COLING 2020 的文章
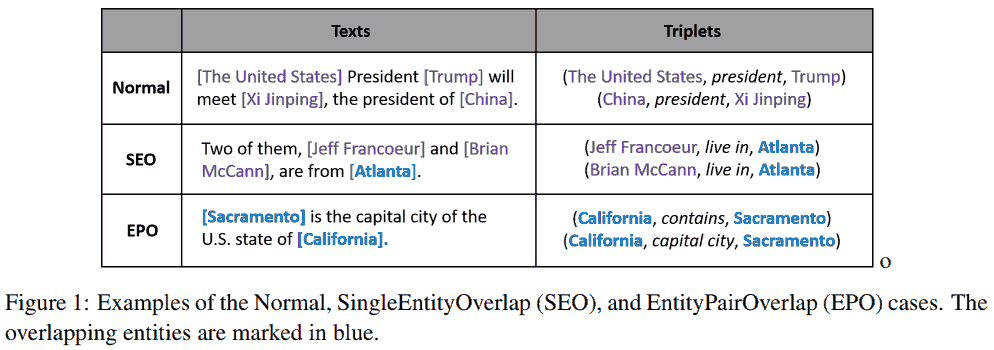
实体关系抽取传统方法先抽取实体, 再预测实体对的关系 (分类问题). 这种两阶段方法无法考虑两个子任务之间的联系. 因此引入联合 (joint) 抽取, 即同时抽取实体和关系. 此外还要解决实体重叠问题 (同一个实体出现在多个三元组中).
大多数现有处理实体对重叠 (EntityPairOverlap, EPO) 和单实体重叠 (SingleEntiyOverlap, SEO) 的方法可分为两类:
这些方法有共同的问题: 曝光偏差 (exposure bias). 编码器-解码器在训练阶段用了真实数据的 tokens, 但推理阶段用的是模型自己生成的 tokens. 因此训练和推理阶段用的数据来自不同分布. 基于分解的模型也有类似问题.
个人评价: 充其量是包装论文用的说法.
TPLinker 是一个单阶段方法, 将联合抽取任务转化为 Token Pair Linking 问题.
TPLinker 其实非常简单粗暴, 标题就概括了它的方法: token pairs 的分类问题. 长度为 $n$ tokens 的序列中有顺序地取两个 tokens (可以取相同的), 记为 $p_1$ 和 $p_2$, 称为一个 token pair, 一共有 $n^2$ 个 token pairs. 对于每个 token pair 和每个关系 $r$, TPLinker 做三个独立的分类任务:
几乎把所有的情况枚举了一遍, 当然理念上可以解决实体重叠问题.
极其简单且无关紧要的细节, 把上述过程用矩阵表示, 其中 $n^2$ 个 token pairs 可以用 $n(n+1)/2$ 个数表示.
在矩阵中用 1 存储上述标签, 不同标签用不同矩阵.
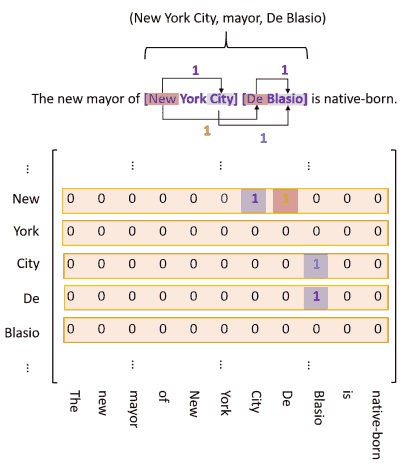
由于实体的尾部必然在头部后面, 所以对第一类标签, 矩阵左下三角都是 0, 可以舍去以节约内存. 而对另外两类标签, 宾语可能出现在主语前, 所以不能直接舍去矩阵左下角. 办法是把左下角的 1 翻到右上角, 存储为 2, 再把左下角舍去. 最后把矩阵摊平便于计算. (作者这里兜了圈子, 直接说在所有 token 对上标注就完事了, 1 是正向, 2 是反向.)
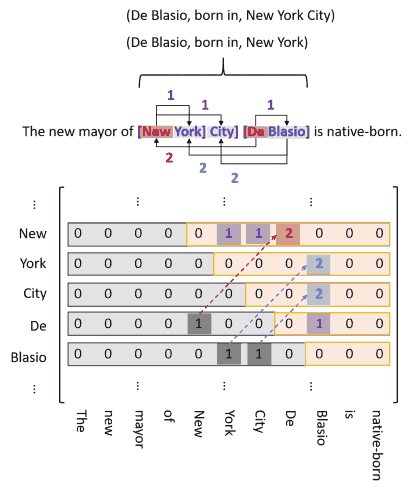
这样如上图可以自然地处理单实体重叠问题 (De Blasio 出现在两个三元组中). 为了解决实体对重叠问题, 需要对每一个关系都做序列标注. 如果有 $R$ 个关系, 就要做 $2R + 1$ 次序列标注 (第一类标签不涉及关系, 可以共用), 每个子任务生成长度为 $n(n+1)/2$ 的序列 (所有可能的 token pair 数), 其中 $n$ 为输入序列长度.
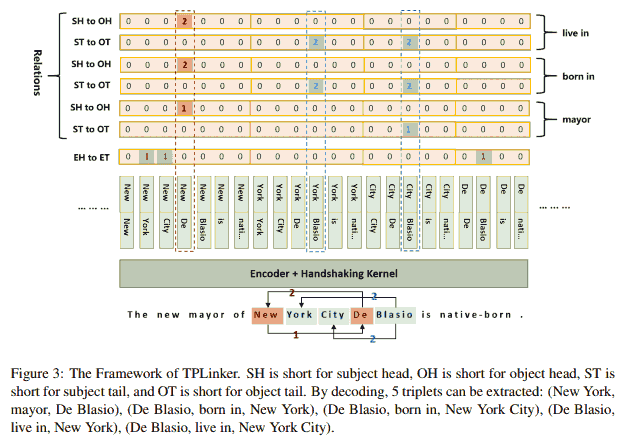
It seems that our tagging scheme is extremely inefficient because the length of the tagging sequence increases in a square number with increasing sentence length. Fortunately, our experiment reveals that by utilizing a lightweight tagging model on the top of the encoder, TPLinker can achieve competitive running efficiency compared with the state-of-the-art model, since the encoder is shared by all taggers (see Figure 3) and only needs to generate $n$ token representations for once.
BERT 是开销大头, 这个组件不影响速度.
The sequence is like the handshaking of all tokens, which is the reason why we refer to this scheme as the handshaking tagging scheme.
至少这个命名理由没有说服我. 下面是作者没有提及到的问题: 构造一个反例说明这个方案会出错的情况.
对于句子 ABCDEF, 三元组为 (AB, EF) 和 (ABC, DEF) 两个 (省略谓语, 只写主语宾语).
实际上这种情况应该比较少, 而且最终是除了正确的三元组还会抽取多余的三元组.
顺便一提, 对于一篇 EMNLP 2021 文章
他主要是对 TPLinker 的基础上增加关于 relations 和 token pairs 的 "全局" 表格特征, 并相应提出了新的 tagging scheme (略), 它不能处理的情况如下
这个方案可能抽取出错误的三元组或者少抽.
分类问题的标准流程.
对一个长度为 $n$ 的句子 $[w_1, \dots, w_n]$, 先用 encoder 把每个 token $w_i$ 映射为向量 $c_i$, 然后用通常方法 (拼接输入向量, 线性变换后接激活函数) 生成 token pair $(w_i, w_j)$ 的表示
$$ h_{i, j} = \operatorname{tanh}\left(W_h [c_i, c_j] + b_h\right), \quad j\ge i, $$
其中 $W_h$ 和 $b_h$ 是训练参数.
之后是分类问题的通常方法 (线性变换后接 softmax 得到概率分布预测) 生成这个 token pair 的 link label (0, 1, 2) 的概率预测
$$ Y_{i,j} \sim \operatorname{softmax}(Wo h{i, j} + b_o). $$
上述操作对每个子任务都做一遍. 损失函数为对数极大似然
$$ L = - \frac1n \sum{t\in T} \sum{i=1}^n \sum{j\ge i}^n \log \mathbb P(Y^{(t)}{i, j} = l^{(t)}), $$
其中 $T$ 是序列标注全体子任务, $l^{(t)}$ 是对应子任务的真实 link label (0, 1, 2).
预测
$$ \operatorname{link}(w_i, w_j, t) = \operatorname{arg\,max}l \mathbb P(Y^{(t)}{i, j} = l). $$
可以看到他把长度为 $n$ 的序列展成了 $\Theta(n^2)$ 的东西, 所以长度不能太大, 作者推荐不超过 100. 另外可以看到, 展开后这么长的序列里, 非 0 值很少, 矩阵非常稀疏.
对于超过最大长度的序列, 他的处理是, 用 sliding window 截取. 比如最大长度为 100, 每次划窗移动距离为 20, 则先取头 100 个 tokens 作为一个序列, 再取第 21~120 个 tokens 作为新的序列 (有关的实体关系对也要相应处理), 以此类推.
由于 TPLinker 做的是 token pairs 的分类, 显然它也可以做实体识别. TPLinker 是对每个 token pair 独立地做了 $2R+1$ 个分类问题, TPLinker-plus (原作者开发中的版本) 只做一个多标签分类问题, 具体参考 苏剑林的推广, 也就是把 $n$ 选 1 的分类问题变成了 $n$ 选 $k$ 的分类问题. 有人用 TPLinker-plus 的这个子功能整理出了 TPLinker-NER, 并对中文数据集 CLUENER2020 做了验证, 据称效果还行 (用同样代码我还没复现出).
从发布时间上看, 他应该直接参考了苏剑林的 GlobalPointer, 用同样的数据集验证, 但好像没有实现后者的一些优化.