是read封装好的库函数),是将文件内容读到内核空间,再从内核空间拷贝到用户空间,这个过程中,对文件的读写,必须经过内核空间,所以需要频繁的内核空间和用户空间的拷贝;
用MMAP可以将文件直接映射到用户空间内存,省去了拷贝,所以mmap是零拷贝的一种实现形式;
上面一直说的是文件,其实linux下一切皆是文件,网络接收数据的套接字也是文件描述符fd;
例如,我们读取文件再通过网卡发送的过程中,其实是有磁盘IO和网络IO本就是很慢的,再加上多次的拷贝;
所以这种场景下一般都用零拷贝来搞,一般使用的是支持scatter/gather的DMA控制器,外加sendfile系统调用来做到最少次数的拷贝和状态切换;
mmap可以简单的把文件和网卡都映射到用户空间,并像操作普通内存一样实现转发;
<font color="#f00">**但是不确定的缺页异常触发会使得性能不好评估;**</font>
<br/>
sendfile则针对性的进行了函数上的简化,为“零拷贝”而生;
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
按照维基百科的说法:
零拷贝协议对于网络链接容量接近或超过CPU处理能力的高速网络尤其重要;在这种情况下,CPU几乎将所有时间都花在复制传输的数据上,因此成为瓶颈,将通信速率限制为低于链接的容量;
下面这篇文章,解释了普通read/write、sendfile和mmap实现上面网络转发场景的详细过程;
<br/>
视频参考:
源代码:
系列文章:
<br/>