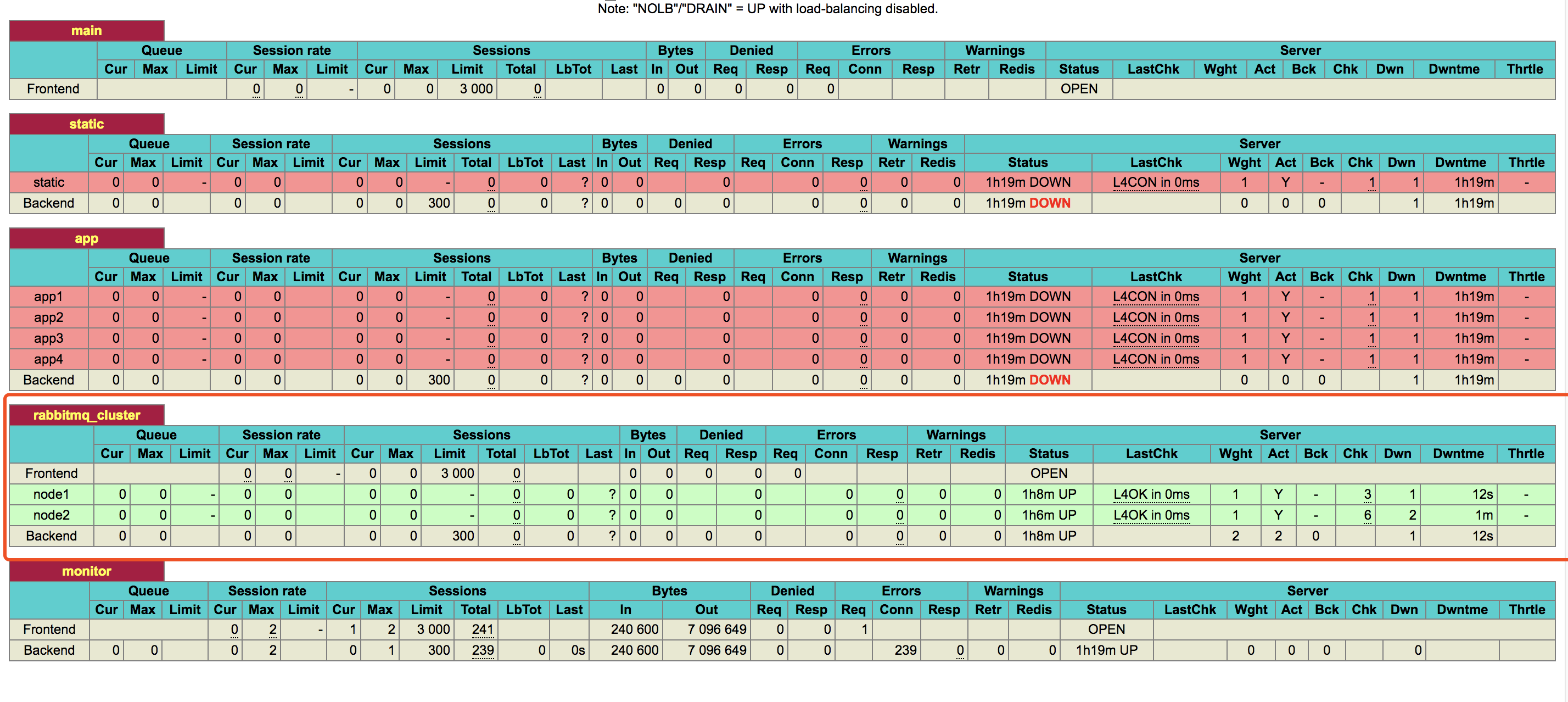
RabbitMQ 内部有各种基础构件,包括队列、交换器、绑定、虚拟主机等,他们组成了 AMQP 协议消息通信的基础,而这些构件以元数据的形式存在,它始终记录在 RabbitMQ 内部,它们分别是:
在单一节点上,RabbitMQ 会将上述元数据存储到内存上,如果是磁盘节点(下面会讲),还会存储到磁盘上。
这里有个问题需要思考,RabbitMQ 默认会将消息冗余到所有节点上吗?这样听起来正符合高可用的特性,只要集群上还有一个节点存活,那么就可以继续进行消息通信,但这也随之为 RabbitMQ 带来了致命的缺点:
解决这个问题就是通过集群中唯一节点来负责任何特定队列,只有该节点才会受队列大小的影响,其它节点如果接收到该队列消息,那么就要根据元数据信息,传递给队列所有者节点(也就是说其它节点上只存储了特定队列所有者节点的指针)。这样一来,就可以通过在集群内增加节点,存储更多的队列数据。
交换器其实是我们想象出来的,它本质是一张查询表,里面包括了交换器名称和一个队列的绑定列表,当你将消息发布到交换器中,实际上是你所在的信道将消息上的路由键与交换器的绑定列表进行匹配,然后将消息路由出去。有了这个机制,那么在所有节点上传递交换器消息将简单很多,而 RabbitMQ 所做的事情就是把交换器拷贝到所有节点上,因此每个节点上的每条信道都可以访问完整的交换器了。
关于上面队列所说的问题与解决办法,又有了一个伴随而来的问题出现:如果特定队列的所有者节点发生了故障,那么该节点上的队列和关联的绑定都会消失吗?
接下来说说内存节点与磁盘节点在集群中的作用,在集群中的每个节点,要么是内存节点,要么是磁盘节点,如果是内存节点,会将所有的元数据信息仅存储到内存中,而磁盘节点则不仅会将所有元数据存储到内存上, 还会将其持久化到磁盘。
在单节点 RabbitMQ 上,仅允许该节点是磁盘节点,这样确保了节点发生故障或重启节点之后,所有关于系统的配置与元数据信息都会重磁盘上恢复;而在 RabbitMQ 集群上,允许节点上至少有一个磁盘节点,在内存节点上,意味着队列和交换器声明之类的操作会更加快速。原因是这些操作会将其元数据同步到所有节点上,对于内存节点,将需要同步的元数据写进内存就行了,但对于磁盘节点,意味着还需要及其消耗性能的磁盘写入操作。
RabbitMQ 集群只要求至少有一个磁盘节点,这是有道理的,当其它内存节点发生故障或离开集群,只需要通知至少一个磁盘节点进行元数据的更新,如果是碰巧唯一的磁盘节点也发生故障了,集群可以继续路由消息,但是不可以做以下操作了:
这是因为上述操作都需要持久化到磁盘节点上,以便内存节点恢复故障可以从磁盘节点上恢复元数据,解决办法是在集群添加 2 台以上的磁盘节点,这样其中一台发生故障了,集群仍然可以保持运行,且能够在任何时候保存元数据变更。
由于 RabbitMQ 集群连接是通过主机名来连接服务的,必须保证各个主机名之间可以 ping 通,所以需要做以下操作:
修改hostname:
$ hostname node1 # 修改节点1的主机名
$ hostname node2 # 修改节点2的主机名
编辑/etc/hosts文件,添加到在三台机器的/etc/hosts中以下内容:
$ sudo vim /etc/hosts
193.xxx.61.78 node1
111.xxx.254.127 node2
这里将 node1 的该文件复制到 node2,由于这个文件权限是 400 为方便传输,先修改权限,非必须操作,所以需要先修改 node2 中的该文件权限为 777
$ chmod 777 /var/lib/rabbitmq/.erlang.cookie
用 scp 拷贝到节点 2
$ scp /var/lib/rabbitmq/.erlang.cookie node2:/var/lib/rabbitmq/
将权限改回来
$ chmod 400 /var/lib/rabbitmq/.erlang.cookie
在节点 2 执行如下命令:
$ rabbitmqctl stop_app # 停止rabbitmq服务
$ rabbitmqctl reset # 清空节点状态
$ rabbitmqctl join_cluster rabbit@node1 # node2和node1构成集群,node2必须能通过node1的主机名ping通
$ rabbitmqctl start_app # 开启rabbitmq服务
在任意一台机上面查看集群状态:
$ rabbitmqctl cluster_status
Cluster status of node rabbit@node1 ...
[{nodes,[{disc,[rabbit@node1,rabbit@node2]}]},
{running_nodes,[rabbit@node2,rabbit@node1]},
{cluster_name,<<"rabbit@node1">>},
{partitions,[]}]
...done.
第一行是集群中的节点成员,disc 表示这些都是磁盘节点,第二行是正在运行的节点成员。
登陆管理后台查看节点状态:
cluster 搭建起来后若在 web 管理工具中 rabbitmq_management 的 Overview 的 Nodes 部分看到 “Node statistics not available” 的信息,说明在该节点上 web 管理插件还未启用。 执行如下命令:
$ rabbitmq-plugins enable rabbitmq_management
重启 RabbitMQ:
$ rabbitmqctl stop
$ rabbitmq-server -detached
如果节点需要设置成内存节点,则加入集群的命令如下:
$ rabbitmqctl join_cluster --ram rabbit@node1
其中–ram指的是作为内存节点,如果不加,那就默认为内存节点。
如果节点在集群中已经是磁盘节点了,通过以下命令可以将节点改成内存节点:
$ rabbitmqctl stop_app # 停止rabbitmq服务
$ rabbitmqctl change_cluster_node_type ram # 更改节点为内存节点
$ rabbitmqctl start_app # 开启rabbitmq服务
现在再查看集群状态:
$ rabbitmqctl cluster_status
Cluster status of node rabbit@node1 ...
[{nodes,[{disc,[rabbit@node1]},{ram,[rabbit@node2]}]},
{running_nodes,[rabbit@node2,rabbit@node1]},
{cluster_name,<<"rabbit@node1">>},
{partitions,[]}]
...done.
可以看到,节点 2 已经成为内存节点了。
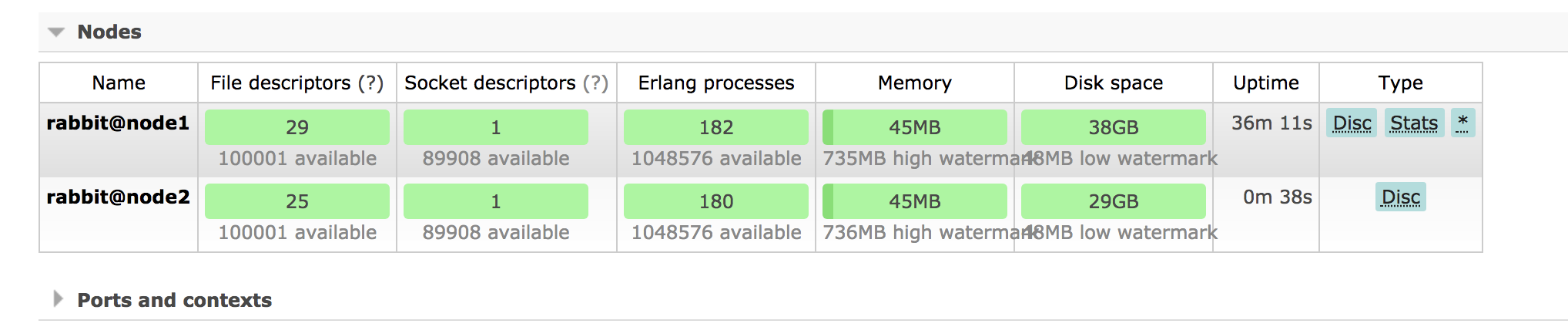
当节点发生故障时,尽管所有元数据信息都可以从磁盘节点上将元数据拷贝到本节点上,但是队列的消息内容就不行了,这样就会导致消息的丢失,那是因为在默认情况下,队列只会保存在其中一个节点上,我们在将集群队列时也说过。
聪明的 RabbitMQ 早就意识到这个问题了,在 2.6以后的版本中增加了,队列冗余选项:镜像队列。镜像队列的主队列(master)依然是仅存在于一个节点上,其余从主队列拷贝的队列叫从队列(slave)。如果主队列没有发生故障,那么其工作流程依然跟普通队列一样,生产者和消费者不会感知其变化,当发布消息时,依然是路由到主队列中,而主队列通过类似广播的机制,将消息扩散同步至其余从队列中,这就有点像 fanout 交换器一样。而消费者依然是从主队列中读取消息。
一旦主队列发生故障,集群就会从最老的一个从队列选举为新的主队列,这也就实现了队列的高可用了,但我们切记不要滥用这个机制,在上面也说了,队列的冗余操作会导致不能通过扩展节点增加存储空间,而且会造成性能瓶颈。
命令格式如下:
$ rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
Definition: 镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode: 指明镜像队列的模式,有效值为 all/exactly/nodes
all: 表示在集群中所有的节点上进行镜像
exactly: 表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes: 表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params: ha-mode模式需要用到的参数
ha-sync-mode: 进行队列中消息的同步方式,有效值为automatic和manual
priority: 可选参数,policy的优先级
举几个例子:
$ rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
上述命令会将所有的队列冗余到所有节点上,一般可以拿来测试。
$ rabbitmqctl set_policy ha-two "^two." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
$ rabbitmqctl set_policy ha-nodes "^nodes." '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
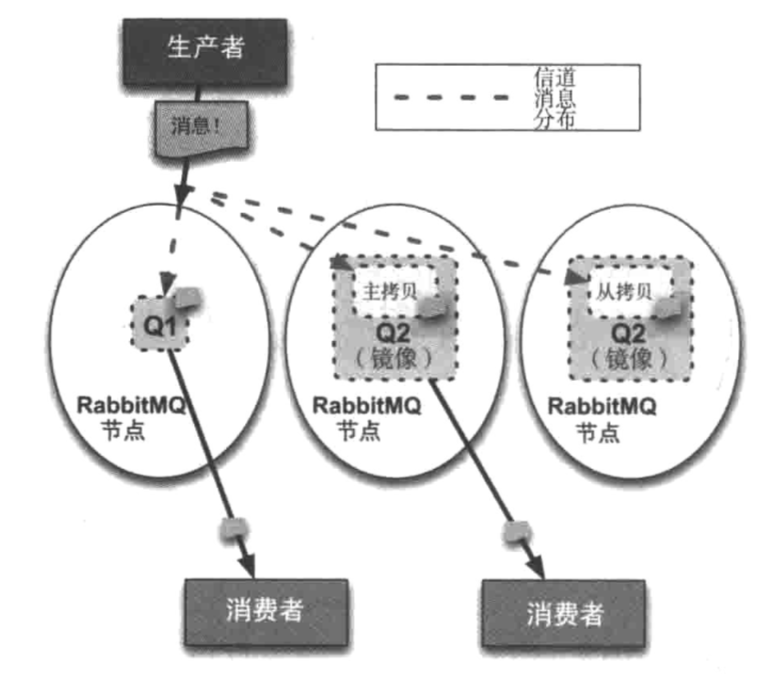
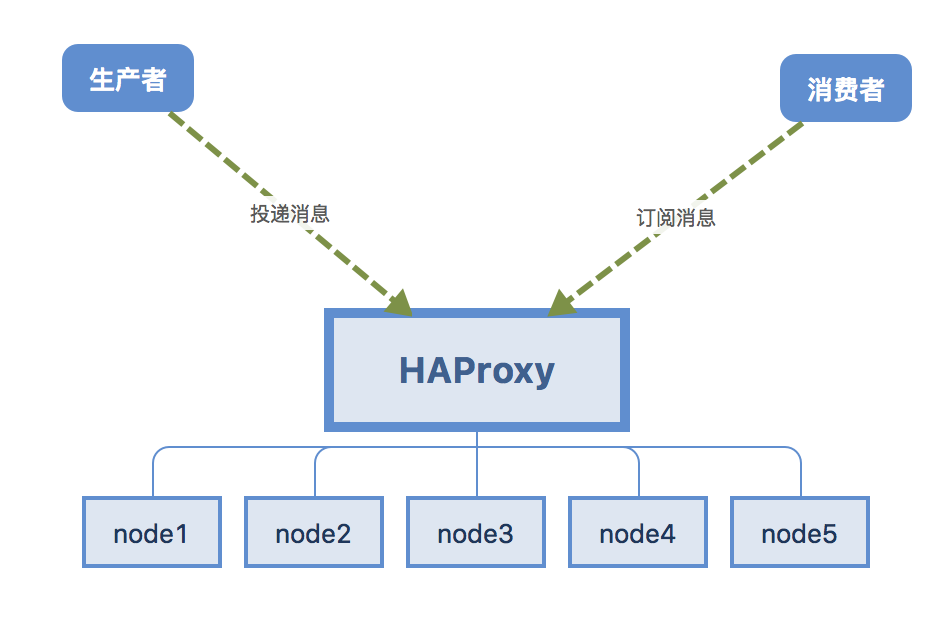
HAProxy 提供高可用性、负载均衡以及基于 TCP 和 HTTP 应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。
集群负载均和架构图:
安装 HAProxy:
$ yum install haproxy
编辑 HAProxy 配置文件:
$ vim /etc/haproxy/haproxy.cfg
加入以下内容:
#绑定配置
listen rabbitmq_cluster 0.0.0.0:5670
#配置TCP模式
mode tcp
#加权轮询
balance roundrobin
#RabbitMQ集群节点配置
server node1 193.112.61.178:5672 check inter 2000 rise 2 fall 3
server node2 111.230.254.127:5672 check inter 2000 rise 2 fall 3
#haproxy监控页面地址
listen monitor 0.0.0.0:8100
mode http
option httplog
stats enable
stats uri /stats
stats refresh 5s
启动 HAProxy:
$ /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg
后台管理: