本文是Java面试总结中JavaWeb的第一篇
<br/>
<!--more-->① 调节对web.xml的监视
具体做法: context.xml中($CATALINA_HOME/conf/中)修改<WatchedResource>WEB-INF/web.xml</WatchedResource>
<br/>
说明:
server.xml 是不可动态重加载的资源,服务器一旦启动了以后,要修改这个文件,就得重启服务器才能重新加载;
context.xml 文件则不然, tomcat 服务器会定时去扫描这个文件。一旦发现文件被修改(时间戳改变了),就会自动重新加载这个文件,而不需要重启服务器
但生产环境下可以关闭扫描以提高性能
<br/>
② 把jsp提前编辑成Servlet
具体做法: 在项目部署后打开各个网页一遍即可(针对JSP开发, 虽然也没什么人用了)
<br/>
③ 优化Tomcat参数
这里以tomcat7的参数配置为例: 修改conf/server.xml文件,主要是优化连接配置,关闭客户端dns查询:
<Connector port="8080"
protocol="org.apache.coyote.http11.Http11NioProtocol"
connectionTimeout="20000"
redirectPort="8443"
maxThreads="500"
minSpareThreads="20"
acceptCount="100"
disableUploadTimeout="true"
enableLookups="false"
URIEncoding="UTF-8" />
<br/>
④ 调节JVM参数
Tomcat默认可以使用的内存为128MB,可在配置文件或环境变量里增加使用内存
具体操作:
① 配置文件中: 通过配置tomcat的配置文件(Windows下的catalina.bat或Linux下的catalina.sh),在前面增加设置JAVA_OPTS="$JAVA_OPTS" -Xms[初始化内存大小] -Xmx[可以使用的最大内存]
② 设置环境变量: export JAVA_OPTS=””$JAVA_OPTS” -Xms[初始化栈内存大小] -Xmx[可以使用的最大内存]”
<br/>
原因: 减少内存溢出的情况,减少频繁分配堆而降低性能,减少gc次数,所以服务器可以更多关注处理web请求,并要求尽快完成
<br/>
⑤ 提升版本解决JRE内存泄漏
具体操作: 更新到最新版本的Tomcat来获得较好性能和可扩展性, 最新版本的Tomcat包含一个监听器来处理 JRE 和 permgen 内存泄漏
<br/>
⑥ 线程池设置
maxThreads的值应该根据流量的大小设置:
具体操作: 在server.xml中的connector标签里设置最大线程数
原因: 线程池决定Web请求负载的数量,因此,为获得更好的性能这部分应小心处理
<br/>
⑦ 利用Nginx缓存和压缩
采用了Nginx作为缓存服务器,将图片、css、js文件都进行了缓存
原因:
① 对于静态页面最好是能够缓存起来,这样就不必每次从磁盘上读。所以采用了Nginx作为缓存服务器,将图片、css、js文件都进行了缓存,有效的减少了后端tomcat的访问
② 为了能加快网络传输速度,开启gzip压缩也是必不可少的, 但考虑到tomcat已经需要处理很多东西了,所以把这个压缩的工作就交给前端的Nginx来完成
<br/>
⑧ 采用集群
采用了Nginx来作为请求分流的服务器,后端多个tomcat共享session来协同工作
原因: 单个服务器性能总是有限的,最好的办法自然是实现横向扩展,那么组建tomcat集群是有效提升性能的手段
<br/>
GET和POST是HTTP请求的两种基本方法, 最直观的区别就是: GET把参数包含在URL中,POST通过request body传递参数
此外还有:
<br/>
注: GET和POST本质上没有区别, 仅仅是HTTP协议中的两种发送请求的方法
HTTP的底层是TCP/IP。所以GET和POST的底层也是TCP/IP,也就是说,GET/POST都是TCP链接, 给GET加上request body,或者给POST带上url参数,技术上是完全行的通的
HTTP在网络传输中设定了好几个服务类别,有GET, POST, PUT, DELETE等等
HTTP规定:
这里, 我们只看到HTTP对GET和POST参数的传送渠道(url还是requrest body)提出了要求, 而里关于参数大小的限制又是从哪来的呢?
实际上, 限制来自于不同的浏览器(发起http请求)和不同的服务器(接受http请求)
虽然理论上,你可以在url中无限加参数, 但是对于浏览器, 解析url也是有很大成本的,他们会限制url长度来控制风险,数据量太大对浏览器和服务器都是很大负担
<br/>
备注: 业界不成文的规定是,(大多数)浏览器通常都会限制url长度在2K个字节,而(大多数)服务器最多处理64K大小的url。超过的部分,恕不处理
如果你用GET服务,在request body偷偷藏了数据,不同服务器的处理方式也是不同的,有些服务器会帮你卸货,读出数据,有些服务器直接忽略,所以,虽然GET可以带request body,也不能保证一定能被接收到哦
所以 GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
GET和POST还有一个重大区别: <font color="#ff0000">GET产生一个TCP数据包;POST产生两个TCP数据包</font>
也就是说,GET只需要一次通信就把数据送到了,而POST得发两次: 第一趟,先去和服务器打个招呼,然后再回头把数据送过去
<br/>
<br/>
备注: 因为POST需要两步,时间上消耗的要多一点,看起来GET比POST更有效。因此Yahoo团队有推荐用GET替换POST来优化网站性能。但这是一个坑:
① GET与POST都有自己的语义,不能随便混用
② 在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点
③ 并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次
<br/>
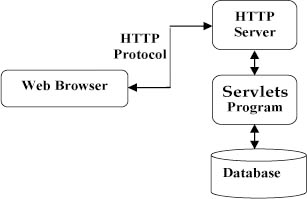
什么是Servlet
Java Servlet 是运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他 HTTP 客户端的请求和 HTTP 服务器上的数据库或应用程序之间的中间层, 如下图所示
使用 Servlet,可以收集来自网页表单的用户输入,呈现来自数据库或者其他源的记录,还可以动态创建网页
Servlet 任务
Servlet 执行以下主要任务:
Servlet 生命周期
Servlet 生命周期可被定义为从创建直到毁灭的整个过程, 以下是 Servlet 遵循的过程:
① init() 方法
init 方法被设计成只调用一次: 它在第一次创建 Servlet 时被调用,在后续每次用户请求时不再调用
Servlet 创建于用户第一次调用对应于该 Servlet 的 URL 时,但是也可以指定 Servlet 在服务器第一次启动时被加载
当用户调用一个 Servlet 时,就会创建一个 Servlet 实例,每一个用户请求都会产生一个新的线程,适当的时候移交给 doGet 或 doPost 方法
<br/>
总结: init() 方法简单地创建或加载一些配置数据,这些数据将被用于 Servlet 的整个生命周期
② service() 方法
service() 方法是执行实际任务的主要方法: Servlet 容器(即 Web 服务器)调用 service() 方法来处理来自客户端(浏览器)的请求,并把格式化的响应写回给客户端
每次服务器接收到一个 Servlet 请求时,服务器会产生一个新的线程并调用服务. service() 方法检查 HTTP 请求类型(GET、POST、PUT、DELETE 等),并在适当的时候调用 doGet、doPost、doPut,doDelete 等方法
<br/>
总结: service() 方法由容器调用,service 方法在适当的时候调用 doGet、doPost、doPut、doDelete 等方法
所以,实际编程时只需要根据来自客户端的请求类型来重写 doGet() 或 doPost() 即可
③ destroy() 方法
destroy() 方法只会被调用一次,在 Servlet 生命周期结束时被调用
destroy() 方法可以让 Servlet 关闭数据库连接、停止后台线程、把 Cookie 列表或点击计数器写入到磁盘,并执行其他类似的清理活动
在调用 destroy() 方法之后,servlet 对象被标记为垃圾回收
<br/>
下图显示了一个典型的 Servlet 生命周期方案
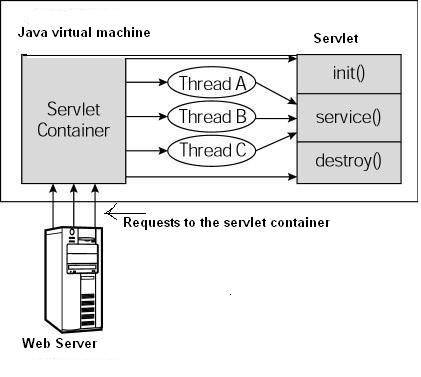
<br/>
主要是doGet()与doPost()方法:
public class ServletName extends HttpServlet {
public void doPost(HttpServletRequest request, HttpServletResponseresponse)
throws ServletException,IOException{
// POST业务逻辑...
}
public void doGet(HttpServletRequest request, HttpServletResponseresponse)
throws ServletException,IOException{
// GET业务逻辑...
}
}
说明:
doGet和doPost没什么区别,就是html表单提交的method是post的调doPost、get的调doGet;
一般情况下,无论哪种method提交的表单,处理都一样,所以只要写一个,在另一个里调这个就行了;
运行过程:
浏览器依据ip,port向服务器请求建立一个连接
浏览器将请求数据打包(按照http协议的要求,将请求数据封装成一个http请求数据包)
<url-pattern>*.do</url-pattern>,接下来, 通过反射机制创建servlet对象<br/>
forward()仅是容器中控制权的转向, 是在服务器内部请求资源: 服务器直接访问内部目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器,而浏览器根本不知道服务器发送的内容是从哪儿来的,所以它的地址栏中还是原来的地址
redirect()则是完全的跳转,即服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址,浏览器将会得到跳转的地址,并重新发送请求链接: 这样,从浏览器的地址栏中可以看到跳转后的链接地址
一般来说, 浏览器会用刚才请求的所有参数重新请求,所以session,request参数都可以获取
<br/>
总结:
forward()更加高效,在forward()可以满足需要时,尽量使用. 并且,这样也有助于隐藏实际的链接
在有些情况下,比如,需要跳转到一个其它服务器上的资源,则必须使用sendRedirect()方法
<br/>
setAttribute(String name,Object): 设置名字为name的request的参数值
getAttribute(String name): 返回由name指定的属性值
getAttributeNames(): 返回request对象所有属性的名字集合,结果是一个枚举的实例
getCookies(): 返回客户端的所有Cookie对象,结果是一个Cookie数组
getCharacterEncoding(): 返回请求中的字符编码方式
getContentLength(): 返回请求的Body的长度
getHeader(String name): 获得HTTP协议定义的文件头信息
getHeaders(String name): 返回指定名字的request Header的所有值,结果是一个枚举的实例
getHeaderNames(): 返回所以request Header的名字,结果是一个枚举的实例
getInputStream(): 返回请求的输入流,用于获得请求中的数据
getMethod(): 获得客户端向服务器端传送数据的方法
getParameter(String name): 获得客户端传送给服务器端的有name指定的参数值
getParameterNames(): 获得客户端传送给服务器端的所有参数的名字,结果是一个枚举的实例
getParametervalues(String name): 获得有name指定的参数的所有值
getProtocol(): 获取客户端向服务器端传送数据所依据的协议名称
getQueryString(): 获得查询字符串
getRequestURI(): 获取发出请求字符串的客户端地址
getRemoteAddr(): 获取客户端的IP地址
getRemoteHost(): 获取客户端的名字
getSession([Boolean create]): 返回和请求相关Session
getServerName(): 获取服务器的名字
getServletPath(): 获取客户端所请求的脚本文件的路径
getServerPort(): 获取服务器的端口号
removeAttribute(String name): 删除请求中的一个属性
<br/>
以下是两个方法的比较:
| getParameter | getAttribute |
|---|---|
| 用来接受用post个get方法传递过来的参数的 | 必须先setAttribute |
| 通过容器的实现来获得类似post,get等方式传入的数据 | 只是在web容器内部流转,仅仅是请求处理阶段 |
| 方法传递的数据,会从Web客户端传到Web服务器端,代表HTTP请求数据 | 返回String类型的内部数据, 且只会存在于Web容器内部 |
还有一点: HttpServletRequest 类有 setAttribute() 方法,而没有setParameter() 方法
举一个例子: 假如两个WEB页面间为链接关系时,就是说要从1.jsp链接到2.jsp时,被链接的是2.jsp可以通过getParameter()方法来获得请求参数
假如1.jsp里有
<form name="form1" method="post" action="2.jsp">
请输入用户姓名: <input type="text" name="username">
<input type="submit" name="Submit" value="提交">
</form>
可以在2.jsp中通过request.getParameter("username")方法来获得请求参数username:
< % String username=request.getParameter("username"); %>
<br/>
但是如果两个WEB间为转发关系时,转发目的Web可以用getAttribute()方法来和转发源Web共享request范围内的数据:
有1.jsp和2.jsp, 1.jsp希望向2.jsp传递当前的用户名字,如何传递这一数据呢?
先在1.jsp中调用如下setAttribute()方法:
<%
String username=request.getParameter("username");
request.setAttribute("username",username);
%>
<jsp:forward page="2.jsp" />
则可以在2.jsp中通过getAttribute()方法获得用户名字:
<% String username=(String)request.getAttribute("username"); %>
<br/>
总结:
① HttpServletRequest 类有setAttribute()方法,而没有setParameter()方法
② 当两个Web组件之间为链接关系时,被链接的组件通过getParameter()方法来获得请求参数
③ 当两个Web组件之间为转发关系时,转发目标组件通过getAttribute()方法来和转发源组件共享request范围内的数据
④ 一般通过表单和链接传递的参数使用getParameter
这个问题主要是request和session的差别:
request范围较小一些,只是一个请求,简单说就是你在页面上的一个操作, request.getParameter()就是从上一个页面中的url、form中获取参数,但如果一个request涉及多个类,后面还要取参数,可以用request.setAttribute()和request.getAttribute(),但是当结果输出之后,request就结束了
而session可以跨越很多页面,可以理解是客户端同一个IE窗口发出的多个请求。这之间都可以传递参数,比如很多网站的用户登录都用到了。
一般可以用getParameter得到页面参数, 字符串, getAttribute()可以得到对象
getParameter可以得到页面传来的参数如?id=123之类的, getAttribute()常用于servlet页面传递参数给jsp
<br/>
JSP共有以下9个内置的对象:
| 对象名 | 说明 | 作用 |
|---|---|---|
| request | 用户端请求,此请求会包含来自GET/POST请求的参数 | request表示HttpServletRequest对象。它包含了有关浏览器请求的信息,并且提供了几个用于获取cookie, header,和session数据的有用的方法 |
| response | 网页传回用户端的回应 | response表示HttpServletResponse对象,并提供了几个用于设置送回浏览器的响应的方法(如cookies,头信息等) |
| pageContext | 网页的属性是在这里管理 | pageContext表示一个javax.servlet.jsp.PageContext对象。它是用于方便存取各种范围的名字空间、servlet相关的对象的API,并且包装了通用的servlet相关功能的方法 |
| session | 与请求有关的会话期 | session表示一个请求的javax.servlet.http.HttpSession对象。Session可以存贮用户的状态信息 |
| application | servlet正在执行的内容 | applicaton表示一个javax.servle.ServletContext对象。这有助于查找有关servlet引擎和servlet环境的信息 |
| out | 用来传送回应的输出 | out对象是javax.jsp.JspWriter的一个实例,并提供了几个方法使你能用于向浏览器回送输出结果 |
| config | servlet的构架部件 | config表示一个javax.servlet.ServletConfig对象。该对象用于存取servlet实例的初始化参数 |
| page | JSP网页本身 | 表示从该页面产生的一个servlet实例 |
| exception | 针对错误网页,未捕捉的例外 |
<br/>
静态 INCLUDE 用 include 伪码实现 , 不会检查所含文件的变化 , 适用于包含静态页面 <%@ include file="included.html" %>: 先将文件的代码被原封不动地加入到了主页面从而合成一个文件,然后再进行翻译
动态 INCLUDE 用 jsp:include 动作实现 <jsp:include page="included.jsp" flush="true" />它总是会检查所含文件中的变化 , 适合用于包含动态页面 , 并且可以带参数。各个文件分别先编译,然后组合成一个文件
两者有几个不同点:
① 静态导入是将被导入页面的代码完全融入,两个页面融合成一个整体的servlet;而动态导入则在servlet中使用include方法来引入被导入页面的内容。
② 静态导入时被导入的页面的编译指令会起作用,而动态导入时被导入的页面的编译指令则失去作用,只是插入被导入页面的body内容。
③ 动态包含可以包含相同变量,而静态包含不行。
④ 如果被包含文件经常变动,则应该使用动态包含,而使用静态包含时,改变被包含文件后,有可能不能及时更新
<br/>