最近开始重新学习 mit-6.824,目前把Lab1做完了,在这里总结一下;
源代码根据 MIT 实验的要求,是一个Private的 repo 没有公开,需要源代码的可以联系我,也可以一起交流~
视频学习地址:
<br/>
<!--more-->目前我学习的是 2020 MIT 6.824 分布式系统,当然现在有了更新的 2021、2022 的版本,不过大致思想基本上都是一样的;
完整的 Lab 说明在这里:
在做实验之前,建议先看完 Google 的这两篇论文:
并看完 Lecture 1、2:
对 MapReduce 有一定的了解,并且对 Go 有一定的了解再下手去做;
<br/>
总的来讲,Google MapReduce 所执行的分布式计算会以一组键值对作为输入,输出另一组键值对,用户则通过编写 Map 函数和 Reduce 函数来指定所要进行的计算。
由用户编写的Map 函数将被应用在每一个输入键值对上,并输出若干键值对作为中间结果。之后,MapReduce 框架则会将与同一个键 II 相关联的值都传递到同一次 Reduce 函数调用中。
同样由用户编写的 Reduce 函数以键 II 以及与该键相关联的值的集合作为参数,对传入的值进行合并并输出合并后的值的集合。
形式化地说,由用户提供的 Map 函数和 Reduce 函数应有如下类型:
map(k1,v1) → list(k2,v2)
reduce(k2,list(v2)) → list(v2)
值得注意的是,在实际的实现中 MapReduce 框架使用 Iterator 来代表作为输入的集合,主要是为了避免集合过大,无法被完整地放入到内存中;
作为案例,我们考虑这样一个问题:给定大量的文档,计算其中每个单词出现的次数(Word Count);
用户通常需要提供形如如下伪代码的代码来完成计算:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, “1”);
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
<br/>
了解函数式编程范式的读者不难发现:MapReduce 所采用的编程模型源自于函数式编程里的 Map 函数和 Reduce 函数。后起之秀 Spark 同样采用了类似的编程模型;
使用函数式编程模型的好处在于这种编程模型本身就对并行执行有良好的支持,这使得底层系统能够轻易地将大数据量的计算并行化,同时由用户函数所提供的确定性也使得底层系统能够将函数重新执行作为提供容错性的主要手段;
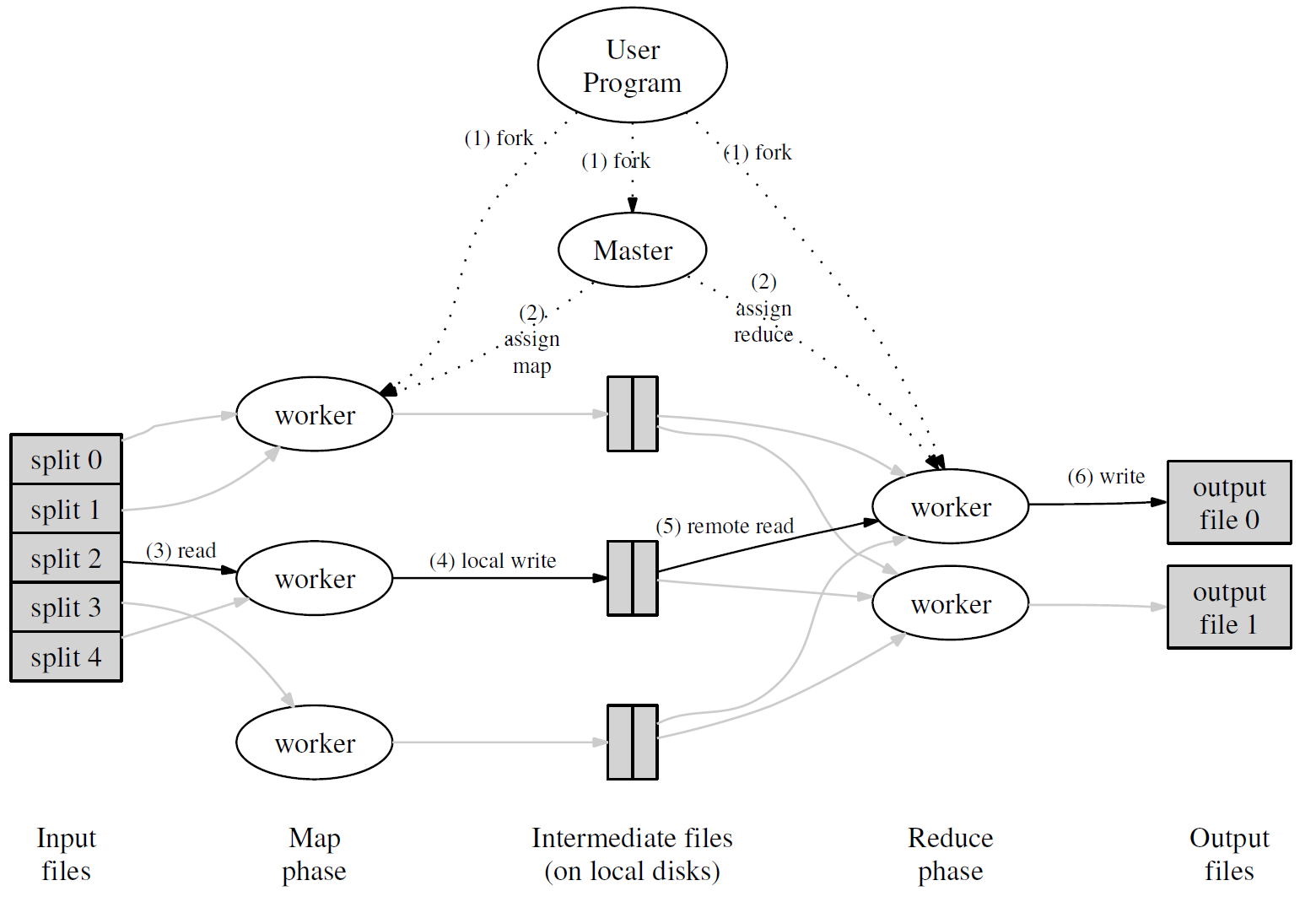
每一轮 MapReduce 的大致过程如下图所示:
首先,用户通过 MapReduce 客户端指定 Map 函数和 Reduce 函数,以及此次 MapReduce 计算的配置,包括中间结果键值对的 Partition 数量 RR 以及用于切分中间结果的哈希函数 hash;
用户开始 MapReduce 计算后,整个 MapReduce 计算的流程可总结如下:
hash(key) % R)将产生的中间结果分为RR 个部分。任务完成时,Mapper 便会将中间结果在其本地磁盘上的存放位置报告给 Master;实际上,在一个 MapReduce 集群中,Master 会记录每一个 Map 和 Reduce 任务的当前完成状态,以及所分配的 Worker;除此之外,Master 还负责将 Mapper 产生的中间结果文件的位置和大小转发给 Reducer;
值得注意的是,每次 MapReduce 任务执行时,M 和 R 的值都应比集群中的 Worker 数量要高得多,以达成集群内负载均衡的效果;
<br/>
由于 Google MapReduce 很大程度上利用了由 Google File System 提供的分布式原子文件读写操作,所以 MapReduce 集群的容错机制实现相比之下便简洁很多,也主要集中在任务意外中断的恢复上;
在 MapReduce 集群中,Master 会周期地向每一个 Worker 发送 Ping 信号:如果某个 Worker 在一段时间内没有响应,Master 就会认为这个 Worker 已经不可用;
任何分配给该 Worker 的 Map 任务,无论是正在运行还是已经完成,都需要由 Master 重新分配给其他 Worker,因为该 Worker 不可用也意味着存储在该 Worker 本地磁盘上的中间结果也不可用了;
Master 也会将这次重试通知给所有 Reducer,没能从原本的 Mapper 上完整获取中间结果的 Reducer 便会开始从新的 Mapper 上获取数据;
如果有 Reduce 任务分配给该 Worker,Master 则会选取其中尚未完成的 Reduce 任务分配给其他 Worker;
鉴于 Google MapReduce 的结果是存储在 Google File System 上的,已完成的 Reduce 任务的结果的可用性由 Google File System 提供,因此 MapReduce Master 只需要处理未完成的 Reduce 任务即可;
<br/>
整个 MapReduce 集群中只会有一个 Master 结点,因此 Master 失效的情况并不多见;
Master 结点在运行时会周期性地将集群的当前状态作为保存点(Checkpoint)写入到磁盘中;
Master 进程终止后,重新启动的 Master 进程即可利用存储在磁盘中的数据恢复到上一次保存点的状态;
<br/>
如果集群中有某个 Worker 花了特别长的时间来完成最后的几个 Map 或 Reduce 任务,整个 MapReduce 计算任务的耗时就会因此被拖长,这样的 Worker 也就成了落后者(Straggler)!
<font color="#f00">**MapReduce 在整个计算完成到一定程度时就会将剩余的任务进行备份,即同时将其分配给其他空闲 Worker 来执行,并在其中一个 Worker 完成后将该任务视作已完成;**</font>
<br/>
在高可用的基础上,Google MapReduce 系统现有的实现同样采取了一些优化方式来提高系统运行的整体效率;
在 Google 内部所使用的计算环境中,机器间的网络带宽是比较稀缺的资源,需要尽量减少在机器间过多地进行不必要的数据传输;
Google MapReduce 采用 Google File System 来保存输入和结果数据,因此 Master 在分配 Map 任务时会从 Google File System 中读取各个 Block 的位置信息,并尽量将对应的 Map 任务分配到持有该 Block 的 Replica 的机器上;
如果无法将任务分配至该机器,Master 也会利用 Google File System 提供的机架拓扑信息将任务分配到较近的机器上;
<br/>
在某些情形下,用户所定义的 Map 任务可能会产生大量重复的中间结果键,同时用户所定义的 Reduce 函数本身也是满足交换律和结合律的;
在这种情况下,Google MapReduce 系统允许用户声明在 Mapper 上执行的 Combiner 函数:Mapper 会使用由自己输出的 R 个中间结果 Partition 调用 Combiner 函数以对中间结果进行局部合并,减少 Mapper 和 Reducer 间需要传输的数据量;
以上内容转自:
<br/>
Lab1 所需要的环境非常简单,只需要你的电脑安装 Go 即可;
实验要求的环境是 Go 1.13,但是我的环境是 Go 1.18;
但是由于 Go 良好向前兼容的特性,也是可以用的!
获取代码也非常简单,直接通过 Git Clone 下来就可以了:
$ git clone git://g.csail.mit.edu/6.824-golabs-2020 6.824
$ cd 6.824
Clone 下来的代码默认已经提供了一个简单的顺序执行的 MapReduce 实现在:src/main/mrsequential.go;
同时在 mrapps/ 目录下,也提供了几个 MapReduce 的应用(主要是实现 Map、Reduce 两个函数),后面测试的时候会用到;
可以简单的先做一个测试:
$ cd src/main
# 构建 MapReduce APP 的动态链接库
$ go build -buildmode=plugin ../mrapps/wc.go
# 执行顺序实现的MapReduce例子
$ rm mr-out*
$ go run mrsequential.go wc.so pg*.txt
# 验证结果
$ more mr-out-0
A 509
ABOUT 2
ACT 8
...
看到成功输出了文件 mr-out-0 就说明我们的环境是OK的!
在我们开始实验之前,先看一下上面的例子到底做了点啥;
首先,通过 go build -buildmode=plugin ../mrapps/wc.go 将 WordCount 应用编译为了动态链接库;
在后面使用的时候,使用内置的
plugin库中的Lookup函数直接加载了 Map 和 Reduce 函数进行调用;关于
plugin库:
mrapps/wc.go 中的逻辑非常简单:
package main
// a word-count application "plugin" for MapReduce.
// go build -buildmode=plugin wc.go
import "../mr"
import "unicode"
import "strings"
import "strconv"
// The map function is called once for each file of input. The first
// argument is the name of the input file, and the second is the
// file's complete contents. You should ignore the input file name,
// and look only at the contents argument. The return value is a slice
// of key/value pairs.
func Map(filename string, contents string) []mr.KeyValue {
// function to detect word separators.
ff := func(r rune) bool { return !unicode.IsLetter(r) }
// split contents into an array of words.
words := strings.FieldsFunc(contents, ff)
kva := []mr.KeyValue{}
for _, w := range words {
kv := mr.KeyValue{w, "1"}
kva = append(kva, kv)
}
return kva
}
// The reduce function is called once for each key generated by the
// map tasks, with a list of all the values created for that key by
// any map task.
func Reduce(key string, values []string) string {
// return the number of occurrences of this word.
return strconv.Itoa(len(values))
}
就是定义了 Map、Reduce 两个函数,而不必关心后面的任务是如何调度的(分布式 or 顺序执行);
随后执行:go run mrsequential.go wc.so pg*.txt 指定了 MapReduce 动态连接库,以及提前准备好的测试文件(以 pg 开头);
下面来看看顺序执行的 MapReduce 的实现:
src/main/mrsequential.go
package main
// simple sequential MapReduce.
// go run mrsequential.go wc.so pg*.txt
import "fmt"
import "../mr"
import "plugin"
import "os"
import "log"
import "io/ioutil"
import "sort"
// for sorting by key.
type ByKey []mr.KeyValue
// for sorting by key.
func (a ByKey) Len() int { return len(a) }
func (a ByKey) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByKey) Less(i, j int) bool { return a[i].Key < a[j].Key }
func main() {
if len(os.Args) < 3 {
fmt.Fprintf(os.Stderr, "Usage: mrsequential xxx.so inputfiles...\n")
os.Exit(1)
}
mapf, reducef := loadPlugin(os.Args[1])
// read each input file,
// pass it to Map,
// accumulate the intermediate Map output.
intermediate := []mr.KeyValue{}
for _, filename := range os.Args[2:] {
file, err := os.Open(filename)
if err != nil {
log.Fatalf("cannot open %v", filename)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", filename)
}
file.Close()
kva := mapf(filename, string(content))
intermediate = append(intermediate, kva...)
}
// a big difference from real MapReduce is that all the
// intermediate data is in one place, intermediate[],
// rather than being partitioned into NxM buckets.
sort.Sort(ByKey(intermediate))
oname := "mr-out-0"
ofile, _ := os.Create(oname)
// call Reduce on each distinct key in intermediate[],
// and print the result to mr-out-0.
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values)
// this is the correct format for each line of Reduce output.
fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output)
i = j
}
ofile.Close()
}
// load the application Map and Reduce functions
// from a plugin file, e.g. ../mrapps/wc.so
func loadPlugin(filename string) (func(string, string) []mr.KeyValue, func(string, []string) string) {
p, err := plugin.Open(filename)
if err != nil {
log.Fatalf("cannot load plugin %v", filename)
}
xmapf, err := p.Lookup("Map")
if err != nil {
log.Fatalf("cannot find Map in %v", filename)
}
mapf := xmapf.(func(string, string) []mr.KeyValue)
xreducef, err := p.Lookup("Reduce")
if err != nil {
log.Fatalf("cannot find Reduce in %v", filename)
}
reducef := xreducef.(func(string, []string) string)
return mapf, reducef
}
直接从 main 函数开始看:
首先从动态连接库中获取 Map 和 Reduce 函数;
随后,读取每一个输入的文件,并使用 Map 函数处理,并将处理后的结果存入 intermediate 临时数组中;
紧接着,对 intermediate 临时数组在 Key 上排序,这也是 MapReduce 论文中要求的;
最后,由于按照 Key 值排序后的中间数组相同的 Key 值连续排列,因此我们对相同 Key 值调用 Reduce 进行聚合,并输出到文件中;
至此我们的顺序执行 MapReduce 结束;
可以看到,顺序执行的 MapReduce 的实现是非常简单的;下面我们来看我们要做的实验;
<br/>
根据实验内容,我们要做的是:实现一个 单机、多进程、并行 版本的 MapReduce;
实现包括两个独立的部分:单独的 master 和 多个并行的 worker 进程,两者通过 rpc 调用通信;
每个 worker 进程都会向 master 索要任务、读取任务指定的文件、执行任务并最终将结果写入多个输出文件中;
并且,为了模拟在分布式场景下程序的 worker 挂掉的场景,master 需要处理当一段时间内 worker 都没有完成任务(实验指定的是10秒钟),则需要将任务交给其他 worker 去做;
实验已经提供了部分代码: main/mrmaster.go 和 main/mrworker.go(无需修改);
只需要将实现写在: mr/master.go, mr/worker.go、 mr/rpc.go 即可;
同时,也提供了在开发的时候进行测试的方法:
首先,启动 master 节点:
$ go run mrmaster.go pg-*.txt
随后在多个新的终端启动多个 worker 节点:
$ go run mrworker.go wc.so
即可测试;
同时,实验提供了测试脚本用于整个实验的测试:test-mr.sh;
关于实验的一些规则:
nReduce 个 reduce 任务,这个参数是调用 MakeMaster() 函数时指定的!mr-out-X;mr-out-X 应当每行一个输出,并且采用 "%v %v" 格式(和 main/mrsequential.go 一致);main/mrmaster.go 调用 mr/master.go 的 Done 函数返回 true 时,其认为所有任务都已完成,将会退出;call rpc 与 master 通信失败时,认为任务结束;不过一个另外一个做法是当任务结束后,master 下发一个 请退出 的任务,交给 worker 去执行;一些提示:
mr/ 目录下的文件,你应该重新使用 go build -buildmode=plugin ../mrapps/wc.go 编译;mr-X-Y,X 表示 Map 任务Id、Y 表示 Reduce 任务Id;ihash(key) 函数来计算由哪个 worker 来执行对应 Key 的 Reduce 任务;mrapps/crash.go 测试节点挂掉后的恢复,他的 Map、Reduce 函数会随机直接退出(模拟 worker 节点在被分配任务后挂掉);通过上面的任务,我们可以总结出:
对于 master 节点要做到:
对于 worker 节点:
<br/>
一个难点在于:在执行 Reduce 任务时,需要根据指定的 nReduce 数进行分配;
解决方法是:我们可以通过计算 ihash(key) 来定义中间产物文件,来记录每个 Reduce 所在的文件;
另一个难点在于:有可能存在两个 worker 同时执行同一个任务的情况,此时要保证只有一个 Worker 能够完成结果数据的最终写出,以免出现冲突导致最终观察到重复或缺失的结果数据;
我们可以通过实验给出的提示:通过临时文件的方法解决;即:
Worker 写出数据时,先写出到临时文件(Write),最终确认没有问题后再将其重命名(Commit)为正式结果文件,区分开了 Write 和 Commit 的过程;
而 Commit 的过程可以是 Master 来执行,也可以是 Worker 来执行:
上面两种方法都是可行的;
我的实现选择了 Master Commit,因为可以少一次 RPC 调用,在实现上会更简单;但缺点是所有 Task 最终 Commit 都由 Master 完成,在极端场景下会让 Master 变成整个 MR 过程的性能瓶颈;
<br/>
代码的实现主要分为三个部分,并且实验已经提供好了对应的文件:
下面我们一个一个来看;
RPC 通信主要是用来:
在实现时,因为上面两个步骤可以合并为一个步骤,因此,可以用一个 RPC 调用完成上面两个事情;
即:在 Query 下一个任务的时候,Commit 上一个任务;
特别的:
RPC 的请求与相应结构体定义如下:
src/mr/rpc.go
// TaskTypeOpt The MapReduce task type
type TaskTypeOpt string
const (
TaskTypeMap TaskTypeOpt = "Map"
TaskTypeReduce TaskTypeOpt = "Reduce"
TaskTypeFinished TaskTypeOpt = "Finished"
)
// TaskInfo The MapReduce task
type TaskInfo struct {
Id string
Type TaskTypeOpt
Index int
File string
WorkerId string
Deadline time.Time
}
// AckAndQueryNewTaskRequest RPC request for Workers to query a task after finished previously task
type AckAndQueryNewTaskRequest struct {
// The finished previous task index (if it has finished task)
PreviousTaskIndex int
TaskType TaskTypeOpt
WorkerId string
}
// AckAndQueryNewTaskResponse RPC response for Workers to query a task
type AckAndQueryNewTaskResponse struct {
// The task id(filename) for Map or Reduce to yield results(if there has)
Task *TaskInfo
MapWorkerCnt int
ReduceWorkerCnt int
}
首先定义了 TaskTypeOpt 类型,标志任务的类型,包括三种:
"Map":Map 任务;"Reduce":Reduce 任务;"Finished":任务已完成,提示 Worker 可以退出;TaskInfo 表示一个任务实体,包括:
我们 RPC 的名称为 AckAndQueryNewTask,包括 Request 和 Response 两个部分;
AckAndQueryNewTaskRequest 包括:
PreviousTaskIndex:上一个执行完成任务的索引,用于 Commit 上一个任务;TaskType:上一个执行完成任务的类型,用于 Commit 上一个任务;WorkerId:上一个执行完成任务的 WorkerId(本 WorkerId),用于 Master 校验到底是哪个 Worker 执行任务(Failover 策略);AckAndQueryNewTaskResponse 包括:
*TaskInfo 类型,新申请的任务,如果不存在可调度的任务,则返回 nil;<br/>
Master 主要是完成下面几个功能:
AckAndQueryNewTask 方法,实现任务的分配、上一个任务的 Commit;因此,Master 需要维护下面的信息:
下面是 Master 结构的定义:
src/mr/master.go
type Master struct {
// Use lock to avoid data race
lock sync.RWMutex
// The phase of all tasks
status TaskTypeOpt
// The count of the workers
mapCnt int
reduceCnt int
// All tasks
tasks map[string]*TaskInfo
// All ongoing tasks
availableTasks chan *TaskInfo
}
其中:
<br/>
当创建一个 Master 后主要需要做以下几个事情:
Master 的初始化主要是在 src/main/mrmaster.go 中通过调用 MakeMaster 函数实现的;
下面来看:
src/mr/master.go
// MakeMaster create a Master.
// main/mrmaster.go calls this function.
// nReduce is the number of reduce tasks to use.
func MakeMaster(files []string, nReduce int) *Master {
// Step 1: Create master
m := &Master{
status: TaskTypeMap,
mapCnt: len(files),
reduceCnt: nReduce,
tasks: make(map[string]*TaskInfo),
availableTasks: make(chan *TaskInfo, max(len(files), nReduce)),
}
// Step 2: Store the data
for idx, file := range files {
task := &TaskInfo{
Id: generateTaskId(TaskTypeMap, idx),
Type: TaskTypeMap,
Index: idx,
File: file,
}
m.tasks[task.Id] = task // Store the tasks
m.availableTasks <- task // Send the task to the channel
}
// Step 3: Start master server
m.server()
infof("master server started: %v", m)
// Step 4: Start workers heartbeats checker
go func() {
for {
time.Sleep(500 * time.Millisecond)
m.checkWorkers()
}
}()
return m
}
代码首先初始化了 Master 的各个属性,将最初状态设置为 Map 类型的 Task;
随后,遍历输入的文件,为每个文件创建 Task,并存入 tasks 和 availableTasks 中;
这里生成 TaskId 的函数非常简单:
src/mr/rpc.go
// generateTaskId Generate TaskId for the given task
// The id follows the format: "taskType-taskIndex"
func generateTaskId(taskType TaskTypeOpt, index int) string {
return fmt.Sprintf("%s-%d", taskType, index)
}
随后,启动 RPC Server:
src/mr/master.go
// start a thread that listens for RPCs from worker.go
func (m *Master) server() {
_ = rpc.Register(m)
rpc.HandleHTTP()
//l, e := net.Listen("tcp", ":1234")
sockname := masterSock()
_ = os.Remove(sockname)
l, e := net.Listen("unix", sockname)
if e != nil {
log.Fatal("listen error:", e)
}
go http.Serve(l, nil)
}
这里只是使用实验提供的方法,并未进行修改;
最后,在一个新开的协程中调用 checkWorkers 轮询我们的任务(后文会讲);
至此,我们的 Master 创建并初始化完毕,会在 src/main/mrmaster.go 中调用 Done 方法等待退出:
src/main/mrmaster.go
m := mr.MakeMaster(os.Args[1:], 10)
for m.Done() == false {
time.Sleep(time.Second)
}
因此,我们只需要在 Master 处理完所有任务后,在 Done 中返回 true 即可!
<br/>
Task的获取与分配主要是通过 RPC 方法 AckAndQueryNewTask 实现的:
src/mr/master.go
func (m *Master) AckAndQueryNewTask(req *AckAndQueryNewTaskRequest,
resp *AckAndQueryNewTaskResponse) error {
// Step 1: Mark previous task finished if necessary
if req.TaskType != "" {
err := m.handlePreviousTask(req)
if err != nil {
errorf("handlePreviousTask err: %v", err)
return err
}
}
// Step 2: Get the next task
task, ok := <-m.availableTasks
if !ok { // Channel closed: no available tasks
m.lock.RLock()
defer m.lock.RUnlock()
retTask := &TaskInfo{}
if m.status == TaskTypeFinished {
retTask.Type = TaskTypeFinished
}
resp.Task = retTask
return nil
}
// Step 3: Assign the task to the worker
m.lock.Lock()
defer m.lock.Unlock()
infof("Assign task %v to worker %s", task, req.WorkerId)
task.WorkerId = req.WorkerId
task.Deadline = time.Now().Add(10 * time.Second)
m.tasks[generateTaskId(task.Type, task.Index)] = task
// Step 4: Handle response
resp.Task = &TaskInfo{
Id: task.Id,
Type: task.Type,
Index: task.Index,
File: task.File,
WorkerId: task.WorkerId,
Deadline: task.Deadline,
}
resp.MapWorkerCnt = m.mapCnt
resp.ReduceWorkerCnt = m.reduceCnt
return nil
}
正如我们前面所讲的,当 Worker 发送一个新的 Task 请求时,会提交上一次的任务;
因此代码首先判断了是否存在上一个任务,如果存在上一个任务,则调用 handlePreviousTask 首先处理上一个任务(见后文);
随后通过 <-m.availableTasks 获取下一个任务;这里需要注意:
对上面有疑问的可以参考这个简单的例子:
因此,如果 Channel 已经关闭,并且当前的任务状态为 Finished 我们只需要给 Worker 发送任务已经完成的任务响应即可!
否则,如果我们获取到了任务,那么我们需要设置:
并将它写入我们的 tasks 中用于跟踪任务状态;
最后,响应我们的 Worker 即可!
<br/>
前面说到,在 RPC 的第一步,如果存在前一个提交的任务,则会调用 handlePreviousTask 处理上一个任务;
下面我们来看这里:
src/mr/master.go
var (
taskFinishHandlerMap = map[TaskTypeOpt]func(workerId string, taskIdx, reduceCnt int) error{
TaskTypeMap: handleFinishedMapTask,
TaskTypeReduce: handleFinishedReduceTask,
}
)
// handle the previous finished task
func (m *Master) handlePreviousTask(req *AckAndQueryNewTaskRequest) error {
previousTaskId := generateTaskId(req.TaskType, req.PreviousTaskIndex)
m.lock.Lock()
defer m.lock.Unlock()
taskInfo, exists := m.tasks[previousTaskId]
if exists {
if taskInfo.WorkerId == req.WorkerId { // This task belongs to the worker
infof("Mark task [%v] finished on worker %s", taskInfo, req.WorkerId)
// Step 1: Handle the previous finished task
handler, handlerExists := taskFinishHandlerMap[taskInfo.Type]
if !handlerExists || handler == nil {
return fmt.Errorf("handler not found for task: %v", taskInfo)
}
err := handler(req.WorkerId, req.PreviousTaskIndex, m.reduceCnt)
if err != nil {
errorf("Failed to handle previous task: %v", err)
return err
}
delete(m.tasks, previousTaskId)
// Step 2: Transit job phase if necessary
if len(m.tasks) <= 0 {
m.transit()
}
return nil
} else { // The task is no longer belongs to this worker
infof("Task %v is no longer belongs to this worker", taskInfo)
return nil
}
} else { // Previous task not found in task map(worker retry ack maybe)!
warnf("[Warn] Previous task: %v not found in map", taskInfo)
return nil
}
}
首先创建上一个任务的Id:previousTaskId,这也是我们 Map 中的 Key;
随后,从 Map 中取出这个 Task(如果不存在,则无需处理了!);
接下来校验这个任务是否属于当前提交任务的 Worker(taskInfo.WorkerId == req.WorkerId):
如果当前任务已经不属于当前提交任务的 Worker,那么我们直接忽略掉即可!
<font color="#f00">**这里就避免了由于 Fallover 处理而导致的多个 Worker 同时处理同一个 Task 并提交的问题!**</font>
否则,这是一个我们需要处理的 Commit,那么我们从 taskFinishHandlerMap 中获取到不同类型的任务对应的 Handler 进行处理;
当处理成功后,我们从 tasks 中去掉这个任务;
并且如果当前所有的任务都已处理完成,那么调用 transit 来推进整个 Job 的状态;
<br/>
对于不同的任务类型的处理函数是通过下面的 Map 中获取的:
src/mr/master.go
var (
taskFinishHandlerMap = map[TaskTypeOpt]func(workerId string, taskIdx, reduceCnt int) error{
TaskTypeMap: handleFinishedMapTask,
TaskTypeReduce: handleFinishedReduceTask,
}
)
这两个函数的实现如下:
src/mr/master.go
// The map-type task finished handler
func handleFinishedMapTask(workerId string, taskIdx, reduceCnt int) error {
// Mark the task's temporary file to final file(Rename)
for reduceIdx := 0; reduceIdx < reduceCnt; reduceIdx++ {
tmpMapFileName := tmpMapOutFile(workerId, taskIdx, reduceIdx)
finalMapOutFileName := finalMapOutFile(taskIdx, reduceIdx)
err := os.Rename(tmpMapFileName, finalMapOutFileName)
if err != nil {
errorf("Failed to mark map output file `%s` as final: %e", tmpMapFileName, err)
return err
}
}
infof("handleFinishedMapTask success: workerId: %s, taskIdx: %d", workerId, taskIdx)
return nil
}
// The reduce-type task finished handler
func handleFinishedReduceTask(workerId string, taskIdx, _ int) error {
// Mark the task's temporary file to final file(Rename)
tmpReduceFileName := tmpReduceOutFile(workerId, taskIdx)
finalReduceOutFileName := finalReduceOutFile(taskIdx)
err := os.Rename(tmpReduceFileName, finalReduceOutFileName)
if err != nil {
errorf("Failed to mark reduce output file `%s` as final: %v", tmpReduceFileName, err)
return err
}
infof("handleFinishedReduceTask success: workerId: %s, taskIdx: %d, finalReduceOutFileName: %s",
workerId, taskIdx, finalReduceOutFileName)
return nil
}
// The temporary file that map-type task yield
func tmpMapOutFile(workerId string, taskIdx, reduceIdx int) string {
return fmt.Sprintf("mr-map-%s-%d-%d", workerId, taskIdx, reduceIdx)
}
// The final file that map-type task yield(for reduce)
func finalMapOutFile(taskIdx, reduceIdx int) string {
return fmt.Sprintf("mr-map-%d-%d", taskIdx, reduceIdx)
}
// The temporary file that reduce-type task yield
func tmpReduceOutFile(workerId string, reduceIdx int) string {
return fmt.Sprintf("mr-reduce-%s-%d", workerId, reduceIdx)
}
// The final file that reduce-type task yield(the MapReduce task yield)
func finalReduceOutFile(taskIndex int) string {
return fmt.Sprintf("mr-out-%d", taskIndex)
}
两个函数的内容基本上是一样的:
都是首先通过任务 Id 获取到对应输出的临时文件,然后将其重命名为对应任务的最终产出文件!
这和我们最开始的分析是一致的!
<br/>
在前面的 RPC 调用中,如果发现某个类型(Map、Reduce)当前的任务全部完成,则会调用 transit 函数切换当前 Job 的状态,代码如下:
src/mr/master.go
// Transit the job phase (from Map to Reduce)
func (m *Master) transit() {
if m.status == TaskTypeMap {
// All map-type tasks finished, change to reduce phase
infof("All map-type tasks finished. Transit to REDUCE stage!")
m.status = TaskTypeReduce
// Yield Reduce Tasks
for reduceIdx := 0; reduceIdx < m.reduceCnt; reduceIdx++ {
task := &TaskInfo{
Type: TaskTypeReduce,
Index: reduceIdx,
}
m.tasks[generateTaskId(task.Type, task.Index)] = task
m.availableTasks <- task
}
} else if m.status == TaskTypeReduce {
// All reduce-type tasks finished, ready to exit
infof("All reduce-type tasks finished. Prepare to exit!")
// Close channel
close(m.availableTasks)
// Mark status to TaskTypeFinished for job completion
m.status = TaskTypeFinished
}
}
逻辑如下:
<br/>
前面在创建并初始化 Master 的时候说到,初始化 Master 后,会单独起一个协程去轮询 Worker 的状态,用于清理那些超时的 Worker;
这里来看这个 checkWorkers 函数:
src/mr/master.go
// Check all workers heartbeats
func (m *Master) checkWorkers() {
m.lock.Lock()
defer m.lock.Unlock()
for _, task := range m.tasks {
if task.WorkerId != "" && time.Now().After(task.Deadline) {
infof(
"Found timed-out task:%v, previously running on worker %s. Prepare to re-assign...",
task, task.WorkerId)
task.WorkerId = ""
m.availableTasks <- task
}
}
}
主要是遍历 tasks 中的任务,如果发现超时的(time.Now().After(task.Deadline)),则将其 WorkerId 置为空,并放入 availableTasks Channel 中重新分配任务;
<font color="#f00">**这里其实是可以进行优化的,即:使用小根堆从 `Deadline` 最早的一个任务进行遍历来减少开销;**</font>
<br/>
最后,当全部任务结束后,Master 的状态会变为:Finished;
因此,我们只需要判断我们 Master 当前的状态是否为 Finished 即可:
src/mr/master.go
// main/mrmaster.go calls Done() periodically to find out
// if the entire job has finished.
func (m *Master) Done() bool {
m.lock.RLock()
defer m.lock.RUnlock()
taskPhase := m.status
infof("current task phase: %s, res task count: %d", taskPhase, len(m.availableTasks))
// All tasks have finished
return taskPhase == TaskTypeFinished
}
<br/>
Worker 的实现就比较简单了,主要是一个死循环,不断地向 Master 调用 AckAndQueryNewTask:
下面先来看 Worker 初始化的代码;
<br/>
在 main/mrworker.go 中调用 Worker 函数对 Worker 进行初始化,代码如下:
src/mr/worker.go
// main/mrworker.go calls this function.
func Worker(mapFunc func(string, string) []KeyValue,
reduceFunc func(string, []string) string) {
// Done Your worker implementation here.
workerId := generateWorkerId()
infof("Worker %v started!\n", workerId)
// Fire the worker to receive tasks
var previousTaskType TaskTypeOpt
var previousTaskIndex int
var taskErr error
for {
// Step 1: Query Task & Ack the last task
req := AckAndQueryNewTaskRequest{
WorkerId: workerId,
PreviousTaskIndex: previousTaskIndex,
TaskType: previousTaskType,
}
resp := AckAndQueryNewTaskResponse{}
succeed := call("Master.AckAndQueryNewTask", &req, &resp)
if !succeed {
errorf("Failed to call AckAndQueryNewTask, retry 1 second later")
time.Sleep(time.Second)
continue
}
infof("Call AckAndQueryNewTaskResponse success! req: %v, resp: %v", &req, &resp)
// Extra Step: Job finished, exit
if resp.Task.Type == TaskTypeFinished {
// Job finished, exit
infof("Received job finish signal from master, exit")
break
}
// Step 2: handle the queried task
if resp.Task.Type == TaskTypeMap {
taskErr = handleMapTask(&resp, workerId, mapFunc)
if taskErr != nil {
errorf("Failed to handleMapTask: %v, err: %v", resp.Task, taskErr)
continue
}
} else if resp.Task.Type == TaskTypeReduce {
taskErr = handleReduceTask(&resp, workerId, reduceFunc)
if taskErr != nil {
errorf("Failed to handleReduceTask: %v, err: %v", resp.Task, taskErr)
continue
}
} else {
errorf("No handler to handle task: %v", resp.Task)
continue
}
// Step 3: save finished task info, ack for the next iteration
previousTaskType = resp.Task.Type
previousTaskIndex = resp.Task.Index
infof("Finished task: %v on worker: %s\n", resp.Task, workerId)
}
infof("Worker %v finished!\n", workerId)
}
// Use pid as the workerId(standalone type)
func generateWorkerId() string {
return strconv.Itoa(os.Getpid())
}
代码首先通过 generateWorkerId 将当前Worker的 PID 作为 WorkerId(便于Debug排查问题);
随后,进入 for 循环中,首先调用 RPC 获取任务;
这里需要注意的是,首次调用时,
previousTaskIndex、previousTaskType都为空,所以不会提交任务;
在获取到任务之后进行判断:
Finished 类型的任务,则直接退出;Map 或 Reduce 类型的任务,则分别调用不同的处理函数进行处理;最后,如果成功处理了任务,则将本次的任务信息赋值给 previousTaskIndex、previousTaskType,在下一个 for 循环开始后,会对 Task 进行 Commit;
下面来看 Map、Reduce任务的处理;
<br/>
和实验提供的顺序执行的 MapReduce 实现类似,这里的 Map 任务也是读取 Task 指定的文件,调用 Map 函数,并输出临时的中间结果文件;
和之前不同的是,这里需要根据 Reduce 任务的个数对输出进行分桶操作,而即使对应的 Key 在哪个 Bucket 的函数,实验也已经提供了:ihash;
Map 任务处理代码如下:
src/mr/worker.go
// The map-type task handler for worker
func handleMapTask(resp *AckAndQueryNewTaskResponse,
workerId string, mapFunc func(string, string) []KeyValue) error {
// Step 1: Read task file
taskFile, err := os.Open(resp.Task.File)
if err != nil {
errorf("Failed to open map input file %s: %v", resp.Task.File, err)
return err
}
content, err := ioutil.ReadAll(taskFile)
if err != nil {
errorf("Failed to read map input file %s: %v", resp.Task.File, err)
return err
}
// Step 2: Use MapFunc to yield intermediate results
// Key: FileName, Value: FileContent
// Then Hash the key by ihash func, and push result into different buckets
mapResults := mapFunc(resp.Task.File, string(content))
hashedKva := make(map[int][]KeyValue)
for _, kv := range mapResults {
hashed := ihash(kv.Key) % resp.ReduceWorkerCnt
hashedKva[hashed] = append(hashedKva[hashed], kv)
}
// Step 3: Writes all intermediate results into intermediate files
for idx := 0; idx < resp.ReduceWorkerCnt; idx++ {
tmpFileName := tmpMapOutFile(workerId, resp.Task.Index, idx)
intermediateFile, _ := os.Create(tmpFileName)
for _, kv := range hashedKva[idx] {
// The intermediate file format is: ${key}\t${value}\n
_, err = fmt.Fprintf(intermediateFile, "%v\t%v\n", kv.Key, kv.Value)
if err != nil {
errorf("Write intermediate file: %s failed, err: %v", intermediateFile, err)
intermediateFile.Close()
return err
}
}
intermediateFile.Close()
}
infof("Worker[%s] writes intermediate files success, task: %v", workerId, resp.Task)
return nil
}
// use ihash(key) % NReduce to choose the reducer
// task number for each KeyValue emitted by Map.
func ihash(key string) int {
h := fnv.New32a()
_, _ = h.Write([]byte(key))
return int(h.Sum32() & 0x7fffffff)
}
代码首先从 Task 指定的文件中读取内容;
随后调用 APP 中提供的 mapFunc,并将得到的 Key 值进行 ihash(kv.Key) % resp.ReduceWorkerCnt 后,放入到对应的 hashedKva 桶中;
最后,分桶写入到了不同的临时文件中!
<br/>
Reduce 任务的实现也与顺序执行的 MapReduce 实现类似,代码如下:
src/mr/worker.go
// The reduce-type task handler for worker
func handleReduceTask(resp *AckAndQueryNewTaskResponse,
workerId string, reduceFunc func(string, []string) string) error {
// Step 1: Read the corresponding file
var lines []string
for mi := 0; mi < resp.MapWorkerCnt; mi++ {
inputFile := finalMapOutFile(mi, resp.Task.Index)
file, err := os.Open(inputFile)
if err != nil {
errorf("Failed to open map output file %s: %v", inputFile, err)
return err
}
content, err := ioutil.ReadAll(file)
if err != nil {
errorf("Failed to read map output file %s: %v", inputFile, err)
return err
}
lines = append(lines, strings.Split(string(content), "\n")...)
}
// Step 2: Format the lines
var mapResults []KeyValue
for _, line := range lines {
if strings.TrimSpace(line) == "" {
continue
}
parts := strings.Split(line, "\t")
mapResults = append(mapResults, KeyValue{
Key: parts[0],
Value: parts[1],
})
}
// Step 3: Sort the results
sort.Sort(ByKey(mapResults))
// Step 4: Write the results(Just as the mrsequential.go do!)
tmpFileName := tmpReduceOutFile(workerId, resp.Task.Index)
tmpFile, _ := os.Create(tmpFileName)
defer tmpFile.Close()
// Step 5: Call Reduce on each distinct key in mapResults[], and write the intermediate result.
i := 0
for i < len(mapResults) {
// Step 5.1: Find the same key in mapResults
j := i + 1
for j < len(mapResults) && mapResults[j].Key == mapResults[i].Key {
j++
}
var values []string
for k := i; k < j; k++ {
values = append(values, mapResults[k].Value)
}
// Step 5.2: Call reduceFunc
output := reduceFunc(mapResults[i].Key, values)
// Step 5.3: Save the yield reduce results to intermediate files.
_, _ = fmt.Fprintf(tmpFile, "%v %v\n", mapResults[i].Key, output)
i = j
}
return nil
}
由于执行 Reduce 任务时,所有的 Map 任务一定都是被 Commit 过的;
因此,我们可以找到所有 Map 任务最终 Commit 生成的文件并读取内容到 mapResults []KeyValue 中;
随后,根据论文的内容,我们对结果进行排序,并对相同的 Key 进行归并;
最后,和上面一样,我们将 Reduce 的结果输出到临时的文件;
至此,Reduce 任务结束!
<br/>
开发完成后,我们来进行测试;
直接在 src/main 目录下执行 ./test-mr.sh 即可测试;
别忘了打开
RACE=-race!
通过最后的输出可以看到,所有的用例都通过了!
*** Starting wc test.
--- wc test: PASS
*** Starting indexer test.
--- indexer test: PASS
*** Starting map parallelism test.
--- map parallelism test: PASS
*** Starting reduce parallelism test.
--- reduce parallelism test: PASS
*** Starting crash test.
--- crash test: PASS
*** PASSED ALL TESTS
同时输出了大量 INFO 级别的日志:
2022/10/12 22:21:11 [INFO]master server started: &{{{0 0} 0 0 0 0} Map 8 10 map[Map-0:0xc000078180 Map-1:0xc0000781e0 Map-2:0xc000078240 Map-3:0xc0000782a0 Map-4:0xc000078300 Map-5:0xc000078360 Map-6:0xc0000783c0 Map-7:0xc000078420] 0xc000078120}
2022/10/12 22:21:11 [INFO]current task phase: Map, res task count: 8
2022/10/12 22:21:12 [INFO]Worker 58334 started!
2022/10/12 22:21:12 [INFO]Worker 58333 started!
2022/10/12 22:21:12 [INFO]Worker 58335 started!
2022/10/12 22:21:12 [INFO]Assign task &{Map-0 Map 0 ../pg-being_ernest.txt 0001-01-01 00:00:00 +0000 UTC} to worker 58333
2022/10/12 22:21:12 [INFO]Assign task &{Map-1 Map 1 ../pg-dorian_gray.txt 0001-01-01 00:00:00 +0000 UTC} to worker 58334
2022/10/12 22:21:12 [INFO]Assign task &{Map-2 Map 2 ../pg-frankenstein.txt 0001-01-01 00:00:00 +0000 UTC} to worker 58335
2022/10/12 22:21:12 [INFO]Call AckAndQueryNewTaskResponse success! req: &{0 58334}, resp: &{0xc000114ae0 8 10}
2022/10/12 22:21:12 [INFO]Call AckAndQueryNewTaskResponse success! req: &{0 58333}, resp: &{0xc0001329c0 8 10}
2022/10/12 22:21:12 [INFO]Call AckAndQueryNewTaskResponse success! req: &{0 58335}, resp: &{0xc000076720 8 10}
2022/10/12 22:21:12 [INFO]current task phase: Map, res task count: 5
2022/10/12 22:21:13 [INFO]Worker[58333] writes intermediate files success, task: &{Map-0 Map 0 ../pg-being_ernest.txt 58333 2022-10-12 22:21:22.861303 +0800 CST}
2022/10/12 22:21:13 [INFO]Finished task: &{Map-0 Map 0 ../pg-being_ernest.txt 58333 2022-10-12 22:21:22.861303 +0800 CST} on worker: 58333
2022/10/12 22:21:13 [INFO]Mark task [&{Map-0 Map 0 ../pg-being_ernest.txt 58333 2022-10-12 22:21:22.861303 +0800 CST m=+11.002276209}] finished on worker 58333
2022/10/12 22:21:13 [INFO]handleFinishedMapTask success: workerId: 58333, taskIdx: 0
2022/10/12 22:21:13 [INFO]Assign task &{Map-3 Map 3 ../pg-grimm.txt 0001-01-01 00:00:00 +0000 UTC} to worker 58333
2022/10/12 22:21:13 [INFO]Call AckAndQueryNewTaskResponse success! req: &{0 Map 58333}, resp: &{0xc000076360 8 10}
2022/10/12 22:21:13 [INFO]Worker[58335] writes intermediate files success, task: &{Map-2 Map 2 ../pg-frankenstein.txt 58335 2022-10-12 22:21:22.861595 +0800 CST}
2022/10/12 22:21:13 [INFO]Finished task: &{Map-2 Map 2 ../pg-frankenstein.txt 58335 2022-10-12 22:21:22.861595 +0800 CST} on worker: 58335
2022/10/12 22:21:13 [INFO]Mark task [&{Map-2 Map 2 ../pg-frankenstein.txt 58335 2022-10-12 22:21:22.861595 +0800 CST m=+11.002569001}] finished on worker 58335
2022/10/12 22:21:13 [INFO]handleFinishedMapTask success: workerId: 58335, taskIdx: 2
2022/10/12 22:21:13 [INFO]Assign task &{Map-4 Map 4 ../pg-huckleberry_finn.txt 0001-01-01 00:00:00 +0000 UTC} to worker 58335
2022/10/12 22:21:13 [INFO]Call AckAndQueryNewTaskResponse success! req: &{2 Map 58335}, resp: &{0xc0000ba7e0 8 10}
2022/10/12 22:21:13 [INFO]Worker[58334] writes intermediate files success, task: &{Map-1 Map 1 ../pg-dorian_gray.txt 58334 2022-10-12 22:21:22.861488 +0800 CST}
2022/10/12 22:21:13 [INFO]Finished task: &{Map-1 Map 1 ../pg-dorian_gray.txt 58334 2022-10-12 22:21:22.861488 +0800 CST} on worker: 58334
2022/10/12 22:21:13 [INFO]Mark task [&{Map-1 Map 1 ../pg-dorian_gray.txt 58334 2022-10-12 22:21:22.861488 +0800 CST m=+11.002462043}] finished on worker 58334
2022/10/12 22:21:13 [INFO]handleFinishedMapTask success: workerId: 58334, taskIdx: 1
2022/10/12 22:21:13 [INFO]Assign task &{Map-5 Map 5 ../pg-metamorphosis.txt 0001-01-01 00:00:00 +0000 UTC} to worker 58334
2022/10/12 22:21:13 [INFO]Call AckAndQueryNewTaskResponse success! req: &{1 Map 58334}, resp: &{0xc000098420 8 10}
2022/10/12 22:21:13 [INFO]Worker[58334] writes intermediate files success, task: &{Map-5 Map 5 ../pg-metamorphosis.txt 58334 2022-10-12 22:21:23.568509 +0800 CST}
2022/10/12 22:21:13 [INFO]Finished task: &{Map-5 Map 5 ../pg-metamorphosis.txt 58334 2022-10-12 22:21:23.568509 +0800 CST} on worker: 58334
......
2022/10/12 22:22:25 [INFO]Call AckAndQueryNewTaskResponse success! req: &{2 Reduce 58551}, resp: &{0xc000188240 0 0}
2022/10/12 22:22:25 [INFO]Received job finish signal from master, exit
2022/10/12 22:22:25 [INFO]Worker 58551 finished!
2022/10/12 22:22:26 [INFO]current task phase: Finished, res task count: 0
2022/10/12 22:22:26 [INFO]Worker 58818 started!
2022/10/12 22:22:26 [INFO]Worker 58817 started!
2022/10/12 22:22:26 [INFO]Worker 58820 started!
2022/10/12 22:22:26 [INFO]Call AckAndQueryNewTaskResponse success! req: &{0 58818}, resp: &{0xc00007a720 0 0}
2022/10/12 22:22:26 [INFO]Received job finish signal from master, exit
2022/10/12 22:22:26 [INFO]Worker 58818 finished!
2022/10/12 22:22:26 [INFO]Call AckAndQueryNewTaskResponse success! req: &{0 58817}, resp: &{0xc00013aae0 0 0}
2022/10/12 22:22:26 [INFO]Received job finish signal from master, exit
2022/10/12 22:22:26 [INFO]Worker 58817 finished!
从日志也可以看出,最终 Master 和 Worker 都成功的退出了!
<br/>
上面就是 Lab1 的基本实现了,在开发过程中的一个小技巧就是,大量打印日志,便于排查问题;
同时,在写代码之前,要提前规划好代码,组织好逻辑之后再动手,效率反而高很多!
<br/>
源代码根据 MIT 实验的要求,是一个Private的 repo 没有公开,需要源代码的可以联系我,也可以一起交流~
视频学习地址:
<br/>