2025 年大家都忙着开发 agent, 这里简要回顾一下 RAG.
RAG 基本操作
- Offline: 文件解析, 文本切片, embedding (以前通常用 bge)
- 对 query embedding 后做召回 (通常就算个 cos, chunk 量大时用向量数据库牺牲一定精度加速召回)
- Rerank (通常是 bge-reranker)
这套早在 2023 年就玩烂了.
<!-- more -->
Advanced RAG
Offline
文本切片优化
- 按照语义切分: 想法是, 先得到句子 embedding, 若相邻句子 embedding 距离较大 (比如可以统计分位数取阈值), 则认为语义差别大, 在这里切分.
- 按结构切分: 比如根据 markdown 的标题层级, 图表, 代码等, 保证有意义的结构不被切开. 这里可以把 chunk 所属的标题放在其 metadata 里或者直接拼在 chunk 开头; 或者用 LLM 总结 chunk 生成一个 heading 拼上去.
- 还有很多雕花级别的操作, 可以参考这些 2023 年的 RAG 比赛, B 站上也有答辩视频.
Embedding 优化
给每个 chunk 生成更多 "维度" 的 embedding. 比如对当前 chunk 做个总结得到 embedding, 或者把当前 chunk 对应的 window 更大的 chunk 或者段落以及章节层级拿来做 embedding (甚至是层次化的 embedding 以及召回). 命中 embedding 之后可以连带地在当前 chunk 前后扩展一定 window 或者段落带出更完整连贯的上下文.
Online
Query 处理

- Query 分类 (意图识别/路由等)
- 生成更多维度 embedding: 比如 HyDE (Hypothetical Document Embedding), 根据 query 生成伪文档再去召回, 把 qa 匹配变成 aa 匹配. 类似地, 离线时可以对每个 chunk 生成可能的 query, 把 qa 匹配变成 qq 匹配.
拼接上下文
- 扩大窗口 (之前讲过了, 带出当前 chunk 对应的 window 更大的 chunk)
- 顺序 (如果 chunk 来自同一篇文档, 按文中出现的顺序排序, 离得近可以补充一些 gap 等让段落更连贯)
- 根据层级 (之前讲过了, 带出当前 chunk 对应的章节)
- 压缩 (还是靠 LLM 搞)
评估
- 召回评估
- 效果指标: recall@k, precision@k, mAP, mrr 等, 可以参考 这里
- 性能指标: 平均响应时间, QPS 承载能力, 可用性/节点故障恢复时间
- 成本指标: 单位向量存储成本, 单位检索成本
- 在线评估: 检索结果点击率 (CTR), 停留时间 (查看检索结果的时间), 二次检索率 (看了结果后再次检索的比例, 越低越好), 用户满意度评分
- 生成评估
- 效果指标: 事实准确率 (回答与检索信息一致), 幻觉率 (回答包含检索信息外内容的比例), 格式符合度, 用户满意度
- 性能指标: 首 token 时间, QPS, 可用性
- 成本指标: 单位请求成本 (GPU 资源成本), GPU 利用率
Graph RAG
参考 LightRAG 以及微软的 GraphRAG, 宣传中 Graph RAG 能做这两件事情 (1) 回答全局问题, 比如总结全书; (2) 回答多跳问题.
其中第一点我的理解是, Graph RAG 相当于做了层级 (图的层级聚类) 的摘要, 越往上层级就是摘要的摘要, 所以所谓的能解决全局问题其实是提前通过摘要的摘要把回答准备好了.
至于第二点, 我的理解是不如 agentic RAG. Graph RAG 企图通过图关系, 一步 (虽然后续也有工作是多步迭代式召回) 把多跳关系找全, 很难做好. 构建图谱就不是 trivial 的事情, 光是定义什么东西算个结点都不容易, 实体 (结点) 链接与消歧也不容易. 而召回时需要利用图谱的边, 实际上需要 "预先知道要利用到这类边", 构图时才能构出来. 构图过程的计算量和存储需求都很大, 后续更新也很难做. 图的构建说到底还是看 LLM 本身能力. 而 agentic rag 允许多次检索, 同样是依赖 LLM 本身能力, 但不需要预先对知识库构建图谱 (所以能直接用上 web search 等更通用的能力). 行动机制上更像人, 也更容易 scaling. 另外可以见 你为什么要用 GraphRAG?
那图谱到底有什么用? 我的理解是可以通过图谱构建 agent 训练数据, 比如 web sailor.
Agentic RAG
其实就是让 LLM 自己取做判断, 比如: 召回文档是否相关? 够不够解决问题? 这个回答有没有乱编? 等等. 一个比较典型的应用是 deep research, 具体就要开另一篇博客了.
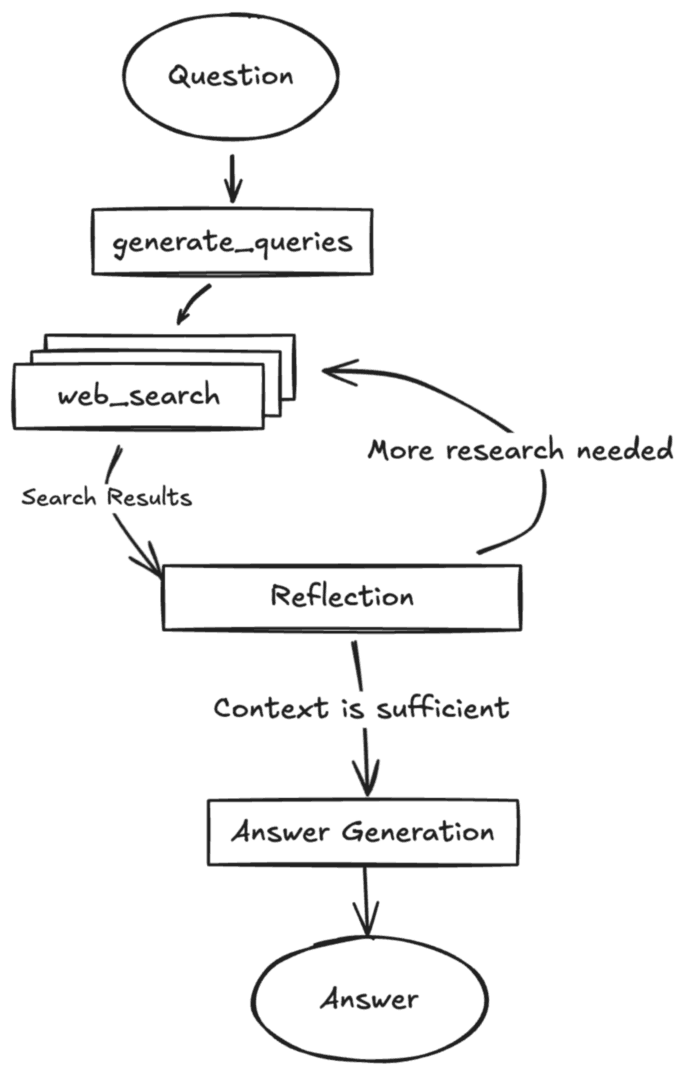
其他
备用资料