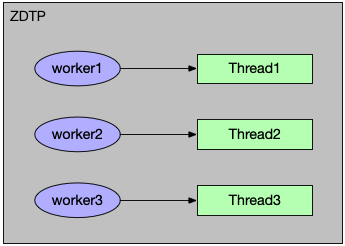
在 ZDTP 中,数据同步的动作可抽象成一个执行单元(以下称为 worker),类似于线程执行单元 Runnable ,Runnable 放入一个队列中等待线程的调度执行,执行完 Runnable 即完成了它的使命。当用户在 ZDTP 控制台中创建同步任务并启动任务时,会根据同步任务的配置,产生若干个用于该任务的 worker,假设这些 worker 都在本地执行,可以将其包装成一个 Runnable,然后创建一个线程执行,如下图表示:
但是在单机模式下,就会遇到性能瓶颈,此时就需要分布式调度,将 worker 调度到其他机器执行:
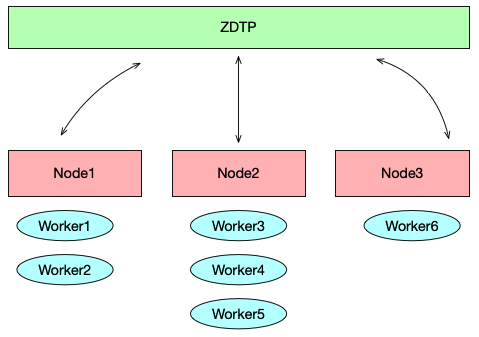
问题是我们如何将 worker 更好地调度到其它机器中执行呢?
1、基于虚拟机部署 Worker
Worker 在提前创建好的虚拟机中运行, 任务启动时需要根据当前 Worker 负载情况进行选择空闲的 Worker,相当于 Worker 是以 Agent 的形式运行,如下图表示:
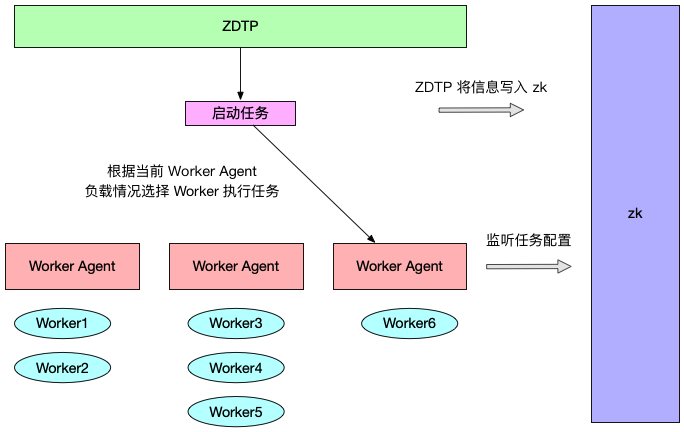
伴随而来的缺点主要有以下几点:
2、基于 K8s 部署 Worker
将 Worker 打包成 Docker 镜像,使用 K8s 对 worker 容器进行调度作业,并且一个 Worker 只运行一个任务,如下图表示:
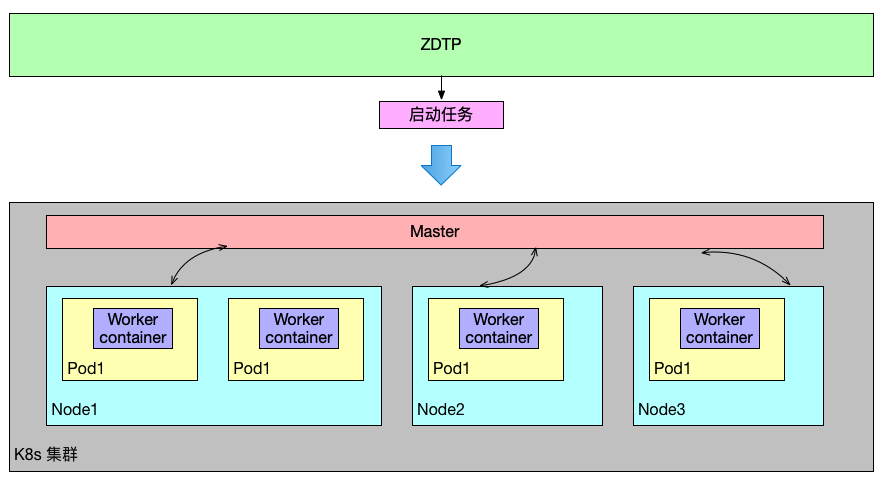
使用 K8s 的优点如下:
K8s 集群的调度对象是 Pod,调度方式有多种,这里主要介绍以下几种方式:
1、Deployment(全自动调度)
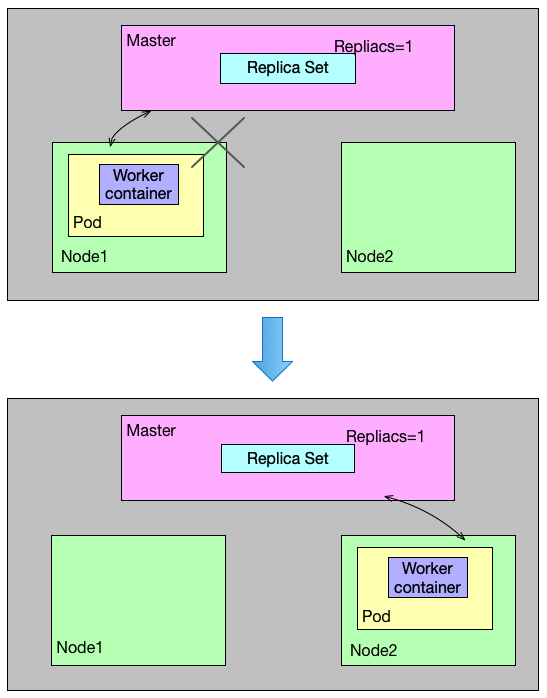
在讲 Deployment 前,先来说下 Replica Set,它是 K8s 一个非常重要的概念,它是在 Pod 这个抽象上更为上层的一个抽象,一般大家用 Deployment 这个抽象来做应用的真正的管理,而 Pod 是组成 Deployment 最小的单元。它可以定义某种 Pod(比如包装了 ZDTP Worker 容器的 Pod)在任意时刻都保持符合 Replica Set 设定的预期值, 比如 Replica Set 可预期设定 Pod 副本数,当 k8s 集群定期巡检发现某种 Pod 的副本数少于 Replica Set 设定的预期值,它就会按照 Replica Set 设定的 Pod 模版创建 Pod 实例,使得 Pod 的数量维持在预期值,也是通过 Replica Set 的特性,实现了集群的高可用性,同时减少了运维成本。
Deployment 内部使用了 Replica Set 来实现,他们之间高度相似,也可以将 Deployment 看作是 Replica Set 的升级版本。
2、Job(批处理调度)
我们可以通过 k8s Job 资源对象定义并启动一个批处理任务,并行或者串行处理一批工作项(Work item),处理完成后任务就结束。
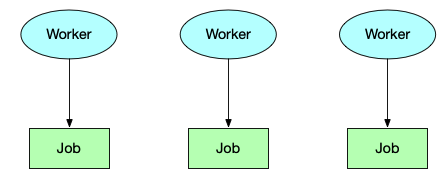
1)Job Template Expansion 模式
根据 ZDTP Worker 运行方式,我们可以使用一个 Job 对像对应一个 Worker,有多少个 worker 就创建多少个 Job,除非 Pod 异常,才会重启该 Pod,正常执行完后 Job 就退出,如下图表示:
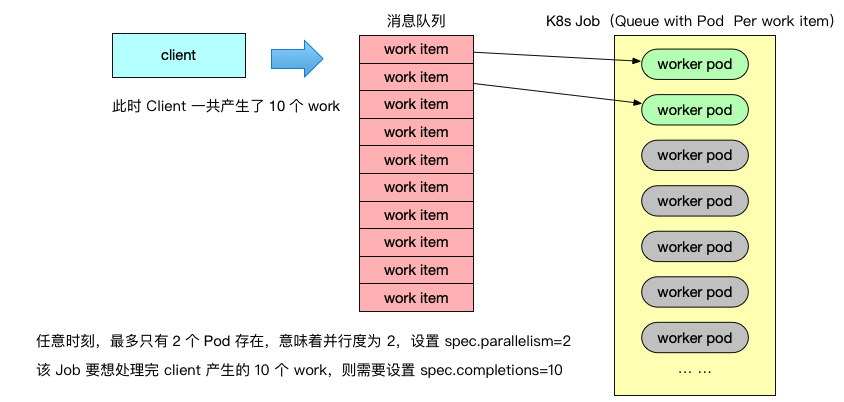
2)Queue with Pod Per Work Item 模式
这种模式将客户端生成的 worker 存放在一个队列中,然后只会创建一个 job 去消费队列中的 worker item,通过设置 parallelism 参数可以同时启动多少个 worker Pod 同时处理 worker,值得一体的是,这种模式下的 Worker 处理程序逻辑只会从队列拉取 worker 处理,处理完就立即退出,completions 参数用于控制正常退出的 Pod 数量,当退出的 Pod 数量达到了 completions 后,Job 结束,即 completions 参数可以控制 Job 的处理 Worker 的数量。如下图所示:
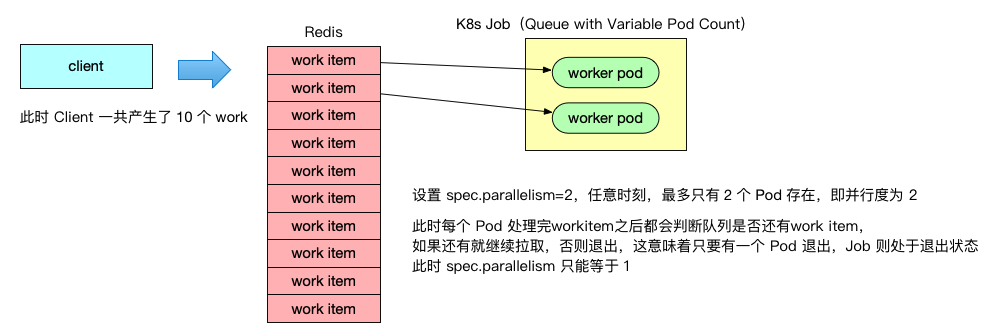
3)Queue with Variable Pod Count 模式
这种调度模式看起来跟 Queue with Pod Per Work Item 模式差不多,其实不然,Queue with Variable Pod Count 模式的 Job 只要有一个 Pod 正常退出,即说明 Job 已经处理完数据,处于终止状态了,因为它的每个 Pod 都有查询队列是否还有 worker 的逻辑,一旦发现队列中没有了 worker,Pod 正常退出,因此 Queue with Variable Pod Count 模式 completions 参数只能设置 1, parallelism 参数可以同时启动多少个 worker Pod 同时处理 worker。
这种模式也要求队列能够让 Pod 感知是否还存在 worker,像 RocketMQ/Kafka 之类的消息中间件并不能做到,只会让客户端一直等待,因此这种模式不能选用 RocketMQ/Kafka,可以选择数据库或者 Redis 来实现。如下图所示:
当然如果后面还有定时执行 Worker 的需求,使用 K8s 的 cronjob(定时任务调度)是一个非常好的选择。
3、Pod(默认调度)
直接通过 kind=pod 的方式启动容器,这种方式不能设置容器的运行实例数,即 replicas = 1,通常生产应用集群都不会通过这个方式启动容器,因为这种方式启动容器不具备 Pod 自动扩缩容的特性。
值得一提的是,即使你的 Pod 副本只有 1 个,官方也推荐使用 Replica Set 的方式进行部署。
Pod 的重启策略包括 Always、onFailure、Never:
Deployment/Replica Set 必须设置为 Always(因为它们都需要保持 Pod 期待的副本数),而 Job 只能设置为 onFailure 和 Never,以确保容器执行完成后不再重启,直接 Pod 启动容器以上三个重启策略都可以设置。
这里需要说明一点,如果使用 Job,情况可能稍微复杂些:
1)Pod 重启策略 RestartPolicy=Never
假设 Job 调度过程中 Pod 发生非正常退出,尽管此时容器不再重启,由于 Job 需要至少一个 Pod 执行完成(即 completions 最少等于 1),Job 才算完成。因此,虽然非正常退出的 Pod 不再重启,但 Job 会尝试重新启动一个 Pod 执行,直到 Pod 正常完成的数量为 completions。
$ kubectl get pod --namespace zdtp-namespace
NAME READY STATUS RESTARTS AGE
zdtp-worker-hc6ld 0/1 ContainerCannotRun 0 64s
zdtp-worker-hfblk 0/1 ContainerCannotRun 0 60s
zdtp-worker-t9f6v 0/1 ContainerCreating 0 11s
zdtp-worker-v2g7s 0/1 ContainerCannotRun 0 31s
2)Pod 重启策略 RestartPolicy=onFailure
当 RestartPolicy=onFailure,Pod 发生非正常退出时,Pod 会尝试重启,直到该 Pod 正常执行完成,此时 Job 就不会重新启动一个 Pod 执行了,如下:
$ kubectl get pod --namespace zdtp-namespace
NAME READY STATUS RESTARTS AGE
zdtp-worker-5tbxw 0/1 CrashLoopBackOff 5 67s
以上内容把 K8s 的调度方案与 Pod 的重启策略都研究了一番后,接下来就需要针对项目的调度需求选择合适的调度方式。
1、增量同步 Worker
增量同步 Worker 会一直同步下去,中途不停止,这意味着 Pod 的重启策略必须为 RestartPolicy=Always,那么这种方式只能选择 Deployment 调度或者直接创建 Pod 部署,但建议使用 Deployment,官方已经说明了即使 Pod 副本为 1,依然建议使用 Deployment 进行部署。
2、 全量同步 Worker
全量同步 Worker 在数据同步完就退出,看起来 Job 调度或者直接创建 Pod 部署都可以满足,但现阶段由于全量同步暂时没有记录同步进度,因此要求中途发生任何错误容器退出后都不能自动重启,目前的做法是当 Worker 执行过程中发生非正常退出时,需要用户自行删除已同步的资源,再手动启动 Worker 再次进行全量同步。
因此,Job 目前还还不适合调度 Worker Pod,全量同步 Worker 现阶段只适合直接使用 Pod 进行部署,且需要设置 Pod 重启策略 RestartPolicy=Never。