There are various reasons why you might want to distribute a database across multiple machines:
Replication means keeping a copy of the same data on multiple machines that are connected via a network. All of the difficulty in replication lies in handling changes to replicated data.
<!-- more -->In this chapter we will assume that your dataset is so small that each machine can hold a copy of the entire dataset.
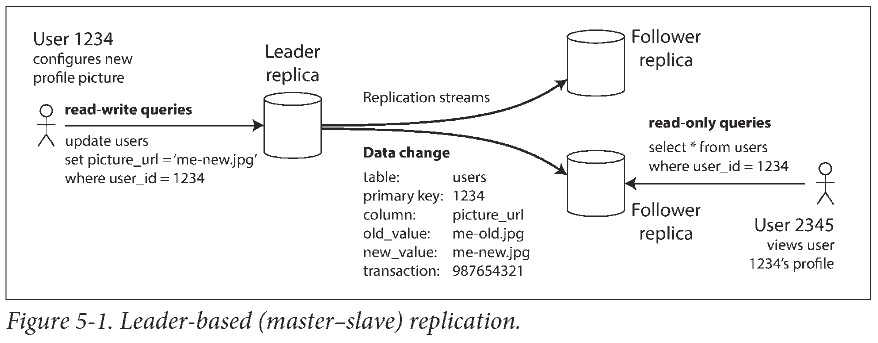
Each node that stores a copy of the database is called a replica (副本). Every write to the database needs to be processed by every replica. The most common solution for this is called leader-based replication (also known as active/passive or master–slave replication).
先看单主复制

同步复制保证主从数据一致, 但任何一个节点中断都会导致系统停滞. 实际中的同步复制通常指半同步 (semi-synchronous): 一个 从库同步, 其他都是异步. 如果同步从库不可用或缓慢, 则使一个异步从库变为同步.
通常主从复制都配置为完全异步, 意味着写入可能丢失.
Follower failure: Catch-up recovery
On its local disk, each follower keeps a log of the data changes it has received from the leader. 根据日志拉取新的变动即可.
Leader failure: Failover
Failover (故障切换): One of the followers needs to be promoted to be the new leader, clients need to be reconfigured to send their writes to the new leader, and the other followers need to start consuming data changes from the new leader.
问题
这些问题没有简单的解决方案, 所以不少运维团队还是愿意手动执行故障切换.
异步复制下, 主从数据会有一段时间不一致. 但如果停止写入并等待一段 (不确定的) 时间, 主从最终会一致, 称为 最终一致性 (eventual consistency).
Reading Your Own Writes

一些解决方案
一种复杂情况是: 同一用户从多个设备请求服务. 略.
Monotonic Reads

例如, 可以基于用户 ID 的 hash 选择副本, 确保每个用户从同一个副本读取.
Consistent Prefix Reads

This is a particular problem in partitioned (sharded) databases. In many distributed databases, different partitions operate independently, so there is no global ordering of writes.
One solution is to make sure that any writes that are causally related to each other are written to the same partition—but in some applications that cannot be done efficiently.
We call this a multi-leader configuration (also known as master–master or active/active replication). In this setup, each leader simultaneously acts as a follower to the other leaders.
Use Cases for Multi-Leader Replication
Handling Write Conflicts
允许任何副本接受客户端的写入请求. 客户端发送每个写入请求到若干节点, 并从多个节点并行读取, 以检测和纠正具有陈旧数据的节点.
The idea was mostly forgotten during the era of dominance of relational databases. It once again became a fashionable architecture for databases after Amazon used it for its in-house Dynamo system.
略.
For very large datasets, or very high query throughput, replication is not sufficient: we need to break the data up into partitions, also known as sharding. The main reason for wanting to partition data is scalability.
Normally, partitions are defined in such a way that each piece of data (each record, row, or document) belongs to exactly one partition.
Partitioning is usually combined with replication so that copies of each partition are stored on multiple nodes. A node may store more than one partition.
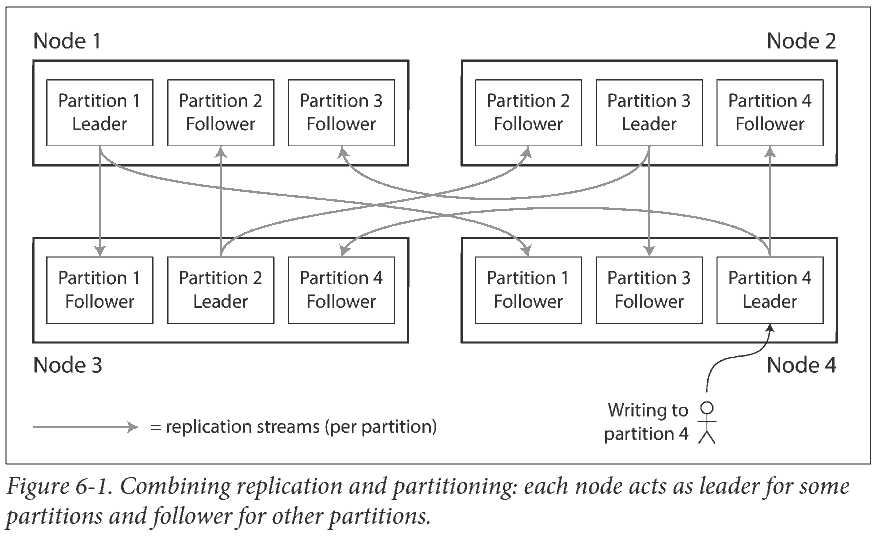
The choice of partitioning scheme is mostly independent of the choice of replication scheme, so we will keep things simple and ignore replication in this chapter.
Our goal with partitioning is to spread the data and the query load evenly across nodes. 不均匀则称为偏斜 (skew), 极端不均匀导致的高负载分区称为热点 (hot spot).
Partitioning by Key Range

The downside of key range partitioning is that certain access patterns can lead to hot spots. If the key is a timestamp, then the partitions correspond to ranges of time—e.g., one partition per day. Unfortunately, because we write data from the sensors to the database as the measurements happen, all the writes end up going to the same partition (the one for today), so that partition can be overloaded with writes while others sit idle. 可以给时间戳 key 加上 sensor name 的前缀.
Partitioning by Hash of Key
By using the hash of the key for partitioning we lose a nice property of key-range partitioning: the ability to do efficient range queries.
Skewed Workloads and Relieving Hot Spots
Hash 分区可以帮助减少热点. 但极端情况下, 所有读写针对同一个 key, 所有请求都路由到同一个分区. 比如百万粉丝的名人做一个操作.
大多数系统无法自动处理这种高度偏斜的负载, 需要依靠应用程序. 比如在主键开头或末尾添加随机数.
次级索引分区: 略.
将负载从集群中的一个节点向另一个节点移动的过程称为 再平衡 (rebalancing).
最低要求
How not to do it: hash mod N
The problem with the mod N approach is that if the number of nodes N changes, most of the keys will need to be moved from one node to another.
Fixed number of partitions
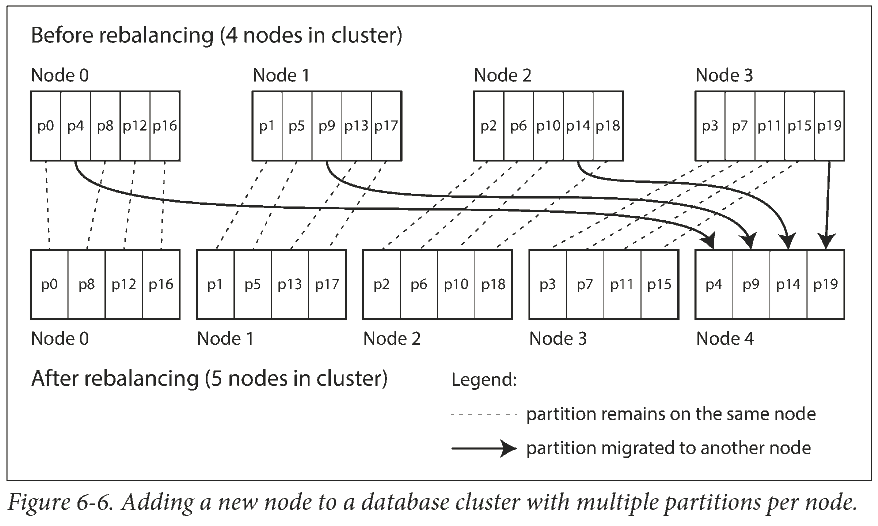
A fairly simple solution: create many more partitions than there are nodes, and assign several partitions to each node.
Only entire partitions are moved between nodes. The number of partitions does not change, nor does the assignment of keys to partitions. The only thing that changes is the assignment of partitions to nodes.
Dynamic partitioning
For databases that use key range partitioning, a fixed number of partitions with fixed boundaries would be very inconvenient: if you got the boundaries wrong, you could end up with all of the data in one partition. (hash 分区也可以动态分区)
For that reason, key range–partitioned databases such as HBase and RethinkDB create partitions dynamically. 过大就分裂, 过小就合并.
Partitioning proportionally to nodes
Have a fixed number of partitions per node.
This is an instance of a more general problem called service discovery, which isn't limited to just databases.
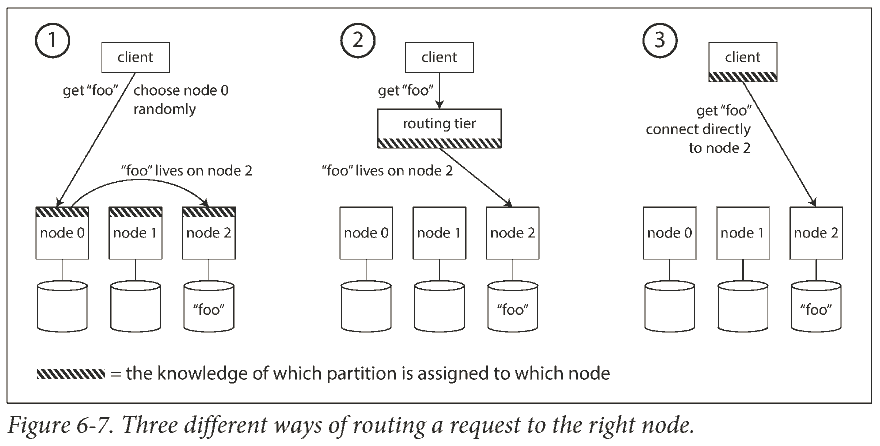
On a high level, there are a few different approaches to this problem:
In all cases, the key problem is: how does the component making the routing decision learn about changes in the assignment of partitions to nodes?
Many distributed data systems rely on a separate coordination service such as ZooKeeper to keep track of this cluster metadata.
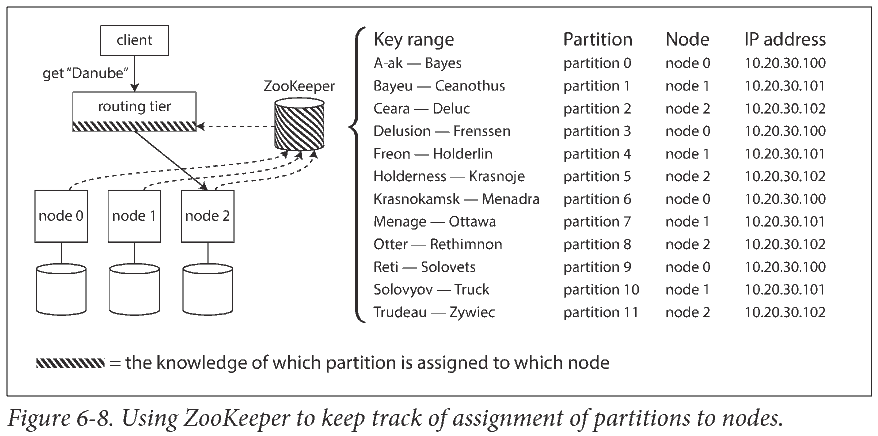
A transaction is a way for an application to group several reads and writes together into a logical unit. Conceptually, all the reads and writes in a transaction are executed as one operation: either the entire transaction succeeds (commit) or it fails (abort, rollback).
In practice, one database's implementation of ACID does not equal another's implementation. ACID has unfortunately become mostly a marketing term.
ACID 的原子性和隔离性假设用户想同时修改多个对象 (行, 文档, 记录), 需要 多对象事务 保持多块数据保持同步.
Serializable isolation means that the database guarantees that transactions have the same effect as if they ran serially (i.e., one at a time, without any concurrency). 可串行的隔离有损性能, 因此很多数据库选择更弱的隔离级别.
两个保证
Implementing read committed
Most commonly, databases prevent dirty writes by using row-level locks.
How do we prevent dirty reads? The approach of requiring read locks does not work well in practice, because one long-running write transaction can force many read-only transactions to wait until the long-running transaction has completed. 所以大多数数据库都会记住旧值和由当前持有写入锁的事务设置的新值, 在事务提前只能读到旧值.
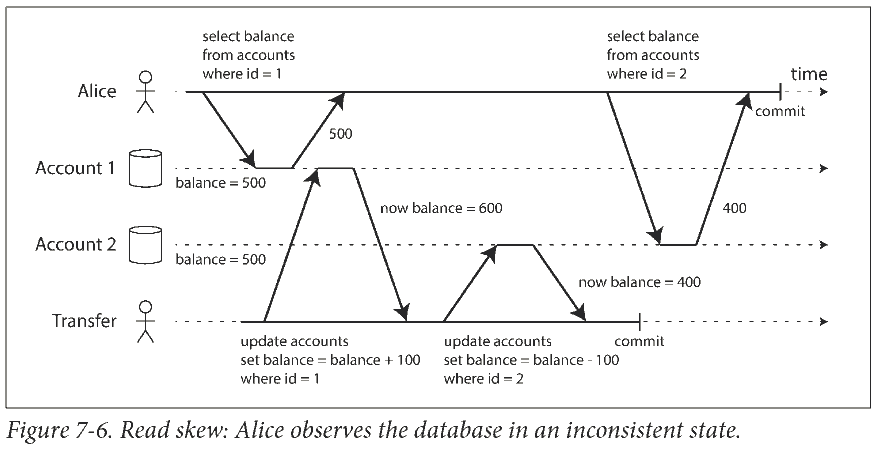
在读已提交的隔离条件下, 可能出现不可重复读 (nonrepeatable read) 或者称为读取偏差 (read skew).
Snapshot isolation is the most common solution to this problem. The idea is that each transaction reads from a consistent snapshot of the database—that is, the transaction sees all the data that was committed in the database at the start of the transaction.
Implementing snapshot isolation
同样地, 用写锁防止脏写. 但是读取不需要锁. 从性能来看, 快照隔离的关键原则是: 读不阻塞写, 写不阻塞读.
数据库需要同时维护单个对象的多个版本, 这种技术称为多版本并发控制 (MVCC, multi-version concurrency control).
Snapshot isolation is a useful isolation level, especially for read-only transactions. However, many databases that implement it call it by different names. In Oracle it is called serializable, and in PostgreSQL and MySQL it is called repeatable read.
The reason for this naming confusion is that the SQL standard doesn't have the concept of snapshot isolation at that time. To make matters worse, the SQL standard's definition of isolation levels is flawed—it is ambiguous, imprecise. Even though several databases implement repeatable read, there are big differences in the guarantees they actually provide.
Example: two concurrent counter increments
接最后一点. A common approach in such replicated databases is to allow concurrent writes to create several conflicting versions of a value, and to use application code or special data structures to resolve and merge these versions after the fact.
Atomic operations can work well in a replicated context. On the other hand, the last write wins (LWW) conflict resolution method is prone to lost updates. Unfortunately, LWW is the default in many replicated databases.
例子: 两个人值班, 只要有一个人在岗另一个人就能请假. 当两个人同时决定请假时 (两个并发事务), 从快照读到两个人都在岗, 因此批准了两人请假, 结果没人值班了. 另外比如预定会议室的场景. 快照隔离级别不能防止这种问题.
This anomaly is called write skew. The anomalous behavior was only possible because the transactions ran concurrently. Write skew can occur if two transactions read the same objects, and then update some of those objects (different transactions may update different objects).
Phantoms causing write skew
All of these examples follow a similar pattern:
This effect, where a write in one transaction changes the result of a search query in another transaction, is called a phantom (幻读). Snapshot isolation avoids phantoms in read-only queries.
Serializable isolation is usually regarded as the strongest isolation level. It guarantees that even though transactions may execute in parallel, the end result is the same as if they had executed one at a time, serially, without any concurrency.
Most databases that provide serializability today use one of three techniques as disscussed below.
完全去掉并发, 单线程顺序执行. Serial execution of transactions has become a viable way of achieving serializable isolation within certain constraints:
比普通的写锁要求更严格. Several transactions are allowed to concurrently read the same object as long as nobody is writing to it. But as soon as anyone wants to write (modify or delete) an object, exclusive access is required:
最大问题是性能差: 写入会阻塞其他读写, 读取也会阻塞写入. 这和快照隔离的要求截然相反.
两阶段意思是, 第一阶段 (事务执行时) 获取锁, 第二阶段 (事务结束时) 释放锁.
略
We will now turn our pessimism to the maximum and assume that anything that can go wrong will go wrong.
In a distributed system, there may well be some parts of the system that are broken in some unpredictable way, even though other parts of the system are working fine. This is known as a partial failure. The difficulty is that partial failures are nondeterministic: if you try to do anything involving multiple nodes and the network, it may sometimes work and sometimes unpredictably fail. As we shall see, you may not even know whether something succeeded or not, as the time it takes for a message to travel across a network is also nondeterministic!
We need to build a reliable system from unreliable components. 比如互联网协议 (IP) 不可靠, 但是 TCP 在 IP 之上提供了更可靠的传输层.
The distributed systems we focus on in this book are shared-nothing systems: i.e., a bunch of machines connected by a network. The network is the only way those machines can communicate.
The internet and most internal networks in datacenters (often Ethernet) are asynchronous packet networks. In this kind of network, one node can send a message (a packet) to another node, but the network gives no guarantees as to when it will arrive, or whether it will arrive at all.
The usual way of handling this issue is a timeout: after some time you give up waiting and assume that the response is not going to arrive.
Each machine on the network has its own clock, which is an actual hardware device: usually a quartz crystal oscillator. It is possible to synchronize clocks to some degree: the most commonly used mechanism is the Network Time Protocol (NTP), which allows the computer clock to be adjusted according to the time reported by a group of servers. The servers in turn get their time from a more accurate time source, such as a GPS receiver.
Monotonic Versus Time-of-Day Clocks
A time-of-day clock does what you intuitively expect of a clock: it returns the current date and time according to some calendar (also known as wall-clock time).
Time-of-day clocks are usually synchronized with NTP. If the local clock is too far ahead of the NTP server, it may be forcibly reset and appear to jump back to a previous point in time. These jumps, as well as the fact that they often ignore leap seconds (闰秒), make time-of-day clocks unsuitable for measuring elapsed time.
A monotonic clock is suitable for measuring a duration (time interval), such as a timeout or a service's response time. The name comes from the fact that they are guaranteed to always move forward. However, the absolute value of the clock is meaningless. 比 NTP 时间快或慢时, 会微调单调时钟的速度.
时钟读数不是准确值, 存在置信区间.

Many distributed algorithms rely on a quorum, that is, voting among the nodes: decisions require some minimum number of votes from several nodes in order to reduce the dependence on any one particular node.
The leader and the lock
Frequently, a system requires there to be only one of some thing.
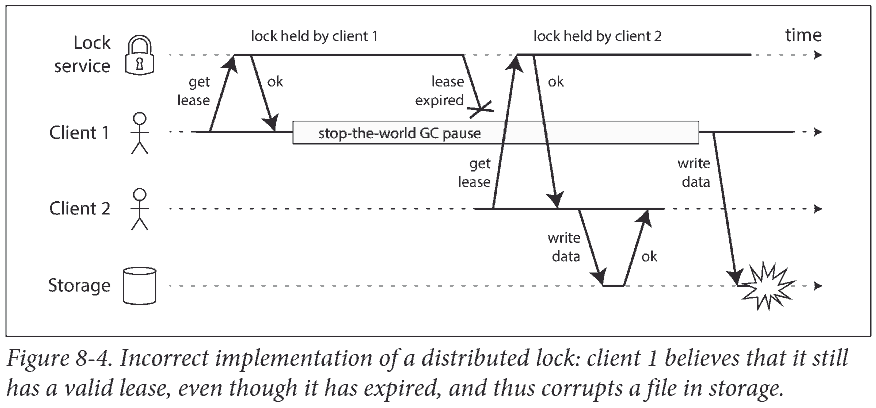
上图中 Client 1 由于 stop-the-world garbage collector (有时候 GC 需要停止所有运行的线程) 停止了一段时间, 回来后依然以为自己持有锁 (需要等下次检测才知道锁没了), 结果执行了不安全的写入.
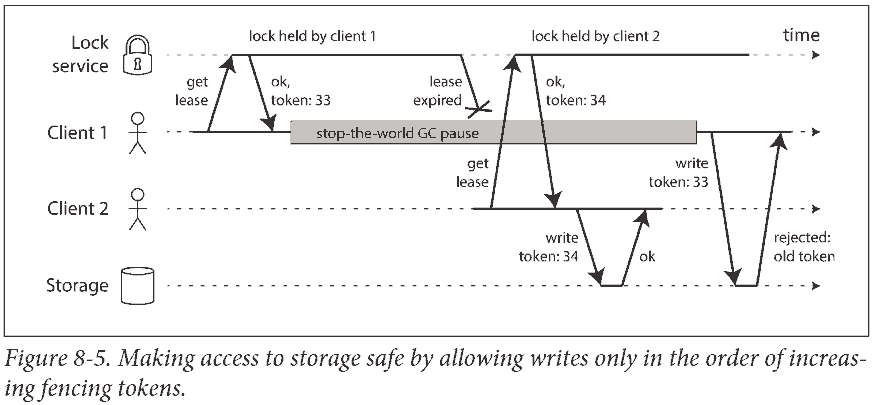
Fencing tokens
One of the most important abstractions for distributed systems is consensus: that is, getting all of the nodes to agree on something.
最终一致性一个更好的名字可能是收敛 (convergence). 这是很弱的保证, 没有说什么时候收敛.
The basic idea is to make a system appear as if there were only one copy of the data, and all operations on it are atomic.
This is the idea behind linearizability (线性一致性) (also known as atomic consistency, strong consistency (强一致性), immediate consistency, or external consistency).
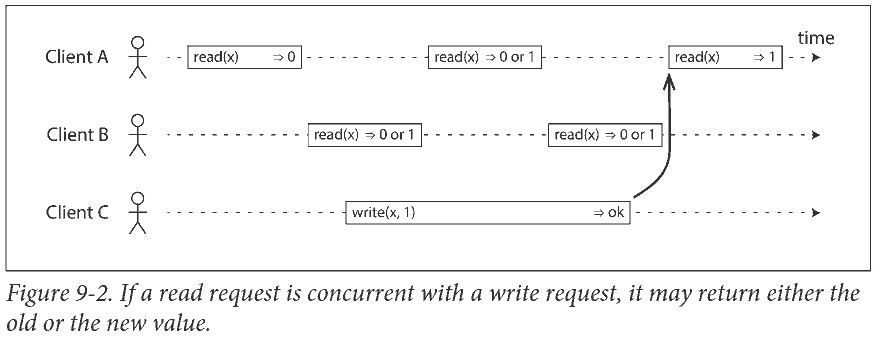
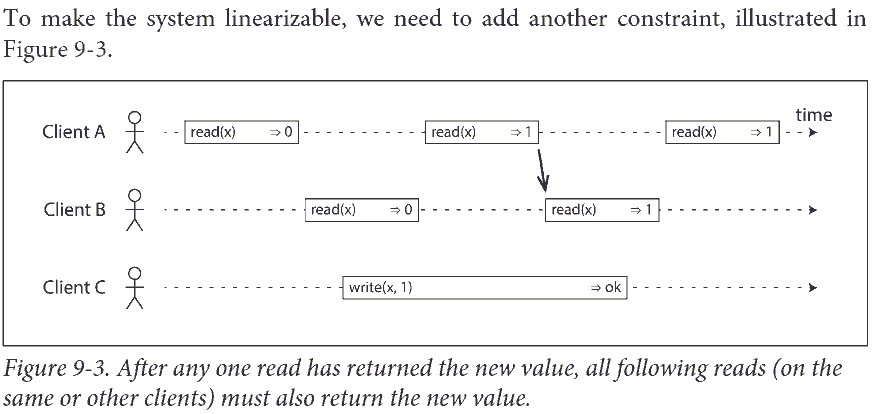
矩形左边是请求发送时刻, 右边是客户端收到响应的时刻.
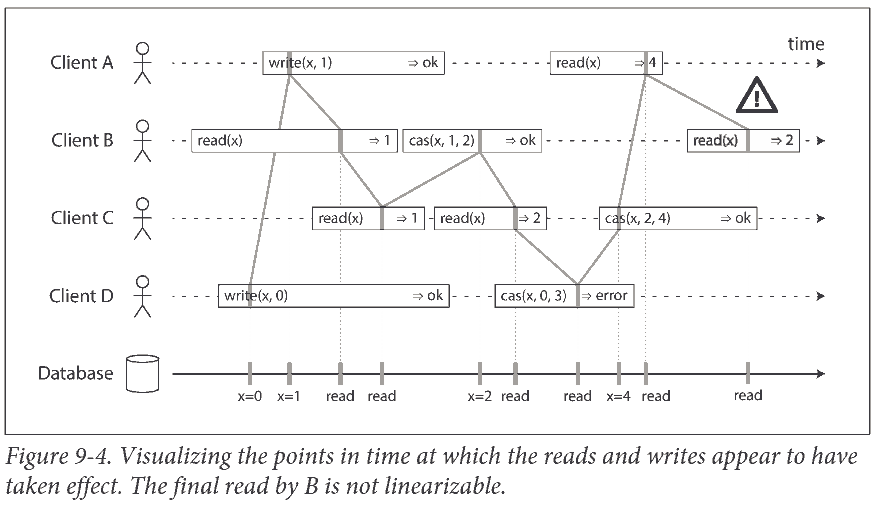
Locking and leader election
单主复制的系统要保证主库只有一个. 一种选举主库的方式是用锁: 每个节点启动时尝试获取锁, 成功者称为主库. 锁必须强一致: 所有节点必须就哪个节点拥有锁达成一致.
Constraints and uniqueness guarantees
唯一性约束在数据库很常见: 比如用户名或电子邮件地址. 如果要在写入数据时执行此约束, 则需要强一致性.
Cross-channel timing dependencies
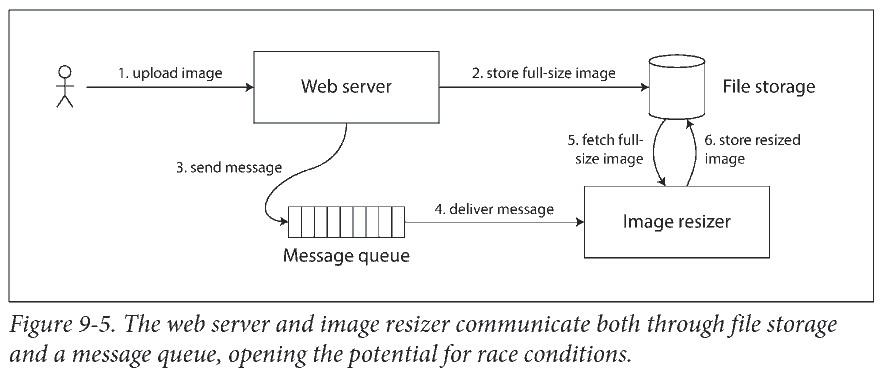
用户传图看缩略图. 如果文件存储服务不是强一直的, 缩小图片的指令 (上图 3 和 4) 可能比图片存储快 (上图 2), image resizer 可能看到 (上图 5) 图片的旧版, 生成旧版缩略图.
The CAP theorem
Thus, applications that don't require linearizability can be more tolerant of network problems. This insight is popularly known as the CAP theorem. CAP was originally proposed as a rule of thumb, without precise definitions, with the goal of starting a discussion about trade-offs in databases.
CAP is sometimes presented as Consistency, Availability, Partition tolerance: pick 2 out of 3. Unfortunately, putting it this way is misleading because network partitions (where nodes that are alive but disconnected from each other) are a kind of fault, so they aren't something about which you have a choice: they will happen whether you like it or not.
At times when the network is working correctly, a system can provide both consistency (linearizability) and total availability. When a network fault occurs, you have to choose between either linearizability or total availability. Thus, a better way of phrasing CAP would be either Consistent or Available when Partitioned.
In discussions of CAP there are several contradictory definitions of the term availability. All in all, there is a lot of misunderstanding and confusion around CAP, and it does not help us understand systems better, so CAP is best avoided.
There are many more interesting impossibility results in distributed systems, and CAP has now been superseded by more precise results, so it is of mostly historical interest today.
Linearizability and network delays
Although linearizability is a useful guarantee, surprisingly few systems are actually linearizable in practice. For example, even RAM on a modern multi-core CPU is not linearizable.
The same is true of many distributed databases that choose not to provide linearizable guarantees: they do so primarily to increase performance, not so much for fault tolerance.
The causal order is not a total order. 因果顺序不是全序.
Linearizability is stronger than causal consistency
许多情况下, 看上去需要线性一致性的系统实际只需要因果一致性.
Although causality is an important theoretical concept, actually keeping track of all causal dependencies can become impractical. There is a better way: we can use sequence numbers or timestamps to order events. A timestamp can come from a logical clock, which is an algorithm to generate a sequence of numbers to identify operations, typically using counters that are incremented for every operation.
Lamport timestamps
There is actually a simple method for generating sequence numbers that is consistent with causality.
Each node has a unique identifier, and each node keeps a counter of the number of operations it has processed. The Lamport timestamp is then simply a pair of (counter, node ID).
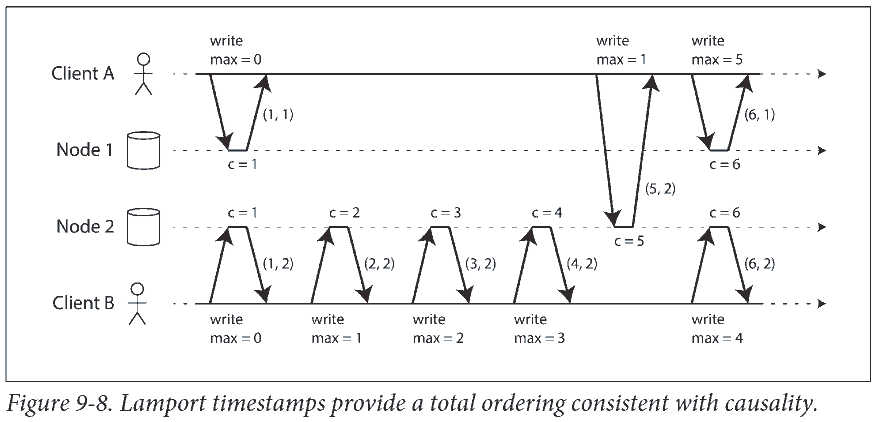
A Lamport timestamp bears no relationship to a physical time-of-day clock, but it provides total ordering: if you have two timestamps, the one with a greater counter value is the greater timestamp; if the counter values are the same, the one with the greater node ID is the greater timestamp.
The key idea about Lamport timestamps, which makes them consistent with causality, is the following: every node and every client keeps track of the maximum counter value it has seen so far, and includes that maximum on every request. When a node receives a request or response with a maximum counter value greater than its own counter value, it immediately increases its own counter to that maximum.
Timestamp ordering is not sufficient
The problem is that the total order of operations only emerges after you have collected all of the operations. If another node has generated some operations, but you don't yet know what they are, you cannot construct the final ordering of operations. 比如一个操作需要马上响应 (两个人同时注册相同用户名), 但是我们无法马上知道它在全序操作中到底排在哪里 (到底谁先注册). It's not sufficient to have a total ordering of operations—you also need to know when that order is finalized.
Single-leader replication determines a total order of operations by choosing one node as the leader and sequencing all operations on a single CPU core on the leader. The challenge then is how to scale the system if the throughput is greater than a single leader can handle, and also how to handle failover if the leader fails. In the distributed systems literature, this problem is known as total order broadcast or atomic broadcast.
Informally, it requires that two safety properties always be satisfied:
Atomic commit: In a database that supports transactions spanning several nodes or partitions, we have the problem that a transaction may fail on some nodes but succeed on others. If we want to maintain transaction atomicity, we have to get all nodes to agree on the outcome of the transaction: either they all abort/roll back or they all commit.
In particular, we will discuss the two-phase commit (2PC) algorithm, which is the most common way of solving atomic commit and which is implemented in various databases, messaging systems, and application servers. It turns out that 2PC is a kind of consensus algorithm—but not a very good one. By learning from 2PC we will then work our way toward better consensus algorithms, such as those used in ZooKeeper.
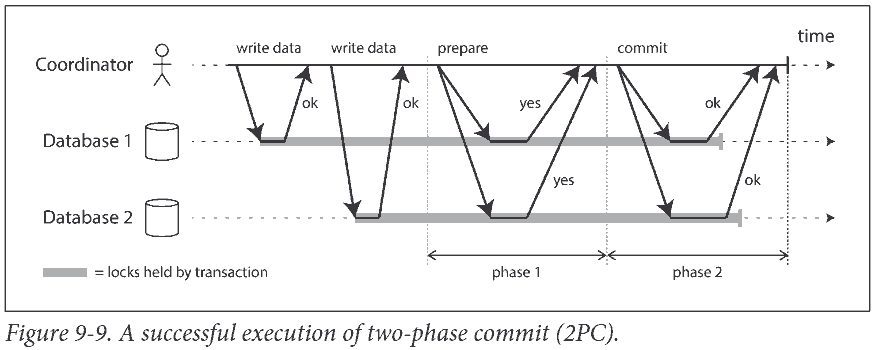
2PC uses a new component that does not normally appear in single-node transactions: a coordinator (also known as transaction manager).
We call these database nodes participants in the transaction. When the application is ready to commit, the coordinator begins phase 1: it sends a prepare request to each of the nodes, asking them whether they are able to commit. The coordinator then tracks the responses from the participants:
A system of promises
From this short description it might not be clear why two-phase commit ensures atomicity, while one-phase commit across several nodes does not.
Three-phase commit
Two-phase commit is called a blocking atomic commit protocol due to the fact that 2PC can become stuck waiting for the coordinator to recover.
As an alternative to 2PC, an algorithm called three-phase commit (3PC) has been proposed. However, 3PC assumes a network with bounded delay and nodes with bounded response times. 不实际
Distributed transactions in MySQL are reported to be over 10 times slower than single-node transactions, so it is not surprising when people advise against using them. Much of the performance cost inherent in two-phase commit is due to the additional disk forcing (fsync) that is required for crash recovery, and the additional network round-trips.
Two quite different types of distributed transactions are often conflated:
Informally, consensus means getting several nodes to agree on something. The consensus problem is normally formalized as follows: one or more nodes may propose values, and the consensus algorithm decides on one of those values.
要求
The uniform agreement and integrity properties define the core idea of consensus: everyone decides on the same outcome, and once you have decided, you cannot change your mind.
其他略.