
V0 版本的消息格式主要存在于 Kafka 0.10.0.0 之前的版本,也是 Kafka 最早的消息版本,Kafka 的消息在 Kafka 的设计中被叫做 “Record”,我们也可以定位到 org.apache.kafka.common.record.Record 类,该类即是 Kafka 消息的类,我们可以从类中看到消息的一些字段长度的定义,其中还包括了 ByteBuffer 字段,从而得知 Kafka 使用 ByteBuffer 来保存消息,而不是使用 Java 类,这样做的好处是可以节省很多空间,ByteBuffer 是一个紧凑的二进制字节的结构,而 Java 类由于 Java 内存模型机制的原因会产生字段填充问题,下面我们来看下 Kafka 是怎么将消息写入 ByteBuffer:
org.apache.kafka.common.record.Record#write(org.apache.kafka.common.record.Compressor, long, byte, byte[], byte[], int, int)
public static void write(Compressor compressor, long crc, byte attributes, byte[] key, byte[] value, int valueOffset, int valueSize) {
// write crc
compressor.putInt((int) (crc & 0xffffffffL));
// write magic value
compressor.putByte(CURRENT_MAGIC_VALUE);
// write attributes
compressor.putByte(attributes);
// write the key
if (key == null) {
compressor.putInt(-1);
} else {
compressor.putInt(key.length);
compressor.put(key, 0, key.length);
}
// write the value
if (value == null) {
compressor.putInt(-1);
} else {
int size = valueSize >= 0 ? valueSize : (value.length - valueOffset);
compressor.putInt(size);
compressor.put(value, valueOffset, size);
}
}
从以上代码逻辑可以看出,我们可以得知 Kafka 的消息格式包括了一下字段:
再结合 org.apache.kafka.common.record.Record 类中常量定义的字段大小,我用以下图表示 V0 版本消息格式的样子:
从上图可以看出,V0 版本的消息最小为 14 字节,小于 14 字节的消息会被 Kafka 视为非法消息。
下面我来举个例子来计算一条消息的具体大小,某条消息的各个字段值依次如下:
该条消息长度为:
4 + 1 + 1 + 4 + 3 + 4 + 5 = 22 字节。
随着 Kafka 的不断迭代演进,用户发现 V0 版本的消息格式由于没有保存时间信息导致 Kafka 无法依据消息的具体时间作进一步判断,比如定期删除过期日志 Kafka 只能依靠日志文件的最近修改时间,这个时间很容易被外界干扰,比如在 linux 中执行了 touch 命令就会更改这个时间。
V1 版本的消息格式在 V0 版本的基础上增加了时间戳字段,切换到 Kafka 0.10.0 分支,再次观察 Kafka 是如何将消息写入 ByteBuffer 的:
org.apache.kafka.common.record.Record#write(org.apache.kafka.common.record.Compressor, long, byte, long, byte[], byte[], int, int)
public static void write(Compressor compressor, long crc, byte attributes, long timestamp, byte[] key, byte[] value, int valueOffset, int valueSize) {
// write crc
compressor.putInt((int) (crc & 0xffffffffL));
// write magic value
compressor.putByte(CURRENT_MAGIC_VALUE);
// write attributes
compressor.putByte(attributes);
// write timestamp
compressor.putLong(timestamp);
// write the key
if (key == null) {
compressor.putInt(-1);
} else {
compressor.putInt(key.length);
compressor.put(key, 0, key.length);
}
// write the value
if (value == null) {
compressor.putInt(-1);
} else {
int size = valueSize >= 0 ? valueSize : (value.length - valueOffset);
compressor.putInt(size);
compressor.put(value, valueOffset, size);
}
}
我用以下图表示 V1 版本消息格式的样子:

从上图可以看出,V1 版本的消息最小为 22 字节,小于 22 字节的消息会被 Kafka 视为非法消息。
总的来说比 V0 版本的消息大了 8 字节,如果还是按照 V0 那条消息计算,则在 V1 版本中它的总字节数为:
22 + 8 = 30 字节。
还需要注意的另一点差别就是 V1 版本中的 attribute 字段的第 4 位用于保存时间戳类型,当前时间戳类型有:
V0、V1 版本的消息集合的设计没有任何区别,被称作“日志项”,在源码中,我们找到了 LogEntry 类:
org.apache.kafka.common.record.LogEntry
public final class LogEntry {
private final long offset;
private final Record record;
// ...
public int size() {
return record.size() + Records.LOG_OVERHEAD;
}
}
可以看出,V0、V1 版本的消息集合设计的非常简单,offset 字段记录了消息在 Kafka 分区日志中的 offset,record 即消息本身,还有一个size()方法 ,该方法记录的是消息集合的长度,我们再看下 LOG_OVERHEAD 字段:
org.apache.kafka.common.record.Records
public interface Records extends Iterable<LogEntry> {
int SIZE_LENGTH = 4;
int OFFSET_LENGTH = 8;
int LOG_OVERHEAD = SIZE_LENGTH + OFFSET_LENGTH;
}
从以上源码可以看出,消息集合中 offset 占用了 8 字节,消息集合大小字段占用了 4 字节。
那么我们就可以画出 V0、V1 消息集合格式的样子:
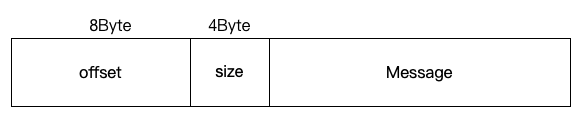
以上,message 字段也被 Kafka 称作浅层消息(shallow message),如果消息未进行压缩,那么该字段保存的消息即是它本身,如果消息进行压缩,Kafka 会将多条消息压缩在一起放入到该字段中。
值得注意的一点是:如果消息未被压缩,那么 offset 的值就是消息本身在分区日志中的 offset,如果多条消息被压缩放入到该字段中,则 offset 表示这批消息中最后一条消息在分区日志中的 offset。从这里我们也可以看出,在 V0、V1 版本的日志项中搜索位移是一件很困难的事情,我们需要解压并进行计算,代价非常高。
现在如果我们使用 V1 版本举例的那条消息放入消息集合中(未使用压缩),那么消息集合的大小为:8 + 4 + 30 = 42 字节。
经过上面我们分析并画出的 V0、V1 版本消息格式,我们会发现它们在设计上的一些缺陷,比如:
针对 V0、V1 版本消息格式的缺陷,Kafka 在 0.11.0.0 版本对消息格式进行了大幅度重构,使用可变长度解决了空间使用率低的问题,增加了消息总长度字段,使用增量的形式保存时间戳和位移,并且把一些字段统一抽取到消息集合中,下面我们来看下 V2 版本的消息格式具体有哪些参数:
org.apache.kafka.common.record.DefaultRecord
再看下 Kafka 是如何将消息构建成 Buffer 的:
org.apache.kafka.common.record.DefaultRecord#writeTo
public static int writeTo(DataOutputStream out,
int offsetDelta,
long timestampDelta,
ByteBuffer key,
ByteBuffer value,
Header[] headers) throws IOException {
// 消息总数
int sizeInBytes = sizeOfBodyInBytes(offsetDelta, timestampDelta, key, value, headers);
ByteUtils.writeVarint(sizeInBytes, out);
// 属性
byte attributes = 0; // there are no used record attributes at the moment
out.write(attributes);
// 时间增量
ByteUtils.writeVarlong(timestampDelta, out);
// 位移增量
ByteUtils.writeVarint(offsetDelta, out);
// key
if (key == null) {
ByteUtils.writeVarint(-1, out);
} else {
int keySize = key.remaining();
// key size
ByteUtils.writeVarint(keySize, out);
// key
Utils.writeTo(out, key, keySize);
}
// Value
if (value == null) {
ByteUtils.writeVarint(-1, out);
} else {
int valueSize = value.remaining();
// value size
ByteUtils.writeVarint(valueSize, out);
// value
Utils.writeTo(out, value, valueSize);
}
// header
ByteUtils.writeVarint(headers.length, out);
for (Header header : headers) {
// header key
String headerKey = header.key();
byte[] utf8Bytes = Utils.utf8(headerKey);
// header key 长度
ByteUtils.writeVarint(utf8Bytes.length, out);
// header key 值
out.write(utf8Bytes);
// header value
byte[] headerValue = header.value();
if (headerValue == null) {
ByteUtils.writeVarint(-1, out);
} else {
// header value 长度
ByteUtils.writeVarint(headerValue.length, out);
// header value 值
out.write(headerValue);
}
}
return ByteUtils.sizeOfVarint(sizeInBytes) + sizeInBytes;
}
根据以上代码逻辑,我用以下图表示 V2 版本消息格式的样子:

Kafka 可变长度的具体做法借鉴了 Google ProtoBuffer 中的 Zig-zag 编码方式,这个我也没研究过,感兴趣的小伙伴可以研究下。但根据 Kafka 官方的描述,使用 Zig-zag 编码之后,例如一般的 key 只需要 1 字节保存即可,相比 V0、V1 版本需要 4 字节保存节省了 3 字节。
那么我们来总结一下 V2 版本具有哪些变化:
还是以 V0 举例的消息为例,假设该条消息改成 V2 版本,那么该条消息的大小为:
1(sizeInBytes) + 1(attributes) + 1(timestamp) + 1(offset) + 1(key length) + 3(key) + 1(value length) + 5(value) + 1(headers length) = 15 字节。
可以看出,V2 版本的消息占用的空间会比 V0、V1 版本的消息要小很多。
V2 版本的消息集合相比 V0、V1 版本要复杂得多,在 V2 版本的消息集合被称作“消息批次”,根据消息批次类中的注释:
org.apache.kafka.common.record.DefaultRecordBatch
RecordBatch =>
BaseOffset => Int64
Length => Int32
PartitionLeaderEpoch => Int32
Magic => Int8
CRC => Uint32
Attributes => Int16
LastOffsetDelta => Int32 // also serves as LastSequenceDelta
FirstTimestamp => Int64
MaxTimestamp => Int64
ProducerId => Int64
ProducerEpoch => Int16
BaseSequence => Int32
Records => [Record]
我们可以清除地看到 V2 版本中消息格式的具体字段与大小,我用以下图表示 V2 版本消息批次的样子:

从以上图可看出,V2 版本的消息批次,相比 V0、V1 版本主要有以下变动:
还是以之前举例的消息,将它放入 V2 版本消息批次的大小:61 + 15 = 76 字节,这比放入 V0、V1 版本的日志项 42 字节要大很多,看起来貌似比之前还要占用空间,其实这只是我们在举例时,只有一条消息,由于 V2 版本的消息格式要比 V0、V1 版本的消息格式要小,而 V2 版本的消息批次无论是否使用压缩,都可以放入多条消息,因此在批量发送消息时,V2 是要比 V0、V1 节约空间的。
从以上文章内容得出,V2 版本主要是通过可变长度提高了消息格式的空间使用率,并将某些字段移到消息批次中,同时消息批次可容纳多条消息,从而在批量发送消息时,大幅度地节省了磁盘空间。