本文总结了如何使用Golang实现断点续传以及多线程下载。
源代码:
<br/>
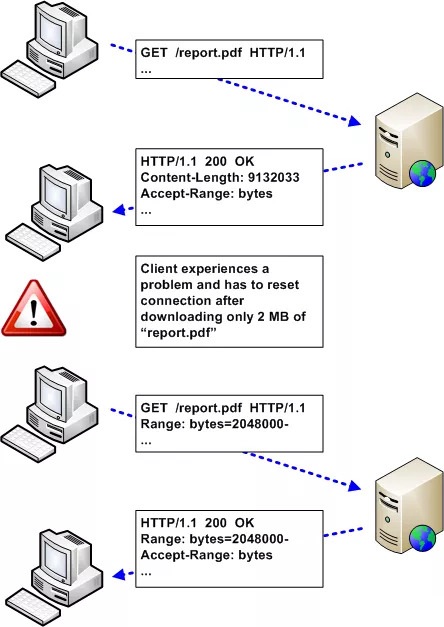
<!--more-->断点续传/下载,可以在网络情况不好、甚至是在断开网络连接,网络回复以后,还可以继续获取部分内容。用到的技术就是范围请求。例如在网上下载软件,已经下载95%了,此时网络断了,如果不支持范围请求,那就只有被迫重头开始下载。但是如果有范围请求的加持,就只需要下载最后5%的资源,以避免重新下载。
多线程下载,则是对大型文件,开启多个线程,每个线程下载其中的某一段,最后下载完成之后,在本地拼接成一个完整的文件,这样可以更有效的利用资源;
<br/>
HTTP1.1 协议(RFC2616)开始支持获取文件的部分内容,这为并行下载以及断点续传提供了技术支持:通过在 Header里两个参数Range和Content-Range实现:
<font color="#f00">**客户端发请求时对应的是 Range,服务器端响应时对应的是 Content-Range。**</font>
Range是一个请求头,它告知了服务器返回文件的哪一部分。在一个 Range 中,可以一次性请求多个部分,服务器会以 multipart 文件的形式将其返回。
如果服务器返回的是范围响应,则需要使用 206 Partial Content 状态码。
如果所请求的范围不合法,那么服务器会返回 416 Range Not Satisfiable 状态码,表示客户端错误。
同时,服务器允许忽略Range,从而返回整个文件,此时状态码仍然是200。
<BR/>一个Range的例子如下:
Range:(unit=first byte pos)-[last byte pos]
Range 头部的格式有以下几种情况:
Range: <unit>=<range-start>-
Range: <unit>=<range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>, <range-start>-<range-end>
接下来看一个请求Goland的响应:
$ curl --location --head 'https://download.jetbrains.com/go/goland-2020.2.2.exe'
date: Sat, 15 Aug 2020 02:44:09 GMT
content-type: text/html
content-length: 138
location: https://download-cf.jetbrains.com/go/goland-2020.2.2.exe
server: nginx
strict-transport-security: max-age=31536000; includeSubdomains;
x-frame-options: DENY
x-content-type-options: nosniff
x-xss-protection: 1; mode=block;
x-geocountry: United States
x-geocode: US
HTTP/1.1 200 OK
Content-Type: binary/octet-stream
Content-Length: 338589968
Connection: keep-alive
x-amz-replication-status: COMPLETED
Last-Modified: Wed, 12 Aug 2020 13:01:03 GMT
x-amz-version-id: p7a4LsL6K1MJ7UioW7HIz_..LaZptIUP
Accept-Ranges: bytes
Server: AmazonS3
Date: Fri, 14 Aug 2020 21:27:08 GMT
ETag: "1312fd0956b8cd529df1100d5e01837f-41"
X-Cache: Hit from cloudfront
Via: 1.1 8de6b68254cf659df39a819631940126.cloudfront.net (CloudFront)
X-Amz-Cf-Pop: PHX50-C1
X-Amz-Cf-Id: LF_ZIrTnDKrYwXHxaOrWQbbaL58uW9Y5n993ewQpMZih0zmYi9JdIQ==
Age: 19023
如果在响应的Header中存在Accept-Ranges首部(并且它的值不为 “none”),那么表示该服务器支持范围请求(支持断点续传)。
可以使用 cURL 发送一个 HEADER 请求来进行检测:
curl -I http://i.imgur.com/z4d4kWk.jpg
HTTP/1.1 200 OK...Accept-Ranges: bytesContent-Length: 146515
在上面的响应中, Accept-Ranges: bytes 表示界定范围的单位是 bytes,这里 Content-Length 也是很有用的信息,因为它提供了要检索的图片的完整大小!
如果站点返回的Header中不包括Accept-Ranges,那么它有可能不支持范围请求。一些站点会明确将其值设置为 “none”,以此来表明不支持。在这种情况下,某些应用的下载管理器会将暂停按钮禁用!
最后,看一个具体的断点续传的例子:
下面来看一下具体实现代码,相信看完了代码,也能给你突破百度网盘下载限速提供思路;
首先我们定义了一个文件下载类FileDownloader:
// FileDownloader 文件下载器
type FileDownloader struct {
// 待下载文件总大小
fileSize int
// 下载源链接
url string
// 下载完成文件名
outputFileName string
// 文件切片数,对应为下载线程
totalPart int
// 文件输出目录
outputDir string
// 已完成文件切片
doneFilePart []filePart
// 文件下载完成校验,例如md5, SHA-256等
md5 string
}
以及一个文件分片类filePart,以供我们将文件拆分下载:
// filePart 文件分片
type filePart struct {
// 文件分片的序号
Index int
// 开始byte
From int
// 结束byte
To int
// http下载得到的文件分片内容
Data []byte
}
我们通过NewFileDownloader方法创建一个文件下载器:
// FileDownloader 工厂方法
func NewFileDownloader(url, outputFileName, outputDir string, totalPart int, md5 string) *FileDownloader {
if outputDir == "" {
// 获取当前工作目录
wd, err := os.Getwd()
if err != nil {
log.Println(err)
}
outputDir = wd
}
return &FileDownloader{
fileSize: 0,
url: url,
outputFileName: outputFileName,
outputDir: outputDir,
totalPart: totalPart,
doneFilePart: make([]filePart, totalPart),
md5: md5,
}
}
各个构造参数的意义如下:
首先向源地址发送一个HEADER请求:
/*
head 获取要下载的文件的响应头(header)基本信息
使用HTTP Method Head方法
*/
func (d *FileDownloader) getHeaderInfo() (int, error) {
headers := map[string]string{
"User-Agent": userAgent,
}
r, err := getNewRequest(d.url, "HEADER", headers)
resp, err := http.DefaultClient.Do(r)
if err != nil {
return 0, err
}
if resp.StatusCode > 299 {
return 0, errors.New(fmt.Sprintf("Can't process, response is %v", resp.StatusCode))
}
// 检查是否支持断点续传
// https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Accept-Ranges
if resp.Header.Get("Accept-Ranges") != "bytes" {
return 0, errors.New("服务器不支持文件断点续传")
}
// 支持文件断点续传时,获取文件大小,名称等信息
outputFileName, err := parseFileInfo(resp)
if err != nil {
return 0, errors.New(fmt.Sprintf("get file info err: %v", err))
}
if d.outputFileName == "" {
d.outputFileName = outputFileName
}
// https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Length
return strconv.Atoi(resp.Header.Get("Content-Length"))
}
func getNewRequest(url, method string, headers map[string]string) (*http.Request, error) {
r, err := http.NewRequest(
method,
url,
nil,
)
if err != nil {
return nil, err
}
for k, v := range headers {
r.Header.Set(k, v)
}
return r, nil
}
func parseFileInfo(resp *http.Response) (string, error) {
contentDisposition := resp.Header.Get("Content-Disposition")
if contentDisposition != "" {
_, params, err := mime.ParseMediaType(contentDisposition)
if err != nil {
return "", err
}
return params["filename"], nil
}
filename := filepath.Base(resp.Request.URL.Path)
return filename, nil
}
其中getNewRequest用于获取一个*http.Request指针;
而parseFileInfo解析出了Header中的文件相关属性,主要是:
当在header中获取到了支持断点续传后,使用downloadPart方法下载其中的一个分片(各个分片由创建下载器时的totalPart切分决定);
// 下载分片
func (d *FileDownloader) downloadPart(c filePart) error {
headers := map[string]string{
"User-Agent": userAgent,
"Range": fmt.Sprintf("bytes=%v-%v", c.From, c.To),
}
r, err := getNewRequest(d.url, "GET", headers)
if err != nil {
return err
}
log.Printf("开始[%d]下载from:%d to:%d\n", c.Index, c.From, c.To)
resp, err := http.DefaultClient.Do(r)
if err != nil {
return err
}
if resp.StatusCode > 299 {
return errors.New(fmt.Sprintf("服务器错误状态码: %v", resp.StatusCode))
}
defer resp.Body.Close()
bs, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
if len(bs) != (c.To - c.From + 1) {
return errors.New("下载文件分片长度错误")
}
c.Data = bs
d.doneFilePart[c.Index] = c
return nil
}
通过mergeFileParts方法,将下载好的各个分片的二进制按照顺序合并,并最终保存为下载文件;
如果有必要的话,也会计算整个文件的MD5值,以验证文件的完整性:
// mergeFileParts 合并下载的文件
func (d *FileDownloader) mergeFileParts() error {
path := filepath.Join(d.outputDir, d.outputFileName)
log.Println("开始合并文件")
mergedFile, err := os.Create(path)
if err != nil {
return err
}
defer mergedFile.Close()
fileMd5 := sha256.New()
totalSize := 0
for _, s := range d.doneFilePart {
_, err := mergedFile.Write(s.Data)
if err != nil {
fmt.Printf("error when merge file: %v\n", err)
}
fileMd5.Write(s.Data)
totalSize += len(s.Data)
}
if totalSize != d.fileSize {
return errors.New("文件不完整")
}
if d.md5 != "" {
if hex.EncodeToString(fileMd5.Sum(nil)) != d.md5 {
return errors.New("文件损坏")
} else {
log.Println("文件SHA-256校验成功")
}
}
return nil
}
最终用户只需要创建下载器,并且调用其中的Run方法,即可完成下载;
在Run方法中,首先进行了Header请求,然后将请求分片,进行并发下载,在最后调用mergeFileParts方法将全部文件合并:
//Run 开始下载任务
func (d *FileDownloader) Run() error {
fileTotalSize, err := d.getHeaderInfo()
if err != nil {
return err
}
d.fileSize = fileTotalSize
jobs := make([]filePart, d.totalPart)
eachSize := fileTotalSize / d.totalPart
for i := range jobs {
jobs[i].Index = i
if i == 0 {
jobs[i].From = 0
} else {
jobs[i].From = jobs[i-1].To + 1
}
if i < d.totalPart-1 {
jobs[i].To = jobs[i].From + eachSize
} else {
// 最后一个filePart
jobs[i].To = fileTotalSize - 1
}
}
var wg sync.WaitGroup
for _, j := range jobs {
wg.Add(1)
go func(job filePart) {
defer wg.Done()
err := d.downloadPart(job)
if err != nil {
log.Println("下载文件失败:", err, job)
}
}(j)
}
wg.Wait()
return d.mergeFileParts()
}
示例代码如下:
func main() {
startTime := time.Now()
url := "https://download.jetbrains.com/go/goland-2020.2.2.dmg"
// SHA-256: https://download.jetbrains.com/go/goland-2020.2.2.dmg.sha256?_ga=2.223142619.1968990594.1597453229-1195436307.1493100134
md5 := "3af4660ef22f805008e6773ac25f9edbc17c2014af18019b7374afbed63d4744"
downloader := NewFileDownloader(url, "", "", 8, md5)
if err := downloader.Run(); err != nil {
log.Fatal(err)
}
fmt.Printf("\n 文件下载完成耗时: %f second\n", time.Now().Sub(startTime).Seconds())
}
上面的例子中首先使用NewFileDownloader创建了一个下载器,传入了下载源地址,以及对应的校验值;
最后调用Run方法完成了下载!
<BR/>关于断点续传:
上面的例子仅仅展示的多线程下载,而对于断点续传来说,只需要记住每个分片当前已经下载的byte即可继续下载!
作为一个学习和展示HTTP多线程下载的例子,上面的代码已经基本足够了;
但是如果想要开发一个真正的下载器,上面的例子还是有相当多的不足的,例如:如果下载源不支持断点续传就不再下载、用户将文件切了多少片就开多少个协程下载、整个文件分片的下载都在内存中保存等;
上面的例子也仅仅是起到了抛砖引玉的作用,但是相信大家还是了解了多线程下载的原理了;
<BR/>源代码:
<br/>