最近你们有没有发现,GitHub 明显变慢了,如果没有 fanqiang,拉取代码的速度简直惨不忍睹,如果拉取的量少还可以勉强拉下来,但是遇到数据量大的时候,2 KiB/s 的速度你能忍?拉到中途超时就让你痛不欲生。
最近我就遇到这个问题,seata 社区的 seata.github.io 仓库有阵子突然增加了好多数据,我发现我已经拉不下来了,这时可以利用 Gitee 作为中间代理,下面详细说说具体操作过程。
在 GitHub 中,一共有两个仓库:
以下内容将用 seat、objcoding 表示这两个仓库。
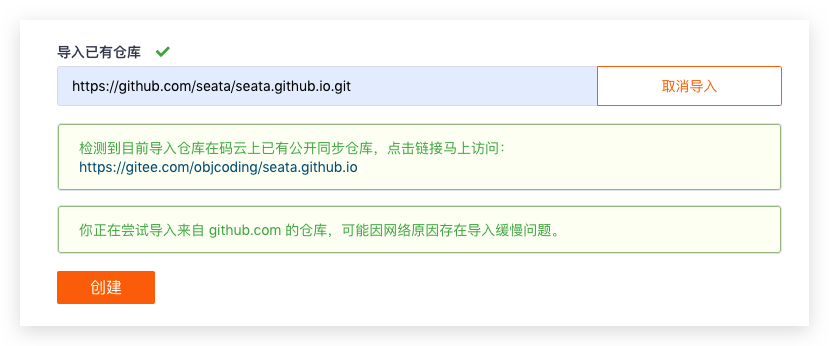
Gitee 创建仓库时,可以导入已有仓库时选择从 GitHub 仓库中导入,这时我们填写 Seata 主仓库地址,意味着 Gitee 仓库将可以从 Seata 主仓库中同步代码 :
将 Gitee 仓库 clone 到本地(此时仓库名称默认 origin):
git clone https://gitee.com/objcoding/seata.github.io.git
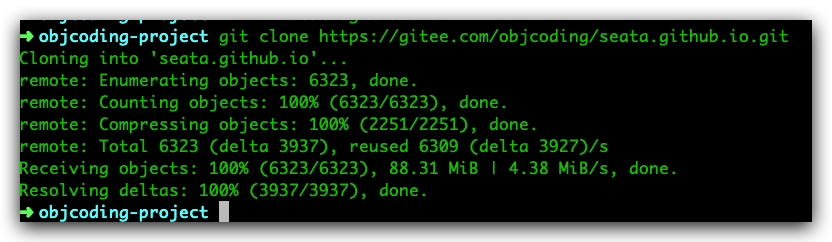
这个速度快到我想哭,你能想象GitHub 2 KiB/s 的悲惨人生么。
添加 objcoding 远程仓库:
git remote add objcoding https://github.com/objcoding/seata.github.io.git
fetch objcoding 远程仓库内容到本地:
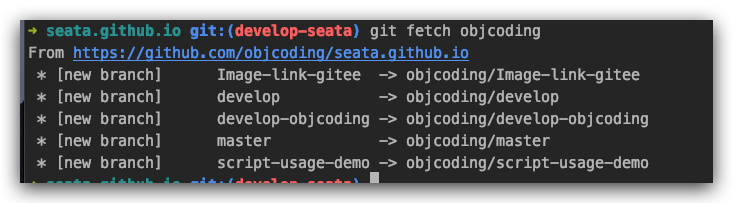
速度很快,因为远程仓库中的绝大部份代码,已经从 gitee 拉取下来了。
添加 seata 远程仓库:
git remote add seata https://github.com/seata/seata.github.io.git
同理,fetch seata 远程仓库内容到本地。
这时候,我本地仓库就拥有了三个远程仓库了,分别是:
为什么这里还需要添加 seata 仓库呢?这是因为一般来说,seata 主仓库增加的代码数据量都很少,即使是 2Kib/s 的速度,也是可以拉取下来的,所以平时可以直接从 seata 主仓库中拉取最新代码就可以了,但是像 seata.github.io 仓库,突然某个大佬上传了几十兆数据,那么此时我就可以利用 Gitee 仓库去同步这些代码,具体操作如下:

接下来 fetch gitee 对应的分支,就可以将这些数据拉取下来了。
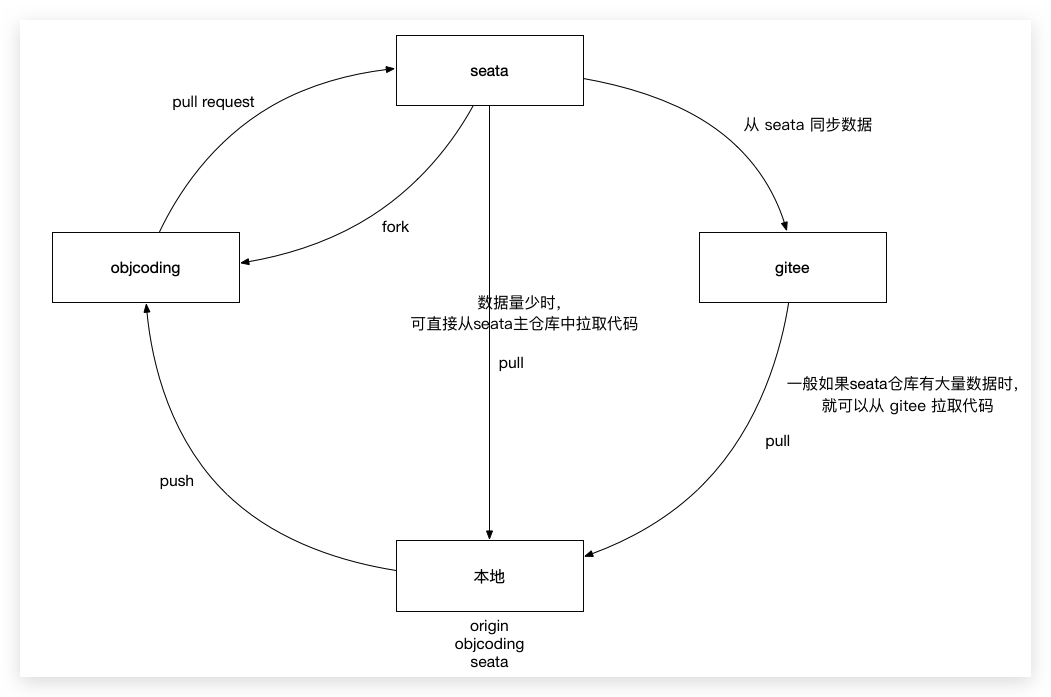
以上是整个同步过程分析。