Solid 是 social linked data (社交互联数据) 的缩写,简单来介绍就是一个可以把现在分散在微信朋友圈、微博、推特等等产品上的自己几十个账号内的数据都保存到一个地方的分布式社交应用设计规范。按着它来的话应用的用户可以把数据存到自己想存的存储空间里,而不是疼讯、新浪或者某国外不存在公司的服务器上。对于用户来说好处是你发一条微博之后还可以一键同步到朋友圈(语义互操作性),以及以后不是你求渠道爸爸上你的文而是每一个渠道花钱来求你上你的文(内容生产者完全拥有数据)。
Solid 是一场革命,革的就是体大不尊的巨头的命,把数据还给人民,让人民能用自己的数据做更多自动化,让人民能用自己的数据赚更多的钱。
做到这些事情的关键是数据与应用分离,这一点 Tim 在他的 Design Issue 里早就深思熟虑过了[2] ,如果让用户拥有他生产出来的数据,而不是现在这样由巨头公司存在它们的中心化服务器里,我们可以:
总之,这些想法早就已经存在 [16],以各种 W3C 草案或者推荐标准的形式躺尸多年,现在 Tim 开始行动了,Solid 协议栈不是一个全新的东西,它是很多现有的 W3C 规范的合集,以一种有机的方式结合起来。除了给出一套规范以外,Solid 还提供了很多 js 工具,比如 solid-client 就让我们能方便地用规范的方式登录账号、存储数据,solid server 就是一个参考的服务端实现。
已经有一些原型应用围绕这套规范建立,比如在线文本编辑器 dokieli 、 RDF 数据存储 databox 等,这些开源应用都可以被社区拿来参考。
本文将介绍 Solid 协议栈涉及到的各种概念,以及我们能如何用以太坊、IPFS 等新的分布式应用基础设施来实现 Solid 应用,光复去中心化的民主互联网。
https://linonetwo.inrupt.net/profile/card#me 是我的 WebID,你可以试着用它在 试验场 登录,看看各种操作会返回什么。
WebID 是我们登录使用 Solid 应用的用户名,同时也兼具密码的功能。这个 WebID 可以用于登录所有基于 Solid 技术栈的应用,现在用支付宝账号能登录所有阿里系的应用、用微信账号登录所有疼讯系的应用,以后一个 WebID 就能登录所有这些应用。
使用 WebID 登录 Solid 应用意味着授权这个应用读取你的头像、工作单位等等基本信息,这些信息都是用 RDF 语言写的,RDF 是资源描述框架(Resource Description Framework)的缩写,用于告诉电脑一段自然语言的实际意义是什么(说是告诉电脑,其实是告诉应用的开发者)。如果现在这段话使用 RDF 标注了,那么这段话就像打了 Tag 一样,一个知识导图社交平台(分享各自 MindMap 的问答社区)就能从这篇文章自动生成一个知识导图,这个知识导图生成器就能自动看出这段文本涉及到了语义网的基础知识。也就是说用了 RDF,到处都是自动服务,而且这种自动服务开发起来很简单,高中生都能开发。不然某个文本处理应用的开发者想要为这篇文章生成摘要的时候,就得用很多 AI 技术,来判断这篇文章中的 RDF 到底指的是资源描述框架还是仙境传说地下城勇士(Ragnarok Dungeon Fighter)这款游戏,这就得请几个博士来写了。
所以如果我们的数据用 RDF 或其变体来书写,我们就可以用上很多神奇而低成本的智能应用。而如果不用 RDF 的话,我们就得花十几块钱来用深度学习开发的人工智能应用了,应用开发成本这么高,对用户来说显然也不是一件好事。
RDF 可以用不同的方言语法来书写,也可以用各种编辑器来填写,也可以通过点按钮来自动填写,所以不会 RDF 的人也能在无意中生产 RDF 数据。我的 WebID 里用的是 w3c 推荐的 turtle 语法,它是 RDF 的一种。Turtle 和 JSON-LD 是 RDF 的两种优化了可读性的版本 [13] 。对于有一定技术背景,想要手写 RDF 的人来说,它们比较好写;对于编写智能程序的程序员,还有编写自动写 RDF 的程序的开发者来说,它们又很好读。
用户用 WebID 登录智能应用后,智能应用会根据你在 WebID 上的数据,为你提供不同的服务,比如在中午用餐时间根据你的工作地点自动设置好送外卖的地址。
站在前端应用开发者的角度来看,开发新应用的成本会变小,因为在 Solid 技术栈下使用用户数据总是有相同的体验,不需要每次都了解一遍新的后端 API,拿到的数据用的都是 FOAF 这样的标准词典。
https://linonetwo.inrupt.net/profile/card#me 中井号前的部分 https://linonetwo.inrupt.net/profile/card 是一个个人信息页面,加上 #me 其实返回的信息差不多,但是语义上不带井号的 URI 意思就是一个个人信息页面,加上 #me 或者 #i 的就是一个名字的感觉,指的是我这个人,所以登录各种应用的时候不应该是给应用我的个人页面 https://linonetwo.inrupt.net/profile/card,而应该给它我的名字,也就是 https://linonetwo.inrupt.net/profile/card#me [5]。
那么 https://linonetwo.inrupt.net/profile/card 这个页面上有很多我的个人信息,比如我认识的人,我的女朋友是谁,但我可能不想让人知道我老家是厦门,想只让几个我知道是我老乡的人能使用我的家乡信息,也就是我要做权限控制。这个可以使用 WebAccessControl 来做,在我的个人页面上引用存着我家乡信息的文件,但是那个文件上加了一个权限列表(ACL),这样就解决了公开信息的隐私问题。实际应用中,你在各种应用里的设置、个人偏好都会放到仅私人权限可见的分组里,以防闲人看到你用过哪些应用,在应用里有什么奇奇怪怪的偏好 [6]。从开发者的角度来看,Solid 也会引导你找到你可以存储数据的地方,因此你不需要遍历用户的所有数据来找你存储的数据,或者其他你关心的数据 [7]。
那如果别人用我的 WebID 去某个论坛上发言怎么办呢?这时候第一是靠 HTTPS,第二是靠数字证书,然后在它们的基础上再做进一步的身份验证。
我们知道以太坊钱包它不需要你提供一个密码,因为没有一个中心服务器给你存密码,以太坊的身份校验是通过公钥和私钥。
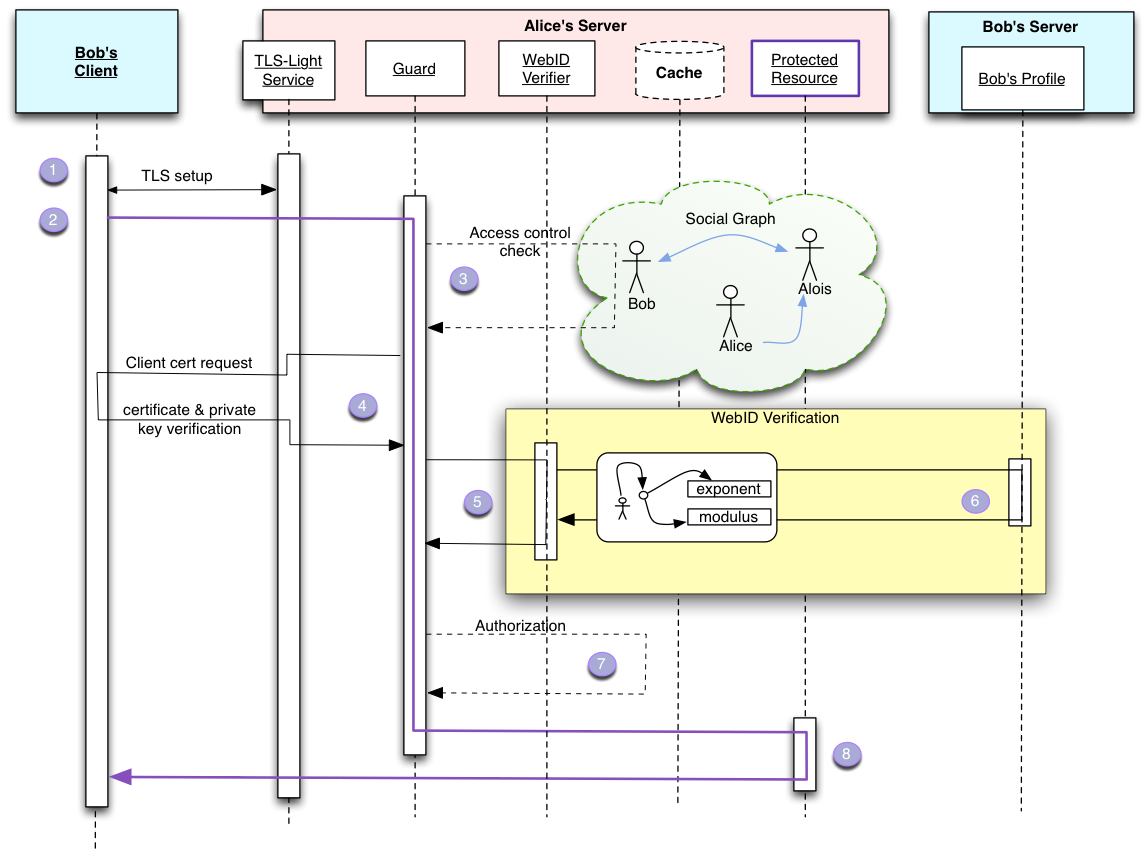
WebID 也很类似,我们首先要生成一份公钥放在我们的页面上(放在 https://linonetwo.inrupt.net/profile/card 里),然后把配套的私钥存在浏览器里(或者一个专用的密码管理器,类似于 MetaMask,或者一个冷钱包),接着当你打开一个有一定权限管理的程序的时候,如下图的事情就会发生:
 (图:选择证书)
(图:选择证书)
爱丽丝可能还上传了很多自己穿 lo 裙的照片,并把它们设置成所有人不可见。但是她决定把自己的照片传到一个美图点赞社交平台上,这个社交平台给每个被点赞的人都发放代币(Token),这些 Token 在交易所上每个值 0.0003 BTC。为了保证浏览这些图片的流量都到这个美图点赞社交平台上,从而有足够多的人来为她点赞,她给所有照片都存储一份使用这个平台的公钥加密的版本,因此只有通过这个平台才能获取到用私钥解密的图片。这无法保证图片不被盗用,但可能会保证这个平台的代币在交易所上一直增值(通过聚集注意力和信念,👆)。
使用证书加私钥可能不是一个很舒服的操作,毕竟我们第一不习惯,第二私钥丢了账号就没了。
回过头来想,证书是为了提供信任,那么能不能用区块链来做这个信任层呢?UPort 说,可以用一个以太坊地址作为 WebID。
这种传统模式有一些核心问题。 如果你丢失私钥(丢失,盗窃或其他方式),你将失去身份。 此外,如果没有额外的中心化基础设施,也不能直接撤销密钥,也不能将身份的控制安全地转移给其他人。 这些技术上的限制阻碍了人们在加密身份系统上的尝试。 以太坊智能合约为我们提供了一个加密密钥管理问题的通用解决方案,为设置永久身份提供了基础。 可以通过智能合同或传统公共密钥的地址来表示以太坊身份。 由于智能合同可以由其他智能合同来控制,因此可以对其进行编程,以支持各种私钥找回方法。 由以太坊提供的灵活控制逻辑使加密身份变得既友好又有意义。 uPort 身份是一个非常简单的智能合同,由可替换的控制器合同控制,其中包含密钥恢复和访问控制逻辑。 控制器合同又由安全地存储在智能手机上的密钥控制。 [18]
区别于 W3C 推荐的 turtle + 中心化服务器 + CA 证书,UPort 采用的 JSON-LD + IPFS + Ethereum 显然对开发者和使用者都更友好。[17]
总结一下,使用现在的古典互联网应用时,我们需要用用户名密码来登录,但是使用 WebID 的时候我们只需要点击一下我们想要使用的账户,并不需要输入密码。
当我们使用另一台电脑的时候,古典互联网应用允许我们继续使用同样的用户名密码,但是 Solid 技术栈应用就要求我们像使用基于以太坊的应用一样,先把私钥同步过去,才能一劳永逸地登录(这里说的是 WebID-TLS 方案,当然,其实也有其他更便捷的临时方法来登录,比如 WebID-OIDC 方案)。 如果基于 IPFS 来存储身份信息,那么如果你用做服务器的电脑离线了,别人就无法访问你的用户基本资料了。但这可以通过 follow 机制来避免,也就是你的每一个粉丝都会 pin 住一份你的基本资料,所以越多粉的人,他的用户资料就越难丢失。
最后,Solid 技术栈的应用会有更丰富的权限管理机制,这对于内容发布者来说自然是一件好事,如果和加密货币结合起来,在权限检查的时候不是检查社交关系而是去检查某个智能合约的结果,那可能就是内容付费的新路子。当然,这可能超出了 WebACL 的支持范围 [10]。
使用 WebID 登录要求每个人都有一个公开在网页上的个人页面,在校验身份的时候,你访问的服务器会去访问你的个人页面。那么不懂互联网技术、没有购买自己的服务器的人要怎么拥有个人页面呢?一台符合 Solid 应用要求的阿里云服务器每年要花掉 300 元左右人民币,而且非技术专业的人还得花费数个人月来学习互联网技术,中小学生的父母可能愿意花一千元人民币为孩子购买手机,但不一定会愿意或者不一定有能力给孩子开服务器,更何谈去中心化地人人自建服务器。
所以仅在数据存储这一方面,现在的互联网就没法支持 Solid 应用的普及。
好在 Solid 在存储方面使用了 Linked Data Platform 规范 [12],只要能遵循这个规范用 REST 请求来请求数据、增删数据的存储服务就可以用作 Solid 应用的存储空间。这个服务可以是一个中心化的免费云盘,比如用现在 demo 性质的 databox 服务就可以一键创建一个你自己的 LDP(Linked Data Platform),而且自动帮你创建个人信息页面。这样的数据存储虽然并不是保存在我们的个人电脑上,看似是违背了 Solid 技术栈的初衷,但我们其实可以在多家互相竞争的数据存储服务商之间自由选择,这样我们的信息其实是去中心化存储的(注意不是分布式存储),因为避开了中心化数据存储,所有 Solid 应用还是能带着互联网走向设计之初设想的样子。而且使用专业的第三方存储提供商也可以降低普通用户的使用门槛。
所以,我们应该去选择其他去中心化存储空间,比如以太坊或 IPFS,并在其上用 serverless 的方式做权限验证、数据增删,从而彻底告别中心化服务器。对非技术人员来说,好处是不用再去购买、架设服务器了,只需要用加密货币支付存储费用,然后一键生成自己的 LDP 服务即可,而且 IPFS 技术带来的去中心化云盘(其实只是 CDN),价格会比带有 CPU、内存成本的阿里云服务器便宜得多,可能小学生都用得起。
任何一个中心化的数据存储提供方都可能会吞掉我们的数据,比如百度贴吧会肆意删掉几百页的帖子、新浪爱问知识人会被整个关闭、百度云里的葫芦娃视频会变成 8 秒的净网行动视频。 中心化的数据存储也不一定安全,例如医疗系统因为软硬件落后,很容易遭到勒索攻击导致数据丢失,从业人员也有可能因缺乏培训而受到社会工程学攻击泄露信息。
在 Solid 之外,我们其实已经有用于编写分布式互联网应用的技术栈,例如以太坊。我们也有分布式地存储数据的技术栈,例如 IPFS。而因为互联网应用本身就是数据,所以上述两个技术栈可以交换着用,例如 vue-ethereum-ipfs 就是用以太坊来存储数据,用 IPFS 来发送 HTML 和 JS 书写的互联网应用。
IPFS 是一个内容分发网络,其使用体验例如你的邻居住在厦门,要访问在北京的一个网站,那么他就得让北京的网站服务器把这个页面里的 HTML、JS、图片都从北京通过城际光纤发送到厦门。但随后如果你也想访问这个网站,那你就可以直接从你的邻居处取用这个数据,大家共享数据,你离数据就会特别近,访问速度极快。
IPFS 类似于 BT 下载器,当你在一台电脑上上传一个文件到 IPFS 网络后,这个文件其实一直留在你的电脑本地的一个数据仓库里,相当于一个 BT 种子,等待其他需要这个文件的人来取用。这个上传到电脑本地 IPFS 数据仓库的文件会获得一个散列值(以 multihash 的形式),如果你用这个散列值生成一个二维码,然后用手机上的 IPFS 应用扫码,手机上的 IPFS 应用会把这个文件 pin 到手机本地(pin 就是像大头针那样,把一个便签纸钉在墙上,永久保存),于是你的手机上就有一个文件的备份了。这时你再扫另一台电脑上的二维码,发起一个 pin request(通过 GET 请求把刚刚那个文件的 multihash 发给第二台电脑),第二台电脑就会 pin 住文件,从而下载第一台电脑和你的手机上保存着的这个文件。这样你就通过两次扫码完成了跨电脑的文件传输,而且你的手机此时作为一台永不下线的服务器,还可以一直提供这个文件的下载服务。
在过去,互联网的发明者期望每个人都能有自己的服务器来发布文件和数据,但购买服务器和使用服务器程序门槛实在是有点高,因此我们现在其实是把文件传到中心化的百度云上,把聊天数据放到疼讯一手掌控的服务器里。而巨头之间又不肯亲密合作,所以我们没法用一个搜索引擎就一次性搜索出自己关于 n n+1 n-2 n/2 的百度云文件和疼讯聊天记录、微博发言,第一是因为你没法这么发言,都被审查永久删掉了,第二是几个巨头的数据没有打通。
现在有了 IPFS,我们可以实现当年设想的应用了,用户只要通过拖放上传文件和数据到 IPFS,然后手机扫码把文件 pin 在手机上,我们就拥有了一台 7 x 24 在线、能分发轻量级数据的服务器,当有其他设备也请求了这份文件,它也会成为一个分发数据的节点来减轻我们的流量压力。
我们可以把所有和自己相关的数据都放在自己的电脑和手机上,当然也可以向远处的其他 IPFS 存储节点或者存储矿工申请备份自己的数据,从而保证自己的数据永不丢失。如果每个人都这样保存自己的数据,我们的数据就不会中心化地存储在互联网巨头的服务器里,而是去中心化地存储在每个人自己的设备里了。
要让我们去中心化地存储我们的数据,最重要的是要有对应的程序。微信暂时是不可能支持把聊天数据保存到 IPFS 上,返还给我们个人所有的。但我们如果用 JavaScript 开发新的网页版的开源聊天软件,我们通过 IPFS 下载这个应用(其实就是通过浏览器访问它的网站,但是网站通过 IPFS 来分发),它在加好友的时候使用的是 WebID,不是把「我们俩是好友」这条信息放到一个服务器上,而是把「A 和我是好友」这条信息复制两份保存到我们俩人的个人社交图谱里,这个社交图谱以 RDF 的形式存储,链接在我们的个人主页上。它在存储聊天信息的时候也是在聊天双方的浏览器上直接把聊天内容保存到 IPFS 上。这样有一天你觉得这个聊天应用体验不好,换成另一个问答社交应用,你可能会发现问答社交应用的私信模块里还能查看和搜索你之前产生的聊天记录。也就是说,只要你不想丢,你的聊天记录永远不会丢失,就算你弃用某个聊天应用也一样。但是如果你想丢,你不用求着这些应用的开发商帮你删除数据,你可以自己删除自己拥有的几个备份。
IPFS 网络上的内容是所有人都可以访问的,除非:
截至目前,在 IPFS 上启动 Solid 服务器很简单,如果你能修改代码的话,把这个位置把文件写入本地文件系统的操作 改成写入 IPFS 就好了。
添加文件到 IPFS 上的主要意义在于,数据此时可以通过 IPFS 从一台服务器同步到另一台服务器。但前提是 POD 要维护一份里面文件的列表,包含这些文件的 multihash,从而另一个 POD 能够看着这份列表把所有文件同步过来。
还有一个作用就是可以在浏览器中动态创建 POD,并在把数据保存到 IPFS 后,请求某个 Pin Service 保存刚放到本地 IPFS repo 里的数据,例如你的手机。这将使得你的数据真正去中心化,对于不信任第三方 POD 的用户很有用。
最简单的分布式应用就是通过 IPFS 分发的普通 Web 应用,只不过这些应用没有后端,读写数据都发生在 IPFS 上,开发者开发完应用后把 HTML、JS 和其他静态文件上传到 IPFS 上,然后用户就可以通过某个 IPFS 网关,比如 ipfs.io/ipfs/ 来访问这个应用,网关会把文件从 IPFS 上取下来,然后通过 HTTP 发给用户。当然,FireFox 等浏览器也会支持直接打开在 IPFS 上的文件。
用户打开 Web 应用后,可以通过某个管理私钥的浏览器插件来授权 Web 应用读取必须的私人信息,来进行支付、把内容授权给某个平台等。浏览器插件用私钥解密用户之前放在 IPFS 上的个人文件,再传递给 Web 应用。Web 应用则往 IPFS 上添加未加密的各种数据,因为没有后端,这些应用无法保有任何秘密。当然,它们也可以通过浏览器插件来使用用户的私钥添加加密内容。
被应用放在 LDP 上的最重要的数据是互联数据,比如 turtle 三元组语言描述的个人信息页,背后是这样的。
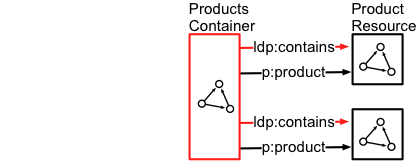
那为什么要放互联数据呢?如下图可见,容器直接标明了里面的两个文件的类型是 p:product ,因此任何访问这个容器的自动程序都能理解这个容器是用来放某种产品的。像之前说过的那样,这种程序的理解能力不需要高深的人工智能,但是对用户来说它的这种理解能力就是很智能。所以通过添加互联数据我们用户可以几乎零成本地使用一大堆「人工智能」应用。
还有一种常见数据就是图片、文档、PPT、程序安装包之类的任意类型的东西,你能往网盘里存什么,就能往 LDP 里放什么。比如上图中的两个 Product Resource 可能就是新旧两个版本的,色情游戏软件安装包。新版的色情游戏中为了维护和谐社会给所有东西都打了码,而原版色情图片中如下图可见,所有东西都没打码。
[图片]
最后,还有一种关键的资源,就是用来放上述资源的资源,LDPC(Linked Data Platform Container)也就是互联数据平台容器,像一个文件夹,但它不能是单纯的存储东西的文件夹,还得能响应 REST 请求,从而在文件夹里创建新的互联数据、图片、文档。例如 通过 PUT 方法来大量更新文档内容,PATCH 方法来增量更新文档内容,DELETE 方法来删除文档。
如果只是存储文档供其他人读取的话,我们可以很容易地用 IPFS 之类的分布式存储来实现,因为它们只需要实现 GET 方法。但 LDPC 这种需要 PUT 等方法的容器,就不止需要分布式存储,还需要有服务器来处理收到请求后的逻辑。如果在容器里 GET 数据的时候需要进行权限检验的话,那一般来说操作容器里的所有文件会需要服务器的支持,自建服务器是一个推荐的选项,在互联网创建之初对人们的期望就是每个人都能自建服务器发布自己的数据。
但如果我们往 IPFS 上存储互联数据的时候不是明文存储,而是用自己选择的某种加密方法混淆过的数据,对于没有权限浏览你的隐私数据的人或者自动程序来说,你放到 IPFS 上的数据就是一团乱码。但如果你觉得有必要向一个尽调程序公开你的性格数据(你上次使用一个性格检验程序后它把你的性格用 RDF 写入你的个人主页),你可以在本地用私钥解密你在 IPFS 上的数据,并用数字证书签名解密后的数据,仅提供给尽调程序使用。尽调程序可以用你的公钥重新加密你提供的数据,从而证明你提供的数据是真实存在于你的个人主页上的。
因此,我们其实可以在 IPFS 的基础上建立起无需服务器的,个人拥有所有自产数据的互联网。
互联数据平台可以用 REST API 来增删改查,也可以用 WebSocket 来做实时修改,因此可以在 LDP 上做出 Google Doc 这样的实施多人协作文档应用程序。
下表是一个类似 Github Issue 的 bug 追踪系统 可用的 REST API 列表:
| 路径 | 方法 | 描述 |
|---|---|---|
| /tracker/{product-id}/ | GET | 列出 product-id 对应的产品的描述信息,还有这个产品相关的 bug 报告 |
| /tracker/{product-id}/ | POST | 创建一个 product-id 对应的产品的 bug 报告 |
| /tracker/{product-id}/ | PUT | 更新 product-id 对应的产品的描述文档 |
| /tracker/{product-id}/ | DELETE | 删除 product-id 对应的产品的描述信息,还有这个产品相关的 bug 报告 |
| /tracker/{product-id}/{bug-id} | GET | 读取 product-id 下的 bug-id 对应的 bug 报告 |
| /tracker/{product-id}/{bug-id} | PUT | 更新 bug 报告 |
| /tracker/{product-id}/{bug-id} | DELETE | 删除 bug 报告 |
| /tracker/*/* | OPTIONS | 用于看某个资源允许哪些 REST 方法 |
| /tracker/*/* | HEAD | 只读取某个资源的元信息 |
如果用 IPFS 来搭建 LDP 的话,实现增删改查的方式会和 LDP 规范中描述的不大一样。LDP 要求有一个服务器能接收上述 REST 请求或者 WebSocket 连接,但 IPFS 仅仅是一个 CDN,不能处理 POST 请求。但是一个往 LDP 服务器里加入新文件的 POST 请求,在 IPFS 实现的 LDP 里可以对应到客户端用 ipfs-unixfs 向 IPFS 发出的创建新文件的请求。
也就是说本来 Solid 应用需要有前后端两个部分,在用户浏览器上运行的前端通过 POST 请求来让后端在 LDP 里创建文件。但使用 IPFS 的话,在用户浏览器上运行的前端可以直接在 LDP 里创建文件。但这样添加的文件只会存在于用户电脑本地的 IPFS 数据仓库内,如果用户关闭了电脑,那这个文件就无法访问了。所以想创建文件的用户可能还是得通过 POST 请求让自己的手机(或是一个存储矿工等等一直在线的 IPFS 节点)备份一下自己刚刚添加的文件。这种请求可以称为 Pin Request。
在使用应用的时候会产生很多消息(Notification),比如某个 Todo 要到 deadline 了,或者爬虫爬取到了新的新闻,或者一个约会邀请,这时你会希望收到发送方(Sender)及时推来的消息,而最终的信息消费者(Consumer)是从接收方(Receiver)那里去读取数据的,从(Receiver)那里读取到(Sender)推送来的数据之后,(Consumer)把它清洗成适合人类阅读的格式,比如在消息的开头加上个「您好尊敬的」然后再给你看。
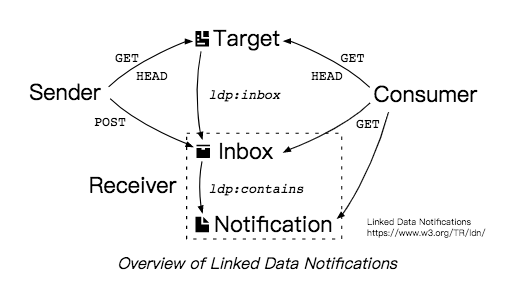
一个推送的流程是这样的:
要注意这个过程可能会产生「放大攻击」的机会,也就是恶意攻击者构造一个 inbux 地址,然后触发大量的 sender,导致 Receiver 被搞垮。这是因为 Sender 和 Consumer 要通过一系列 REST 请求询问 Target 来发现收件箱的位置,如果一个热门 Target 被攻陷了,那它就可以指向一个无辜的 Inbox。
Linked Data Notification 规范要求我们实现多个支持 REST API 的服务器,如果我们想做到不用购买服务器就拥有自己的 Inbox,那我们需要在规范基础上做出一点改变。例如 Sender 直接向 IPFS 这样无服务器的存储服务上添加信息,然后通过 pubsub 之类的长连接与 Inbox 和 Receiver 共享 multihash。
很多用户可能会选择把自己写的文章拍的短视频发到一个中转节点上,并订阅这个中转节点上其他人生产的内容。[14]
这个中转节点可能是一个中心化的服务器,比如泛用无界角色扮演平台上有很多语言 cos 线程(即帖子),当用户订阅了某个线程之后,浏览器通过 POST 请求把用户的 WebID 发给这个线程的收件箱,并维护一个与服务器的长连接,从而在有新的回复时及时通知用户。
如果用户出于情怀等原因不愿意连接到一个中心化服务器,她使用的 Web 应用会直接把她说的话保存到 IPFS 上,此时其他用户有两种选择来获取最新的对白,一是通过与其他 Web 应用之间的 pubsub 来获得 p2p 推送;二是 Web 应用在开启状态下会不断轮询一个 LDP 容器,看看有没有新的内容放进去。
Solid 技术栈的内容并不复杂,只是引用的文档特别多且长。技术栈主要包括以下几部分:
这些就是一个分布式社交系统会需要的底层设施,它们要求个人部署服务器来存储自己的个人信息主页还有各种归属于自己的 UGC 数据。按照 Solid 规范制作的应用和服务具有很强的互操作性,也就是数据都打通了,没有隔阂和壁垒,因此对于某个需求比如聊天需求,会涌现出来各种竞品,用户可以选择符合自己个性感觉最好用的那一个,而且还会出现各种智能程序自动做一些简单的脑力劳动,利用人们产生的数据解放出更多的生产力。
为了降低个人在购买和使用服务器上的难度,我在文章中设想了一些简单的使用 IPFS 技术替代掉 Solid 协议栈中存储服务的方法。由于 Solid 规范、IPFS 技术,还有特别是我本人都不是很完善,想法上还有很多偏差和缺漏亟待做原型来检验 [15]。其实现在已经有一些带有类似愿景的项目,推荐读者到 IPFS 应用大典 和 分布式应用大典翻一翻参考参考。最后要指出,本文对 Solid 协议栈的阐述主要来自于规范文档 [3] 中的各种链接指向的 W3C 文章,由于阅读时间有限,以及文章的枯燥性,必然会产生理解上的偏差,希望有能力的朋友在阅读原文后能指出我宣传上出的偏差。