首先讲点背景。我平时从网易云音乐的Arcaea (韵律源点) 主播电台下一些音乐,用音乐标签修正封面、专辑、作者、文件名等信息。但在标题含带音符的拉丁文小写字母(比如Dynitikǒs)的时候,专辑Arcaea (韵律源点)就会显示为Arcaea (韵律æº�点)这样的乱码,但在删掉音符后就正常了。在我印象里ID3v2是有记录文本编码的区域的,于是就想去看看这个bug根源在哪里。
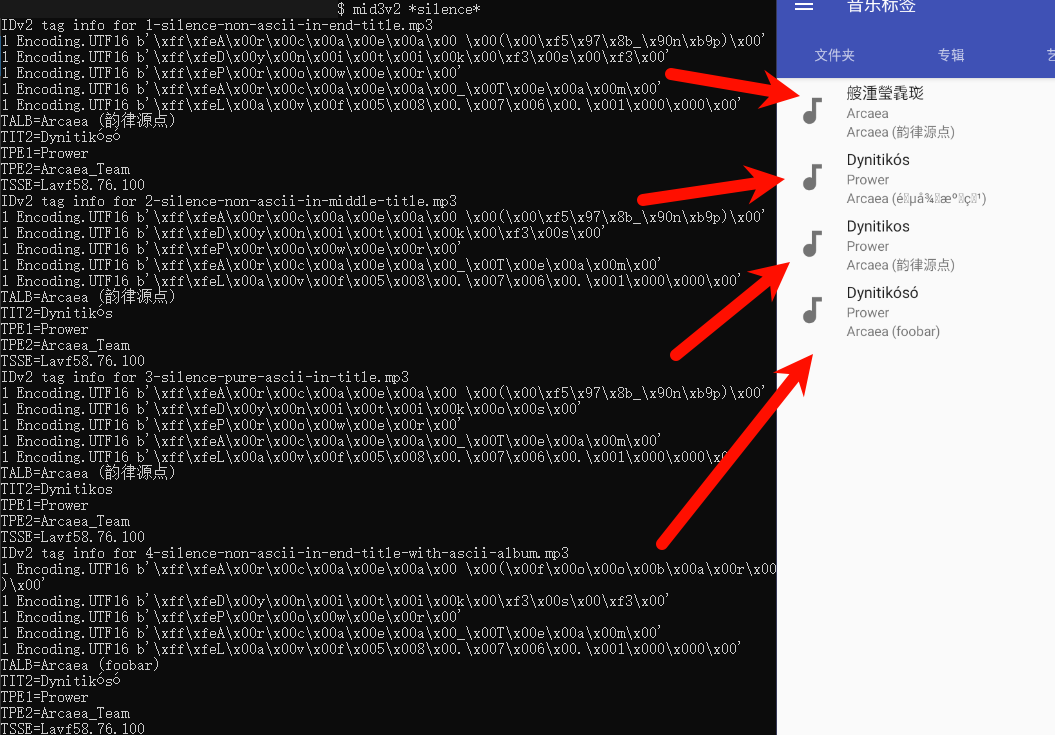
这个bug还有一些更离奇的变种,即改变某个标签中的字符位置也可能改变另一个标签的读取编码,如图所示。
首先打开在线乱码恢复,可以看到这个乱码出现的原因是将UTF-8字节序列以Windows-1252或者ISO-8859-1读取。
然后安装python-mutagen和eyeD3(如果只是平时简单查看的话,exiftool或ffmpeg也可以),通过mid3v2 --list-raw等命令确认现有ID3标签版本及每个标签的文本编码。我的文件中的对应标签均为UTF16,并且能被这些软件正确解析。
众所周知Android系统所有音乐是由媒体库进行索引、解析元信息的,因此查看/data/data/com.android.providers.media/databases/external.db中,发现其中的字段已经是乱码,因此我首先考虑是更底层的问题。
打开AOSPXref,搜索ID3,很容易就能找到libstagefright 中的 ID3 类。我们可以在void ID3::Iterator::getstring(String8 *id, bool otherdata)函数中看到完整的编码处理。<del>所以问题解决,本文结束</del>
然而我们可以看到一行注释:let the media scanner client figure out the real encoding,或者说这个编码位取出来并没有用于最终的编码判断,因此继续找。
这个media scanner client不就是前文说的媒体库(的扫描部分)吗?为了找到具体代码在哪里,我搜索了MEDIA_SCANNER_SCAN_FILE(也就是参考链接中给出的强制扫描媒体文件的intent),在结果里打开MediaProvider的AndroidManifest.xml,然后顺着这个BroadcastReceiver一路找下去:
MediaMetadataRetriever是在libmedia里的)libmedia目录里看一看就能见到可疑的CharacterEncodingDetector.cpp了)libmediaplayerservice,此处为Binder IPC)这里的CharacterEncodingDetector是不是看着就很可疑?很容易看得出来,这个文件结合了多个音乐标签字段进行编码识别,并通过常用字表等一系列手段提高准确率。但问题是————为啥啊?
启动Google 问题跟踪器,搜索id3 encoding charset music一类的词语,你就能找到很多相关bug。最古老的在2009年就已被汇报,而直至2024年仍有与此相关的新问题。
这是一个在AOSP中至少有十年历史的老bug,在Android 5甚至更早就已经存在。希望你能给下面这俩issue打个+1,以催促某大厂尽早修掉。
作为普通用户,你也可以在音乐标签设置的杂项 -> Id3v2中选中Id3v2.4 UTF-8,使文本以UTF-8而非UTF-16格式存储,来达到修复目的。
/system/xbin/bstk/su在Bluestacks模拟器中获得root权限)本文遵守 CC BY-NC-SA-4.0 许可协议。(不允许转载至简书或 CSDN)