
总体时间线参考 这里.
Our system works in two stages; first we train a transformer model on a very large amount of data in an unsupervised manner — using language modeling as a training signal — then we fine-tune this model on much smaller supervised datasets to help it solve specific tasks.
We trained a 12-layer decoder-only transformer with masked self-attention heads (768 dimensional states and 12 attention heads).
GPT 全称 generative pre-training, 就是预训练 + 微调. 时间顺序从前到后依次是, GPT-1, BERT, GPT-2.
<!-- more -->
GPT-2 is a direct scale-up of GPT, with more than 10X the parameters (1542M vs 117M) and trained on more than 10X the amount of data. Github: openai/gpt-2.
方法
不再针对单独的任务分别微调
Learning to perform a single task can be expressed in a probabilistic framework as estimating a conditional distribution p(output | input). Since a general system should be able to perform many different tasks, even for the same input, it should condition not only on the input but also on the task to be performed. That is, it should model p(output | input, task).
For example, a translation training example can be written as the sequence
(translate to french, english text, french text). Likewise, a reading comprehension training example can be written as(answer the question, document, question, answer).
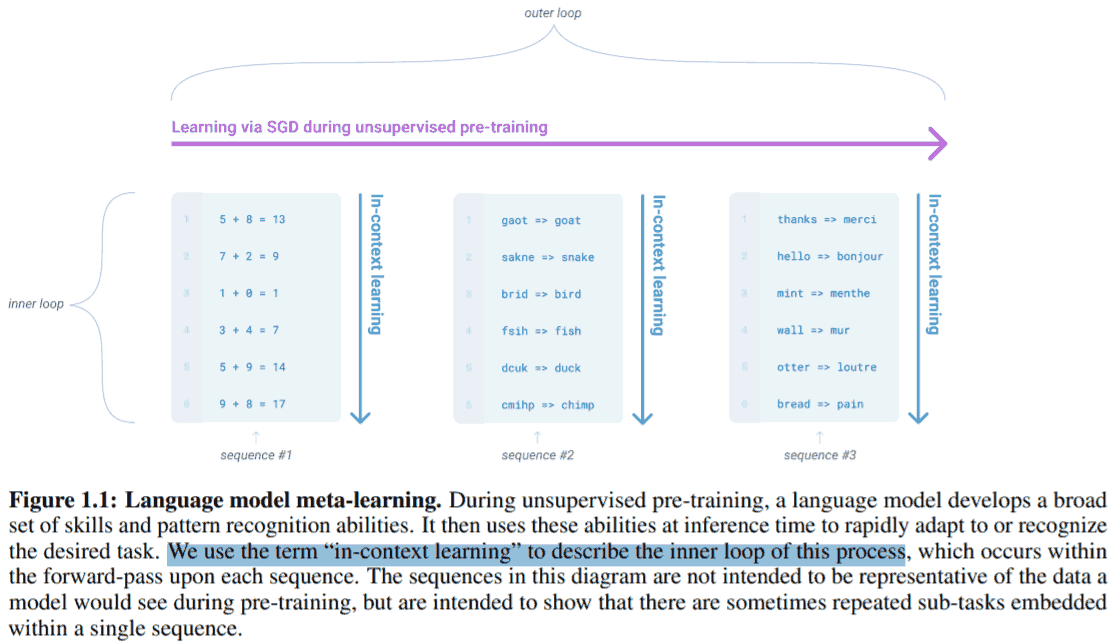
Our speculation is that a language model with sufficient capacity will begin to learn to infer and perform the tasks demonstrated in natural language sequences in order to better predict them, regardless of their method of procurement. If a language model is able to do this it will be, in effect, performing unsupervised multitask learning. We test whether this is the case by analyzing the performance of language models in a zero-shot setting on a wide variety of tasks.
数据
Our approach motivates building as large and diverse a dataset as possible in order to collect natural language demonstrations of tasks in as varied of domains and contexts as possible.

GPT-2 的更大版本 (175 billion 参数, 是 GPT-2 的上百倍).
For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
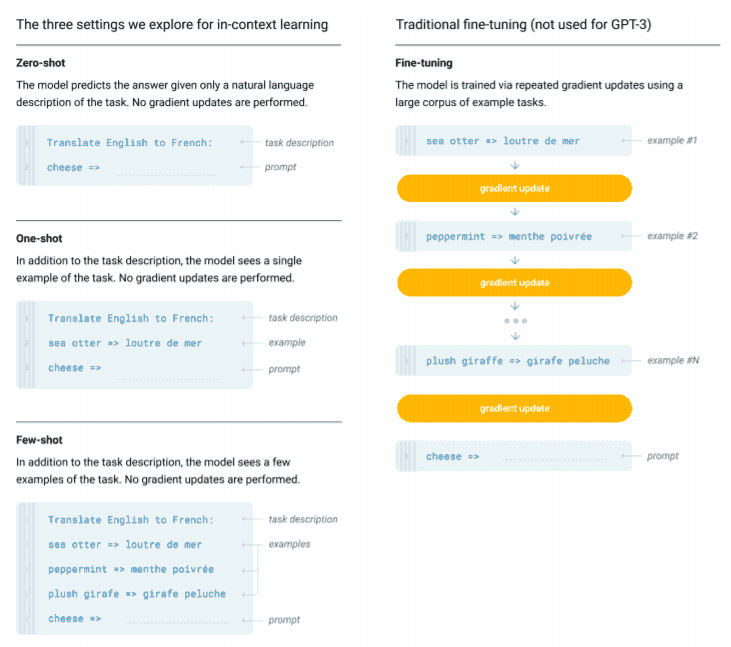

涉及到的所有模型都是 GPT-3 结构, 参数量大小不同. InstructGPT (1.3B 参数量) is better than GPT-3 at following English instructions.
But these models (GPT-3) can also generate outputs that are untruthful, toxic, or reflect harmful sentiments. This is in part because GPT-3 is trained to predict the next word on a large dataset of Internet text, rather than to safely perform the language task that the user wants. In other words, these models aren't aligned with their users.
To make our models safer, more helpful, and more aligned, we use an existing technique called reinforcement learning from human feedback (RLHF).
We hired about 40 contractors... We kept our team of contractors small because this facilitates high-bandwidth communication with a smaller set of contractors who are doing the task full-time.
The SFT dataset contains about 13k training prompts (from the API and labeler-written), the RM dataset has 33k training prompts (from the API and labeler-written), and the PPO dataset has 31k training prompts (only from the API).
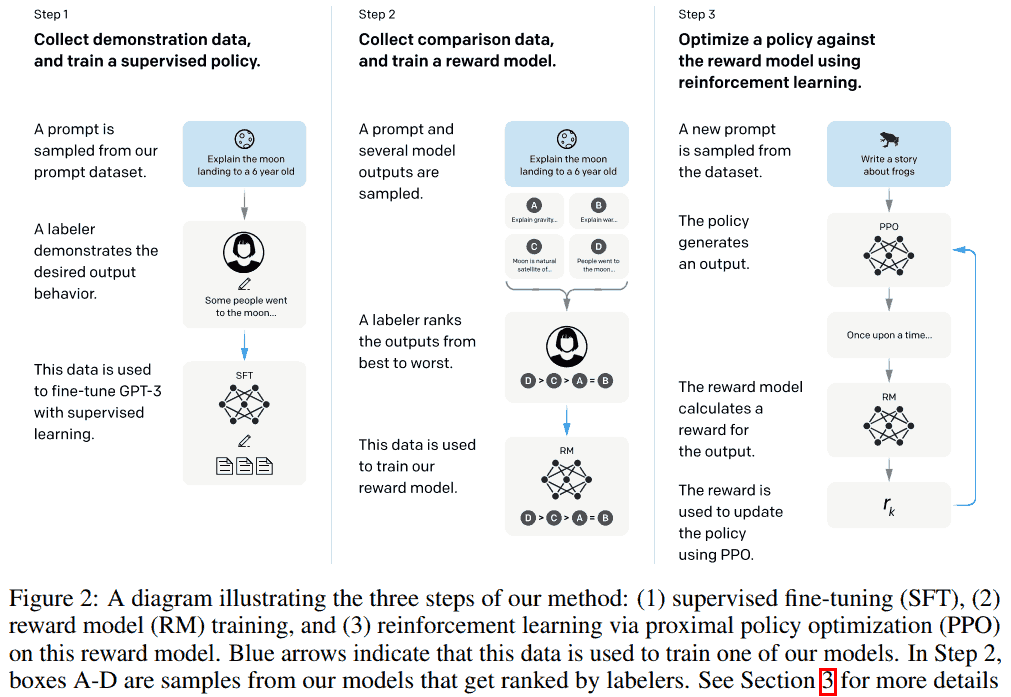
解释一下 step 3. 不涉及强化学习的术语, "宏观上" 可以把流程类比到普通深度学习.
A limitation of this approach is that it introduces an "alignment tax": aligning the models only on customer tasks can make their performance worse on some other academic NLP tasks.
We've found a simple algorithmic change that minimizes this alignment tax: during RL fine-tuning we mix in a small fraction of the original data used to train GPT-3, and train on this data using the normal log likelihood maximization.
We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup. We trained an initial model using supervised fine-tuning: human AI trainers provided conversations in which they played both sides—the user and an AI assistant. We gave the trainers access to model-written suggestions to help them compose their responses. We mixed this new dialogue dataset with the InstructGPT dataset, which we transformed into a dialogue format.
数据闭环的成功: 只有我一个人对 ChatGPT 感到蕉绿吗?
扩展阅读