衍生项目
<!-- more -->
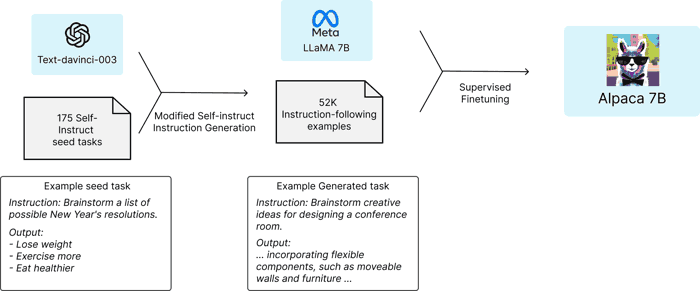
在 Meta LLaMA-7B 上用 52k 个 instruction 数据微调得到 Alpaca-7B.
这些数据通过 self-instruct 的方法, 调用 chatGPT 接口 (text-davinci-003), 由 175 个种子任务 (开源的人工生成的数据) 扩展而成. 每次从现有任务池中抽样三个作为示例, 再让 GPT 扩展到二十个; 然后用 rouge score 判别扩展样例和原有样例的差别, 舍弃太接近的扩展样例, 以此获得多样的训练数据.
<details><summary><b>调用 prompt</b><font color="deepskyblue"> (Show more »)</font></summary> <pre><code>You are asked to come up with a set of 20 diverse task instructions. These task instructions will be given to a GPT model and we will evaluate the GPT model for completing the instructions.
Here are the requirements:
List of 20 tasks:
生成的每条数据有三个字段
[
{
"instruction": "Identify the odd one out.",
"input": "Twitter, Instagram, Telegram",
"output": "Telegram"
},
{
"instruction": "What are the three primary colors?",
"input": "",
"output": "The three primary colors are red, blue, and yellow."
},
...
]
训练时每条数据会拼接成一个字符串
PROMPT_DICT = {
"prompt_input": (
"Below is an instruction that describes a task, paired with an input that provides further context. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:"
),
"prompt_no_input": (
"Below is an instruction that describes a task. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Response:"
),
}
原始 alpaca 语料主要为英文. 可参考 japanese-alpaca-lora 的代码, 用 Chinese-alpaca-lora 的数据微调 (因为 chinese 训练代码还没开源). 这两个衍生项目参考了 alpaca-lora, 用 chatGPT 翻译 alpaca 的数据后用来微调.
代码封装成了标准的 huggingface Trainer, 用起来很简单.
<details><summary><b>注意 LLaMATokenizer 和 LlamaTokenizer 两个不同的版本</b><font color="deepskyblue"> (Show more »)</font></summary> <p>LL 开头的版本出自 transformers 4.27 的一个开发版本, 权重可取 <code>decapoda-research/llama-7b-hf</code>. 而 Ll 开头的版本出自 transformers 4.28, 其中 4.28.1 有代码改动, 权重可取 <code>huggyllama/llama-7b</code>. </p> <p>参考 <a href="https://github.com/huggingface/transformers/issues/22738">issue#22738</a></p></details>
需要注意的是 japanese 的项目写得很简陋, 也没考虑并行训练等问题; alpaca-lora 详细得多.
参考 lora 项目修改
model = LlamaForCausalLM.from_pretrained(
...
device_map={"": int(os.environ.get("LOCAL_RANK") or 0)},
)
然后
WORLD_SIZE=2 CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node=2 finetune.py &
如果用 nohup, 由于 ddp 的 bug, 退出 terminal 时要用 exit, 否则会终止程序.
参考
ymcui/Chinese-LLaMA-Alpaca 扩展了中文词表, 并增加了中文语料预训练, 以获得更好的中文表现. Wiki 里有很多值得参考的信息.
200B~1T tokens
LLaMA: Although Hoffmann et al. (2022) recommends training a 10B model on 200B tokens, we find that the performance of a 7B model continues to improve even after 1T tokens.
BloombergGPT: 50B params, 700B tokens. 根据 scaling law 最优应该 1.1T tokens, 但是他们根据 GPU 预算, 预留了 30% 算力用来处理 unforeseen failures, retries, and restarts.
LLaMA: A100-80GB, 1.0T tokens, 3e-4 lr, 4M batch_size
| | GPU-hours | | --------- | ---------------------- | | LLaMA-7B | 82,432 (四卡 859 天) | | LLaMA-13B | 135,168 (四卡 1408 天) |
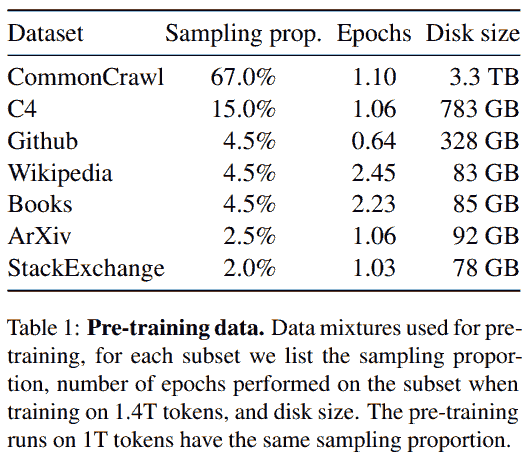
LLaMA: For most of our training data, each token is used only once during training, with the exception of the Wikipedia and Books domains, over which we perform approximately two epochs.
LLaMA: When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM. This means that training over our dataset containing 1.4T tokens takes approximately 21 days.
LLaMA: We make several optimizations to improve the training speed of our models.
- First, we use an efficient implementation of the causal multi-head attention to reduce memory usage and runtime.
- We reduced the amount of activations that are recomputed during the backward pass with checkpointing.
- We also overlap the computation of activations and the communication between GPUs over the network (due to all_reduce operations) as much as possible.
另外可参考 训练细节 · ymcui/Chinese-LLaMA-Alpaca Wiki,
继续预训练中文通用语料, 只训练少部分参数
| 实验设置 | 预训练-第一阶段 | 预训练-第二阶段 | 指令精调 | | :----------------------- | :--------------: | :--------------: | :--------------: | | Batch Size | 1024 | 1024 | 512 | | Initial Learning Rate | 2e-4 | 1e-4 | 1e-4 | | Training Steps | 3K | 6K | 6K-10K | | Max Length | 512 | 512 | 512 | | Trainable Parameters (%) | 2.97% | 6.06% | 6.22% | | Training Device | 8 × A100 | 16 × A100 | 16 × A100 | | Distributed Training | DeepSpeed Zero-2 | DeepSpeed Zero-2 | DeepSpeed Zero-2 |
[Pretraining] 32x A100-40G GPU, 2e-4 lr, 3072 batch_size, 1w steps
[Finetuning] 2e-5 lr, 2k steps