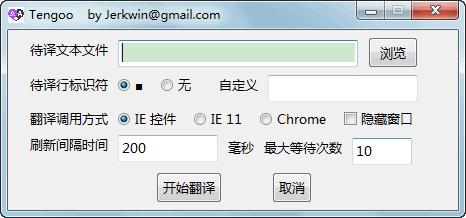
最近在翻译文档的时候整理了一下操作流程, 顺便完成了几个脚本以加快操作, 这里简单记录一下供参考.
计算机辅助翻译(CAT)的概念早就有了, 指的是翻译时借助计算机的记忆功能提供一些方便的操作, 如提供机器翻译, 词汇查询, 搜索以前的类似翻译等. 在我看来, CAT最主要的功能有两点, 提供机器翻译作为译文初稿, 存储译文作为将来翻译的模板. 这样你翻译得越多, 积累的译文库越大, 翻译起来就越方便.
目前可用的CAT软件也有不少, 但大多是商业软件, 又大又复杂. 我看了一圈后选择了免费的OmegaT. 它是java写的, 支持groovy和js脚本, 虽然看起来有些简陋, 但借助脚本插件, 基本能满足需要了.
Windows without JRE, 因为自带的java运行环境版本较低, 对中文输入法支持不佳./OmegaT安装路径/scripts.星际译王词典:英汉汉英专业词典_stardict-oxford-gb-2.4.2stardict-ProECCE-2.4.2.安装完成后, 新建一个项目, 将待译文档(.txt扩展名)放到/项目路径/source文件夹下. 加载文档后, 程序会自动将整篇文档拆分为片段(segment, 相当于英文的句子). 双击任一片段就可以输入译文了. 翻译完成可以生成译文, 默认放在/项目路径/target文件夹下.
/项目路径/tm文件夹下放置译文库, xml格式的, 基本就是一句原文一句译文的对应.
参考:
对专业文献来说, 机器翻译的效果还是不错的, 所以翻译科技文献时大多是借助机器翻译提供初稿, 然后在此基础之上进行修订. 这也是我很长时间以来的作法. 目前机器翻译效果较好的两家就是腾讯翻译君和谷歌翻译了, 但调用API都不是免费的, 在线翻译虽然免费, 但有限制且无法自动, 所以我希望能有办法自动获取在线翻译的功能.
网上看了一圈, 大部分实现方法都是基于python的, 或是使用爬虫技术, 或是使用模拟浏览器技术. 前者简单, 但无法直接调用翻译君, 因为它没有提供固定的翻译接口. 后者理论上可以模拟任意操作, 但以前常用的PhantomJS已经终止开发了, 目前可以使用谷歌或火狐浏览器的无头模式来代替. 虽然python的Selenium可以实现需要的功能, 但需要安装的模块又多又大, 实现代码看起来也不舒服. 我本来就不是很喜欢python, 思量了一下还是放弃了python实现. 想着实在不行还是用我熟悉的autohotkey来模拟手动操作算了, 虽然笨点, 但简单直接, 比安装那一堆的python模块更省心. 于是搜索了一下基于autohotkey的实现方法. 没想到autohotkey中已经有操控浏览器的方法了, 用的是IE 11的websocket功能. 升级自己win7系统的IE到IE11, 测试下代码, 成功了. 嗯, 很好. 继续搜索下去, 又发现有人使用autohotkey调用谷歌浏览器的无头模式, 同样可以实现模拟浏览器操作. 嗯, 也不错. 综合看来, 这两种方法应该是最简单的实现了. 那就动手吧. 分析了下翻译君和谷哥的网页逻辑结构, 写了点测试代码, 调教成功! 继续完善了下代码, 一个自动读取待译文档输出机器译文以及OmegaT译文库的程序就出现了. 这个程序支持腾讯和谷歌, 所以我就称其为Tengoo了.
随便拿篇待译文本测试下吧
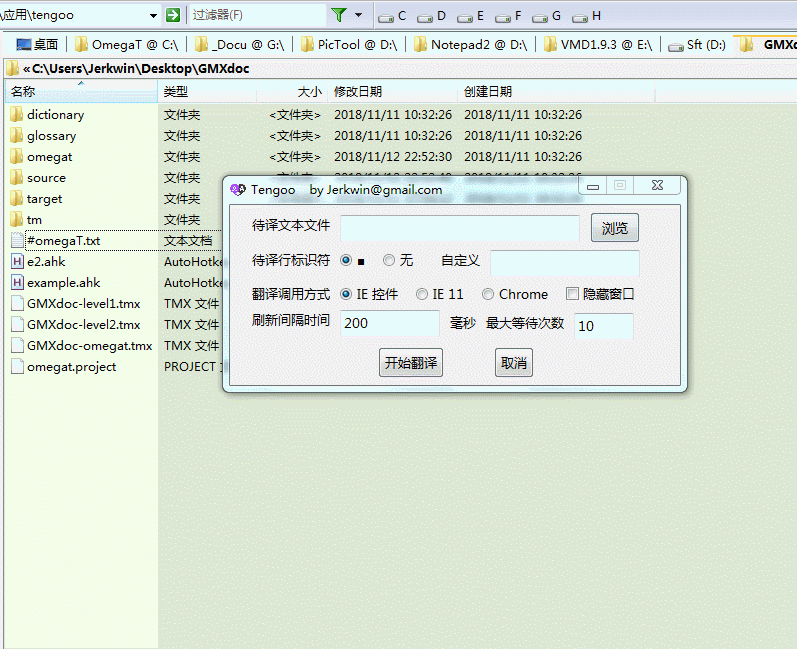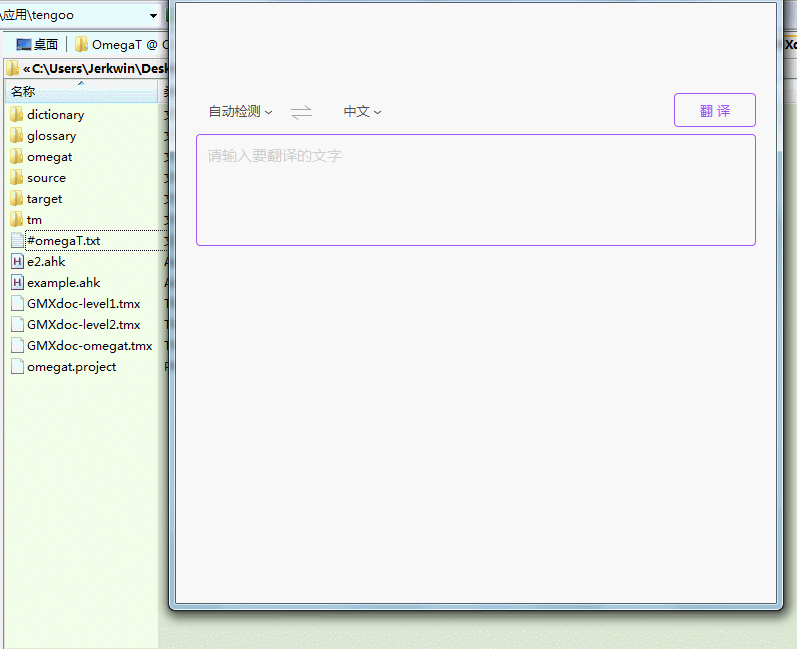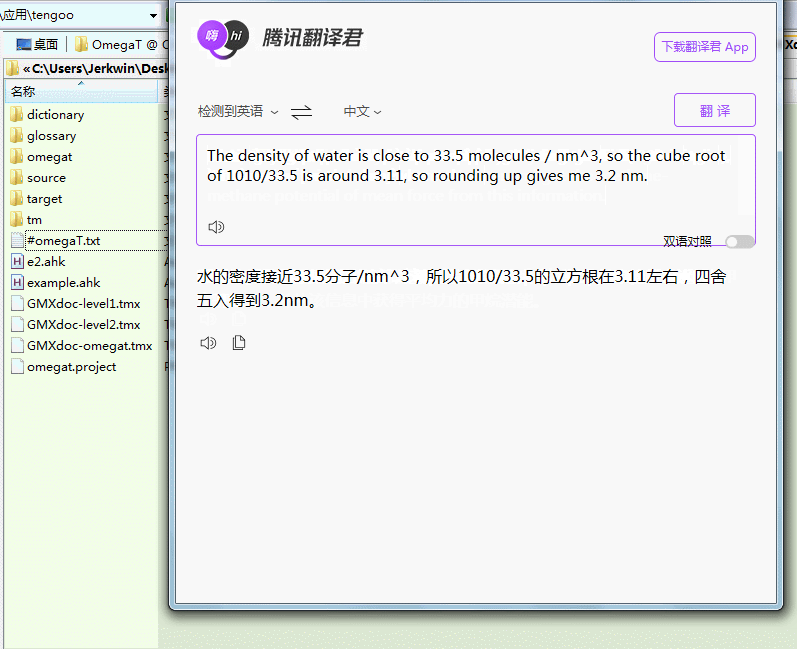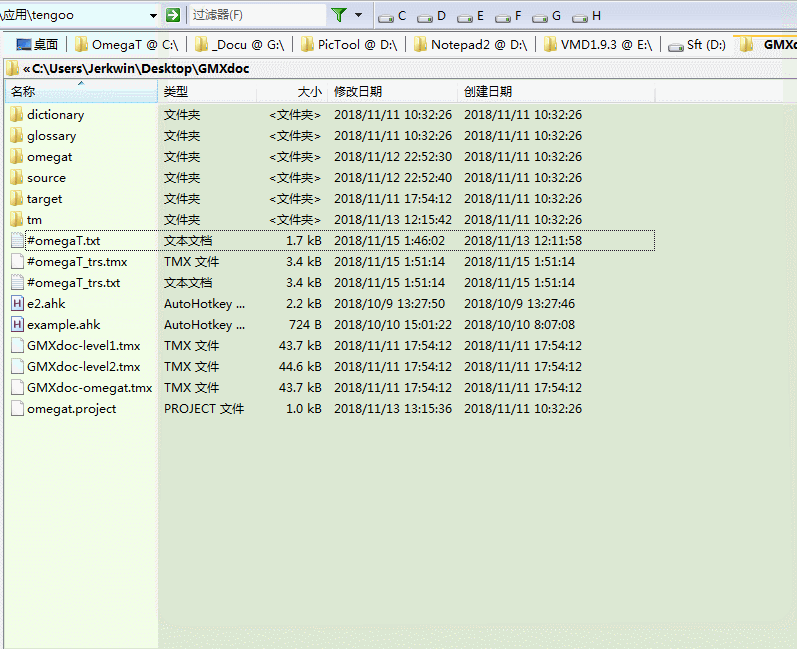
嗯. 效果不错. 翻译君和谷哥水平相当, 语言各有特色, 但我这边使用的时候翻译君响应有点慢.
将得到的文件放到OmegaT的译文库中, 就可以直接进行修订了.
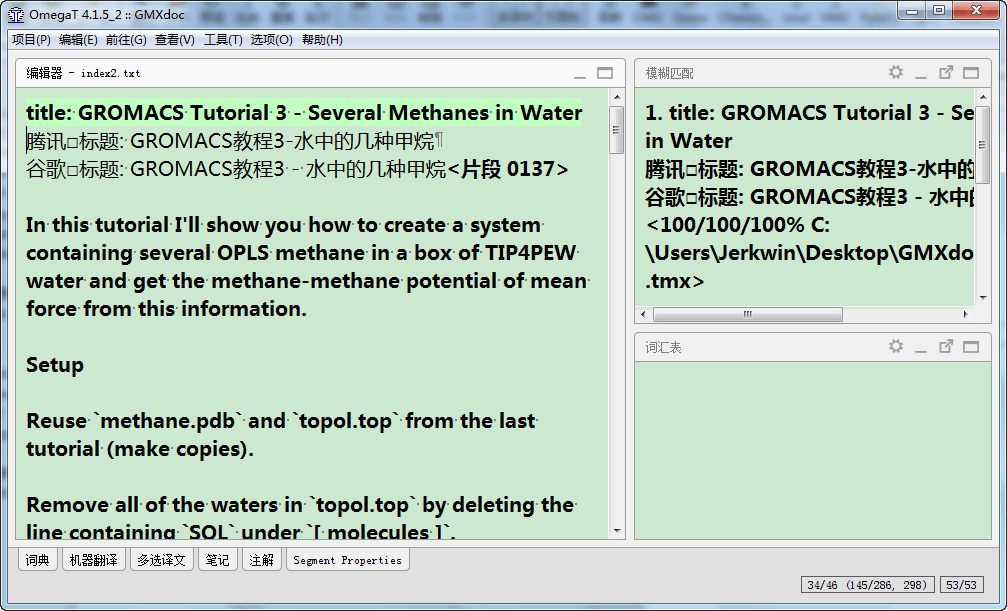
修订好后, 可以直接生成译文发布, 然后再输出为译文库备用. 这样一篇文档就翻译完成了.
参考: